







需求来源:
1.每天5点从数据库取出三个随机时间点
2.在三个时间点分别触发计算任务
3.将每次计算结果推送企业微信机器人
###想到的解决方案:
1.利用crontab定时任务取出三个时间点并解析成cron语法写入crontab中执行
2.利用python的 apscheduler模块
最终选择使用apscheduler模块的data触发器类型轻松解决了 果然很强大 特在此学习记录一下
学习一下基础知识点
1.触发器(triggers):指定触发的方式或者条件
date触发器:按指定时间只触发一次
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime,time
sched = BlockingScheduler()
def date_job():
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " date triggers")
def arg_job(text):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " date triggers "+ text)
def date_trigger():
sched.add_job(date_job, trigger='date')
sched.add_job(date_job,trigger='date', run_date="2021-08-25 18:23:10")
sched.add_job(arg_job, trigger='date', run_date=datetime.datetime(2021, 8, 25, 18, 23, 5), args=['xxx'])
sched.start()
date_trigger()
cron触发器:按指定时间循环触发
def cron_trigger():
sched.add_job(my_job,trigger='cron', hour=18, minute=30)
sched.add_job(my_job, trigger='cron', month='8', day='25', hour='18',minute='30')
sched.add_job(my_job, trigger='cron', hour='*', jitter=120)
sched.add_job(my_job,CronTrigger.from_crontab('0 0 1-15 may-aug *'))
sched.start()
interval触发器:按间隔时间循环触发
def interval_trigger():
sched.add_job(interval_job,'interval', minute=1)
sched.add_job(interval_job, 'interval',hours=2, start_date='2021-08-25 18:23:10', end_date='2021-08-25 18:50:10)
sched.add_job(interval_job, 'interval', hours=1, jitter=120)
sched.start()
2.任务存储器(job stores)
MemoryJobStore
默认的存储器,将job信息存储在内存中,故不支持持久性
RedisJobStore
测试redis持久化和动态创建定时任务
第一个程序只用来添加任务,创建完程序结束
from apscheduler.executors.pool import ThreadPoolExecutor
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
jobstores = RedisJobStore(host="xxx", port=6379, password="xxx", db=0,jobs_key="test.job")
executors = {
'default': ThreadPoolExecutor(20)
}
def interval_job(text):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " " + text)
scheduler = BackgroundScheduler(executors=executors,)
scheduler.add_jobstore(jobstores)
scheduler.add_job(interval_job, 'interval', minutes=1, id="redis_test1",args=["redis_test_1"])
scheduler.add_job(interval_job, 'interval', minutes=1, id="redis_test2",args=["redis_test_2"])
scheduler.add_job(interval_job, 'interval', minutes=1, id="redis_test3",args=["redis_test_3"])
scheduler.start()
jobs = scheduler.get_jobs()
jobs_key为的key 类型为hash,查看redis中的内容如下图  第二个程序用来执行定时任务
第二个程序用来执行定时任务
from apscheduler.executors.pool import ThreadPoolExecutor
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.redis import RedisJobStore
import datetime,time
def interval_job(text):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " " + text)
jobstores = RedisJobStore(host="10.136.15.102", port=6379, password="myredis", db=0,jobs_key="test.job")
executors = {
'default': ThreadPoolExecutor(20)
}
scheduler = BlockingScheduler(executors=executors,)
scheduler.add_jobstore(jobstores)
scheduler.start()
执行结果如下图
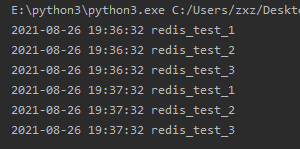
接着在第一个程序新增两个任务
scheduler.add_job(interval_job, 'interval', minutes=1, id="redis_test4",args=["增加第四个任务"])
scheduler.add_job(interval_job, 'interval', minutes=1, id="redis_test5",args=["增加第五个任务"])
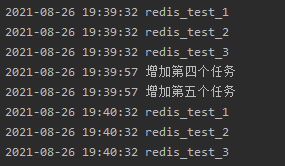
接着把redis_test1和redis_test2删掉
scheduler.remove_job("redis_test2")
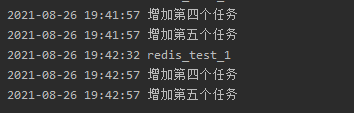
3.调度器(schedulers)
BlockingScheduler
阻塞型调度器,scheduler.start()之后阻塞程序往下执行,适用于脚本任务,当调度器是你应用中唯一 要运行的东西时使用
from apscheduler.executors.pool import ThreadPoolExecutor
from apscheduler.schedulers.blocking import BlockingScheduler
#from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
import datetime,time
def interval_job(text):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " " + text)
jobstores = RedisJobStore(host="10.136.15.102", port=6379, password="myredis", db=0,jobs_key="test.job")
executors = {
'default': ThreadPoolExecutor(20)
}
scheduler = BlockingScheduler(executors=executors,)
scheduler.add_jobstore(jobstores)
scheduler.start() #执行到这阻塞
print("阻塞型调度器,不执行")
运行结果中不会执行print语句
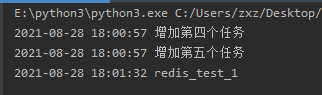
BackgroundScheduler
scheduler.start()之后可以继续往下执行代码,执行完代码进程直接结束,所以需要和一些框架一起使用,比如flask
from flask import Flask, request
from apscheduler.executors.pool import ThreadPoolExecutor
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
import datetime,time
def interval_job(text):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") + " " + text)
jobstores = RedisJobStore(host="10.136.15.102", port=6379, password="myredis", db=0,jobs_key="test.job")
executors = {
'default': ThreadPoolExecutor(20)
}
scheduler = BackgroundScheduler(executors=executors,)
scheduler.add_jobstore(jobstores)
print("加载定时任务")
scheduler.start()
app = Flask(__name__)
@app.route('/')
def add_print():
print("可以一边执行定时任务,一遍输出xxx!")
return "123"
if __name__ == '__main__':
app.run()
执行结果可以看到定时任务在后台运行,也能同时响应接口请求

