






缘由
PRML是机器学习的经典书籍。我想通过两步部分来大致了解这本书的核心所在,这两个部分也就是不可或缺。
- 数学概念:为这本书的学习打好基础
- introduction:了解这本书具体讲什么
Mathematical notation
Mathematical notation:
数学标识符
I have tried to keep the mathematical content of the book to the minimum neces-sary to achieve a proper understanding of the field. However, this minimum level is nonzero, and it should be emphasized that a good grasp of calculus
(微积分), linear algebra
(线性代数), and probability theory is essential for a clear understanding of modern pattern recognition and machine learning techniques. Nevertheless, the emphasis in this book is on conveying the underlying concepts rather than on mathematical rigour.
(然而,本书的关键是还是理解这些基本的概念,而非对其有着极其严格的标准)
I have tried to use a consistent notation
(一直的表述) throughout the book, although at times this means departing from some of the conventions
(惯例) used in the corresponding research literature. Vectors
(向量) are denoted by lower case bold Roman letters such as
x, and all vectors are assumed to be column vectors
(列向量). A superscript T denotes the transpose of a matrix
(矩阵)or vector, so that
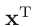 will be a row vector. Uppercase bold roman letters, such as
M, denote matrices. The notation
will be a row vector. Uppercase bold roman letters, such as
M, denote matrices. The notation
 denotes a row vector with M elements, while the corresponding column vector is written as
denotes a row vector with M elements, while the corresponding column vector is written as
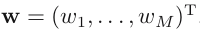
will be a row vector. Uppercase bold roman letters, such as
M, denote matrices. The notation
denotes a row vector with M elements, while the corresponding column vector is written as
The notation [a, b] is used to denote the closed interval from a to b, that is the interval including the values a and b themselves, while (a, b) denotes the corresponding open interval, that is the interval excluding a and b. Similarly, [a, b) denotes an interval that includes a but excludes b. For the most part, however, there will be little need to dwell on such refinements as whether the end points of an interval are included or not
(然而在大多数情况下,不必纠结是否考虑边界).
The M × M identity matrix (also known as the unit matrix) is denoted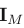 , which will be abbreviated to
I where there is no ambiguity about it dimensionality(维度). It has elements
, which will be abbreviated to
I where there is no ambiguity about it dimensionality(维度). It has elements
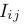 that equal 1 if i = j and 0 if i = j.
that equal 1 if i = j and 0 if i = j.
The M × M identity matrix (also known as the unit matrix) is denoted
, which will be abbreviated to
I where there is no ambiguity about it dimensionality(维度). It has elements
that equal 1 if i = j and 0 if i = j.
A functional is denoted f [y] where y(x) is some function. The concept of a functional is discussed in Appendix D.
The notation
g(x) = O(f (x)) (f(x)是g(x)的高阶无穷小)denotes that
|f (x)/g(x)| is bounded as x → ∞. For instance if
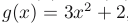 , then
, then
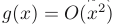 .
.
, then
.
- 无穷小就是以数零为极限的变量
The expectation
(期望) of a function f (x, y) with respect to a random variable x is denoted by
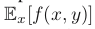 . In situations where there is no ambiguity as to which variable is being averaged over, this will be simplified by omitting the suffix, for instance
. In situations where there is no ambiguity as to which variable is being averaged over, this will be simplified by omitting the suffix, for instance
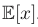 . If the distribution of x is conditioned on another variable z, then the corresponding conditional expectation(
wiki:Conditional_expectation) will be written
. If the distribution of x is conditioned on another variable z, then the corresponding conditional expectation(
wiki:Conditional_expectation) will be written
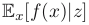 . Similarly, the variance
(方差) is denoted var[f (x)], and for vector variables the covariance is written cov[x, y]. We shall also use cov[x] as a shorthand(速记的) notation for cov[x, x]. The concepts of expectations and covariances are introduced in Section 1.2.2.
. Similarly, the variance
(方差) is denoted var[f (x)], and for vector variables the covariance is written cov[x, y]. We shall also use cov[x] as a shorthand(速记的) notation for cov[x, x]. The concepts of expectations and covariances are introduced in Section 1.2.2.
