







在Java语言中,Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(具体实现接口的类)。所有抽象出来的数据结构和操作(算法)统称为Java集合框架(JavaCollectionFramework)。具体框架如下
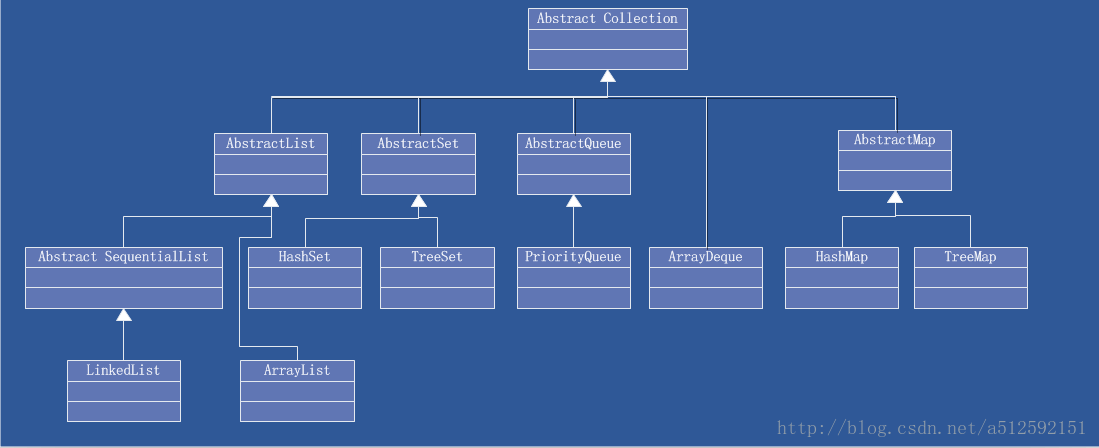
Collection和Map简介
Collection: 一个独立元素的序列,这些元素都服从一条或者多条规则,包括了Set和List。Set:不能有重复元素,检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变<对应类有 HashSet,TreeSet,LinkedHashSet>。List:必须按照插入顺序保存元素。和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。<相应类有 ArrayList,LinkedList,>
Map: 一组成对的“键值对”独享,允许使用键来查找值。也称“字典”或者“映射表”<对应类有 HashMap,TreeMap,LinkedHashMap>
初窥代码
public class PrintContainners {
// 重载了fill方法,不同的参数体现
// 容器的两种类型 collection map
// 此处使用多态,也可以体现出集合的框架。
static Collection fill(Collection<String> collection) {
collection.add("rat");
collection.add("dog");
collection.add("cat");
return collection;
}
static Map fill(Map<String, String> map) {
map.put("rat", "zheng");
map.put("dog", "yan");
map.put("cat", "livvy");
return map;
}
public static void main(String[] args) {
/*
* ArrayList LinkedList
* 相同点: 都是以插入的顺序来保存数据
* 不同点: 执行某些类型的操作的性能不同, LinkedList的操作多于ArrayList
*/
System.out.println(fill(new ArrayList<String>()));
System.out.println(fill(new LinkedList<String>()));
/*
* HashSet TreeSet LinkedHashSet
* 相同点: 每个相同的项都保存一次(通常我们只关心是否存某个数据 而不太关注它在Set的存储顺序)
* 不同点: HashSet使用哈希算法保存数据 性能最好
* TreeSet则是以 升序的顺序来保存数据
* LinkedHashSet 按照被添加的顺序保存对象
*/
System.out.println(fill(new HashSet<String>()));
System.out.println(fill(new TreeSet<String>()));
System.out.println(fill(new LinkedHashSet<String>()));
/*
* map也称为 关联数组
* map.put(key,value)
* map.get(key)
* 不同点:HashSet使用哈希算法保存数据 性能最好
* TreeSet则是以升序的发放来保存数据
* LinkedHashSet 按照被添加的顺序保存对象
*
*/
System.out.println(fill(new HashMap<String, String>()));
System.out.println(fill(new TreeMap<String, String>()));
System.out.println(fill(new LinkedHashMap<String, String>()));
}
}















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