4.执行器(executors)
ThreadPoolExecutor
线程执行器,默认使用线程执行器就够用了
ProcessPoolExecutor
进程执行器,适用于CPU密集型任务
最终代码
开发流程
1.每天定时5点cron定时任务触发python脚本
2.从redshift获取3个查询时间点
3.添加计算方法获取10个mysql分表的查询结果和
4.通过sched.add_job添加3个定时任务并关联计算方法
5.添加一个结束脚本的定时任务
import datetime,time
import sys
from apscheduler.schedulers.blocking import BlockingScheduler
from DBUtils.PooledDB import PooledDB
import psycopg2
import pymysql
import sys
import traceback
from concurrent.futures import ThreadPoolExecutor
import requests
sched = BlockingScheduler()
p = ThreadPoolExecutor(10)
today = datetime.datetime.now().strftime("%Y-%m-%d")
mon = datetime.datetime.now().strftime("%Y%m")
webhook_url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx"
headers = {
"Content-Type": "application/json"
}
def conncet_db():
try:
pool = PooledDB(pymysql,5,10,1,10,'true',200,host="xxx",port=60500,user="xxx",passwd="xxx",db="xxx" )
except Exception as e:
print("发生异常",e)
else:
return pool
conn = conncet_db()
def select_db(sql):
#获取链接池
db = conn.connection()
cursor = db.cursor()
try:
cursor.execute(sql)
results = cursor.fetchall()
return results
except:
traceback.print_exc()
db.rollback()
cursor.close()
db.close()
#从redshift数据库获取三个时间点
def connectPostgreSQL(sql):
conn = psycopg2.connect(database="xxx", user="xxx", password="xxxl", host="xxx", port="5439")
print('connect successful!')
cursor = conn.cursor()
cursor.execute(sql)
rows = cursor.fetchall()
res = []
for row in rows:
res.append(today +' '+ row[0])
return res
def get_time():
sql = "select p_time from rdt.rdt_scan_fct_time_point order by p_time "
time_list = connectPostgreSQL(sql)
return time_list
def my_job(text,per):
num_all = 0
for i in range(0, 10):
sql = "SELECT COUNT(1) FROM t_bottle_in_scan_records_%s_00%s WHERE scan_time>'%s'" % (mon, i, today)
num = select_db(sql)[0][0]
num_all += num
print("当前时间:",datetime.datetime.now(),"商户兑换量:",num_all,"预测当日总量:",num_all*text)
msg1 = "当前时间: %s \n商户兑换量(%s):%s \n预测当日总量:%s" % (datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),per,num_all,int(num_all*text))
data = {
"msgtype": "text",
"text": {
"content": msg1
}
}
#发送消息至企业微信机器人
res = requests.post(webhook_url, json=data, headers=headers)
print(res.text)
def xxx():
print(sched.get_jobs())
sched.shutdown(wait=False)
def xxx_job():
sched.add_job(my_job,trigger='date', run_date=at_time[0], args=[3,"1/3"])
sched.add_job(my_job,trigger='date', run_date=at_time[1], args=[2,"1/2"])
sched.add_job(my_job,trigger='date', run_date=at_time[2], args=[1.5,"2/3"])
#执行完三次计算之后在添加一个结束进程的任务
sched.add_job(xxx, trigger='date', run_date=end_time)
sched.start()
print(get_time())
at_time = get_time()
end_time = (datetime.datetime.strptime(at_time[2],"%Y-%m-%d %H:%M:%S")+datetime.timedelta(minutes=+1)).strftime("%Y-%m-%d %H:%M:%S")
xxx_job()
遇到的问题
1.date类型属于一次性任务,个人理解执行完所有任务应该会自动退出的,但是实际上三个任务执行完成后进程默认不会退出,所以在后面添加一个结束任务,时间为第三个时间点自动延后1分钟,
且在执行结束任务的时候如果方法里面只有sched.shutdown(wait=False)代码会报错,需要在shutdown之前随便加点东西才正常,这点暂时未搞懂
def xxx():
#不加这行就会报错
print(sched.get_jobs())
sched.shutdown(wait=False)
















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