. In situations where there is no ambiguity as to which variable is being averaged over, this will be simplified by omitting the suffix, for instance
. If the distribution of x is conditioned on another variable z, then the corresponding conditional expectation(
wiki:Conditional_expectation) will be written
. Similarly, the variance
(方差) is denoted var[f (x)], and for vector variables the covariance is written cov[x, y]. We shall also use cov[x] as a shorthand(速记的) notation for cov[x, x]. The concepts of expectations and covariances are introduced in Section 1.2.2.

最后一段有点绕:
- 因为一维就是一个列向量,所以d维就应该是d个列向量,每个列向量含有N个元素
Introduction
The problem of searching for patterns in data is a fundamental(基础的重要的) one and has a long and successful history. For instance, the extensive astronomical observations(天文观测) of Tycho Brahe in the 16th century allowed Johannes Kepler to discover the empirical laws(实证定律;[统计] 经验法则;经验定律) of planetary motion(行星运动), which in turn provided a springboard(跳板) for the development of classical mechanics(机械学). Similarly, the discovery of regularities in atomic spectra(
原子光谱 ) played a key role in the development and verification of quantum physics(量子物理学) in the early twentieth century.
The field of pattern recognition is concerned with the automatic discovery of regularities in data through the use of computer algorithms and with the use of these regularities to take actions such as classifying the data into different categories(利用算法完成在数据发现规律,利用规律去完成某个任务,如分类。).
Consider the example of recognizing handwritten digits, illustrated in Figure 1.1(图如下). Each digit corresponds to a 28×28 pixel image and so can be represented by a vector x comprising 784 real numbers. The goal is to build a machine that will take such a vector x as input and that will produce the identity of the digit 0, . . . , 9 as the output. This is a nontrivial(重要的)problem due to the wide variability of handwriting. It could be tackled using handcrafted(手工艺的) rules or heuristics(启发式) for distinguishing the digits based on the shapes of the strokes(笔触), but in practice such an approach leads to a proliferation(扩散) of rules and of exceptions to the rules and so on, and invariably(总是) gives poor results.
Far better results can be obtained by adopting a machine learning approach in which a large set of N digits {x1 , . . . , xN } called a training set is used to tune(调整) the parameters of an adaptive model(自适应模型). The categories of the digits in the training set are known in advance(训练集的种类要提前知道), typically by inspecting them individually and hand-labelling them. We can express the category of a digit using target vector t, which represents the identity(身份/特征) of the corresponding digit. Suitable techniques for representing categories in terms of vectors will be discussed later. Note that there is one such target vector t for each digit image x.
The result of running the machine learning algorithm can be expressed as a function y(x) which takes a new digit image x as input and that generates an output vector y, encoded in the same way as the target vectors. The precise form of the function y(x) is determined during the training phase, also known as the learning phase, on the basis of the training data. Once the model is trained it can then de- termine the identity of new digit images, which are said to comprise(包含) a test set. The ability to categorize correctly new examples that differ from those used for training is known as generalization(正确为不同输入分类,可以理解普遍化,一般化). In practical applications, the variability of the input vectors will be such that the training data can comprise only a tiny fraction of all possible input vectors, and so generalization is a central goal in pattern recognition.
For most practical applications, the original input variables are typically preprocessed(预处理的) to transform them into some new space of variables where, it is hoped, the
pattern recognition problem will be easier to solve.(对实际的输入做一些预处理,这样能够使得模式识别发挥作用) For instance, in the digit recognition problem, the images of the digits are typically translated and scaled(缩放) so that each digit is contained within a box of a fixed size. This greatly reduces the variability within each digit class, because the location and scale of all the digits are now the same, which makes it much easier for a subsequent pattern recognition algorithm to distinguish between the different classes. This pre-processing stage is sometimes also called feature extraction(特征抽取).Note that new test data must be pre-processed using the same steps as the training data.
Pre-processing might also be performed in order to speed up computation(加速计算). For example, if the goal is real-time face detection(实时脸部识别) in a high-resolution video stream, the computer must handle huge numbers of pixels per second, and presenting these directly to a complex pattern recognition algorithm may be computationally infeasible(计算上不可行). Instead, the aim is to find useful features that are fast to compute(能很快计算的特征), and yet that also preserve useful discriminatory information enabling faces to be distinguished from non-faces(保留能够区别有脸还是没有脸的识别信息). These features are then used as the inputs to the pattern recognition algorithm. For instance, the average value of the image intensity(密度) over a rectangular subregion can be evaluated extremely efficiently (Viola and Jones, 2004), and a set of such features can prove very effective in fast face detection. Because the number of such features is smaller than the number of pixels, this kind of pre-processing represents a form of dimensionality(维度) reduction. Care must be taken during preprocessing because often information is discarded, and if this information is important to the solution of the problem then the overall accuracy of the system can suffer(整体的准确度将会遭殃).
