







准备
本文采用yum安装,并且采用国内镜像源安装,大大提高安装速度。
JDK必须安装jdk8,官方下载链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Elasticsearch7.x 清华大学开源镜像站:https://mirror.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/
开始安装
JAVA环境安装
1. 解压jdk文件
tar -zxvf jdk-8u171-linux-x64.tar.gz
2.新建安装目录,复制文件到安装目录
mkdir /usr/java
mv /var/www/jdk1.8.0_171/* /usr/java/
3.配置jdk环境变量
vim /etc/profile
末尾添加:
JAVA_HOME=/usr/java
JRE_HOME=/usr/java/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
让修改生效:
source /etc/profile
检查jdk
java -version

jdk配置完成!
Elasticsearch安装
yum安装方式Elasticsearch
1.导入Elasticsearch GPG KEY
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.添加elasticsearch的yum repo文件,使用清华的yum源镜像
默认安装最新版本,如需要指定版本,请将版本号改为指定版本号
cd /etc/yum.repos.d
vi elasticsearch7.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://mirror.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3.安装
yum install -y elasticsearch
4.配置elasticsearch
4.1 编辑vim /etc/elasticsearch/elasticsearch.yml ,注意冒号后面有个空格。
vim /etc/elasticsearch/elasticsearch.yml
单机安装请取消注释:node.name: node-1,否则无法正常启动。

4.2修改网络和端口,取消注释master节点,单机只保留一个node

4.3按需修改vim /usr/elasticsearch/config/jvm.options内存设置
vim /etc/elasticsearch/config/jvm.options
== 根据实际情况修改占用内存,默认都是1G,这里测试机是2G修改为512m,经测试,单机1G内存,设置512兆启动会占用700m+然后在安装kibana后,基本上无法运行了,运行了一会就挂了报内存不足。 内存设置超出物理内存,也会无法启动,启动报错。==
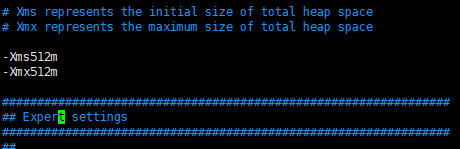
4.4修改/etc/sysctl.conf
末尾添加:vm.max_map_count=655360
vim /etc/sysctl.conf
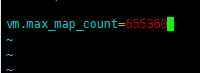
执行sysctl -p 让其生效
sysctl -p
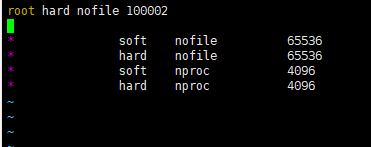
4.5修改/etc/security/limits.conf
vim /etc/security/limits.conf
末尾添加:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
4.6 启动,开机启动
systemctl start elasticsearch #启动
systemctl status elasticsearch #查看
systemctl enable elasticsearch #开机启动
systemctl stop elasticsearch #停止
4.7 配置完成:
浏览器访问测试。ip:9200
出现此页面,则一切正常

安装Kibana
安装ES时添加清华yum源中已经包含了kibana,下面直接使用yum安装即可。
1.yum安装kibana
yum install -y kibana
使用yum安装的kibana,默认安装的主目录在/usr/share/kibana中。kibana配置文件的位置为/etc/kibana/kibana.yml。
2.配置Kibana界面
修改配置文件
vim /etc/kibana/kibana.yml
修改端口,访问ip,elasticsearch服务器ip

修改为中文:

配置完成启动:
systemctl start kibana #启动
systemctl enable kibana #开机启动
systemctl status kibana #查看
systemctl stop kibana #停止
访问ip:5601,即可看到安装成功

安装Logstash
安装ES时添加清华yum源中已经包含了Logstash,下面直接使用yum安装即可。
1.yum安装Logstash
yum install -y logstash
在启动前还需要创建或修改文件/etc/sysconfig/logstash在其中加入环境变量JAVA_HOME=/usr/java
否则启动会提示failed (Result: start-limit)错误,具体原因在/var/log/messages中可以查看到:
failed (Result: start-limit)
logstash: could not find java; set JAVA_HOME or ensure java is in PATH

指定logstash环境变量
JAVA_HOME=/usr/java
2.设置Logstash导入mysql数据源
默认yum安装的Logstash的各种配置文件在/etc/logstash下,默认安装目录在/usr/share/logstash目录下
/etc/logstash/
├── conf.d
├── jvm.options
├── log4j2.properties
├── logstash-sample.conf
├── logstash.yml
├── pipelines.yml
└── startup.options
conf.d 配置文件存放目录将读取/etc/logstash/conf.d目录下所有的conf文件
jvm.options 运行内存大小配置,默认1G
2.1 安装logstash-input-jdbc插件:
cd /usr/share/logstash
./logstash-plugin install logstash-input-jdbc
2.2 下载jdbc驱动mysql-connector-java.jar:
链接:https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz
解压后:
mysql-connector-java-5.1.48-bin.jar
mysql-connector-java-5.1.48.jar
新建config目录,将上两个jar文件放置在此目录
mkdir /etc/logstash/config
2.2 配置链接数据库文件:
在/etc/logstash/conf.d/目录下新建jdbc.conf文件:
vim /etc/logstash/conf.d/jdbc.conf
#输入部分
input {
stdin {}
jdbc {
#jdbc驱动文件路径
jdbc_driver_library => "/etc/logstash/config/mysql-connector-java-5.1.48.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://ip:3306/test"
jdbc_user => "admin"
jdbc_password => "admin"
# 设置监听间隔 各字段含义(分、时、天、月、年),全部为*默认含义为每分钟更新一次
schedule => "* * * * *"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "5000"
#时区
jdbc_default_timezone =>"Asia/Shanghai"
# sql语句执行文件,路径,也可直接使用 statement => 'select * from t_employee'
#statement_filepath => "/etc/logstash/config/jdbc.sql"
#这里直接写执行语句:sql_last_value表示执行上次保存的id
statement => "select * from test where id > :sql_last_value"
# elasticsearch索引类型名
type => "type_name"
#保持大小写
lowercase_column_names => "false"
#是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 id 的值.
use_column_value => true
tracking_column => "id"
#递增字段的类型,numeric 表示数值类型, timestamp 表示时间戳类型
tracking_column_type => "numeric"
#记录上次执行结果保存的文件路径
last_run_metadata_path => "/etc/logstash/rundata/last_id"
#是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
}
# 过滤部分(不是必须项)
filter {
#@timestapm修改为test表中start_time字段时间,默认@timestapm为当期导入的时间,结合实际使用情况修改
mutate {
add_field => {"temp_ts" => "%{start_time}"}
}
date {
match => ["temp_ts","ISO8601"]
remove_field => ["temp_ts"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "test_index"
# 使用input中的type作为elasticsearch索引下的类型名
document_type => "%{type}" # <- use the type from each input
# elasticsearch的ip和端口号
hosts => "localhost:9200"
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
2.3 启动:
systemctl start logstash #启动
systemctl enable logstash #开机启动
systemctl status logstash #查看
systemctl stop logstash #停止
查看运行结果:
tail -f /var/log/messages















 2425
2425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