Applications in which the training data comprises examples of the input vectors along with their corresponding target vectors are known as supervised learning( supervised learning的定义 ) problems. Cases such as the digit recognition example, in which the aim is to assign each input vector to one of a finite number of discrete categories, are called classification problems. If the desired output consists of one or more continuous variables(连续变量), then the task is called regression. An example of a regression problem would be the prediction of the yield(产出,产出的多少的值确实是一个连续变量) in a chemical manufacturing process in which the inputs consist of the concentrations of reactants, the temperature, and the pressure.
In other pattern recognition problems, the training data consists of a set of input vectors x without any corresponding target values. The goal in such unsupervised learningproblems may be to discover groups of similar examples within the data, where it is called clustering(聚类), or to determine the distribution of data within the input space, known as density estimation(密度估计), or to project(表达) the data from a high-dimensional space down to two or three dimensions for the purpose of visualization.
Finally, the technique of reinforcement learning(强化学习) (Sutton and Barto, 1998) is concerned with the problem of finding suitable actions to take in a given situation in order to maximize a reward(找到合适的方式在特定的情况找到最大化的结果,). Here the learning algorithm is not given examples of optimal outputs, in contrast to supervised learning, but must instead discover them(就是outputs) by a process of trial and error(反复尝试,尝试错误法). Typically there is a sequence of states and actions in which the learning algorithm is interacting with its environment. In many cases, the current action not only affects the immediate reward but also has an impact on the reward at all subsequent(后来的) time steps. For example, by using appropriate reinforcement learning techniques a neural network can learn to play the game of backgammon(西洋双陆棋戏) to a high standard (Tesauro, 1994). Here the network must learn to take a board position as input, along with the result of a dice throw(扔晒子), and produce a strong move as the output. This is done by having the network play against a copy of itself for perhaps a million games. A major challenge is that a game of backgammon can involve dozens of moves, and yet it is only at the end of the game that the reward, in the form of victory, is achieved. The reward must then be attributed appropriately to(适当的归功于) all of the moves that led to it, even though some moves will have been good ones and others less so. This is an example of a credit assignment problem. A general feature of reinforcement learning is the trade-off(权衡) between exploration, in which the system tries out new kinds of actions to see how effective they are, and exploitation, in which the system makes use of actions that are known to yield a high reward. Too strong a focus on either exploration or exploitation will yield poor results. Reinforcement learning continues to be an active area of machine learning research. However, a detailed treatment lies beyond the scope of this book(这本书不讲强化学习).
Although each of these tasks needs its own tools and techniques, many of the key ideas that underpin(加强基础) them are common to all such problems. One of the main goals of this chapter is to introduce, in a relatively informal way(相对非正式的方式), several of the most important of these concepts and to illustrate them using simple examples. Later in the book we shall see these same ideas re-emerge(再次浮现) in the context of more sophisticated models that are applicable to real-world pattern recognition applications. This chapter also provides a self contained introduction to three important tools that will be used throughout the book, namely probability theory, decision theory, and information theory. Although these might sound like daunting(令人畏惧的) topics, they are in fact straightforward(直截了当的), and a clear understanding of them is essential if machine learning techniques are to be used to best effect in practical applications.
Consider the example of recognizing handwritten digits, illustrated in Figure 1.1(图如下). Each digit corresponds to a 28×28 pixel image and so can be represented by a vector x comprising 784 real numbers. The goal is to build a machine that will take such a vector x as input and that will produce the identity of the digit 0, . . . , 9 as the output. This is a nontrivial(重要的)problem due to the wide variability of handwriting. It could be tackled using handcrafted(手工艺的) rules or heuristics(启发式) for distinguishing the digits based on the shapes of the strokes(笔触), but in practice such an approach leads to a proliferation(扩散) of rules and of exceptions to the rules and so on, and invariably(总是) gives poor results.
Far better results can be obtained by adopting a machine learning approach in which a large set of N digits {x1 , . . . , xN } called a training set is used to tune(调整) the parameters of an adaptive model(自适应模型). The categories of the digits in the training set are known in advance(训练集的种类要提前知道), typically by inspecting them individually and hand-labelling them. We can express the category of a digit using target vector t, which represents the identity(身份/特征) of the corresponding digit. Suitable techniques for representing categories in terms of vectors will be discussed later. Note that there is one such target vector t for each digit image x.
The result of running the machine learning algorithm can be expressed as a function y(x) which takes a new digit image x as input and that generates an output vector y, encoded in the same way as the target vectors. The precise form of the function y(x) is determined during the training phase, also known as the learning phase, on the basis of the training data. Once the model is trained it can then de- termine the identity of new digit images, which are said to comprise(包含) a test set. The ability to categorize correctly new examples that differ from those used for training is known as generalization(正确为不同输入分类,可以理解普遍化,一般化). In practical applications, the variability of the input vectors will be such that the training data can comprise only a tiny fraction of all possible input vectors, and so generalization is a central goal in pattern recognition.
For most practical applications, the original input variables are typically preprocessed(预处理的) to transform them into some new space of variables where, it is hoped, the
pattern recognition problem will be easier to solve.(对实际的输入做一些预处理,这样能够使得模式识别发挥作用) For instance, in the digit recognition problem, the images of the digits are typically translated and scaled(缩放) so that each digit is contained within a box of a fixed size. This greatly reduces the variability within each digit class, because the location and scale of all the digits are now the same, which makes it much easier for a subsequent pattern recognition algorithm to distinguish between the different classes. This pre-processing stage is sometimes also called feature extraction(特征抽取).Note that new test data must be pre-processed using the same steps as the training data.
Pre-processing might also be performed in order to speed up computation(加速计算). For example, if the goal is real-time face detection(实时脸部识别) in a high-resolution video stream, the computer must handle huge numbers of pixels per second, and presenting these directly to a complex pattern recognition algorithm may be computationally infeasible(计算上不可行). Instead, the aim is to find useful features that are fast to compute(能很快计算的特征), and yet that also preserve useful discriminatory information enabling faces to be distinguished from non-faces(保留能够区别有脸还是没有脸的识别信息). These features are then used as the inputs to the pattern recognition algorithm. For instance, the average value of the image intensity(密度) over a rectangular subregion can be evaluated extremely efficiently (Viola and Jones, 2004), and a set of such features can prove very effective in fast face detection. Because the number of such features is smaller than the number of pixels, this kind of pre-processing represents a form of dimensionality(维度) reduction. Care must be taken during preprocessing because often information is discarded, and if this information is important to the solution of the problem then the overall accuracy of the system can suffer(整体的准确度将会遭殃).
Applications in which the training data comprises examples of the input vectors along with their corresponding target vectors are known as supervised learning( supervised learning的定义 ) problems. Cases such as the digit recognition example, in which the aim is to assign each input vector to one of a finite number of discrete categories, are called classification problems. If the desired output consists of one or more continuous variables(连续变量), then the task is called regression. An example of a regression problem would be the prediction of the yield(产出,产出的多少的值确实是一个连续变量) in a chemical manufacturing process in which the inputs consist of the concentrations of reactants, the temperature, and the pressure.
In other pattern recognition problems, the training data consists of a set of input vectors x without any corresponding target values. The goal in such unsupervised learningproblems may be to discover groups of similar examples within the data, where it is called clustering(聚类), or to determine the distribution of data within the input space, known as density estimation(密度估计), or to project(表达) the data from a high-dimensional space down to two or three dimensions for the purpose of visualization.
Finally, the technique of reinforcement learning(强化学习) (Sutton and Barto, 1998) is concerned with the problem of finding suitable actions to take in a given situation in order to maximize a reward(找到合适的方式在特定的情况找到最大化的结果,). Here the learning algorithm is not given examples of optimal outputs, in contrast to supervised learning, but must instead discover them(就是outputs) by a process of trial and error(反复尝试,尝试错误法). Typically there is a sequence of states and actions in which the learning algorithm is interacting with its environment. In many cases, the current action not only affects the immediate reward but also has an impact on the reward at all subsequent(后来的) time steps. For example, by using appropriate reinforcement learning techniques a neural network can learn to play the game of backgammon(西洋双陆棋戏) to a high standard (Tesauro, 1994). Here the network must learn to take a board position as input, along with the result of a dice throw(扔晒子), and produce a strong move as the output. This is done by having the network play against a copy of itself for perhaps a million games. A major challenge is that a game of backgammon can involve dozens of moves, and yet it is only at the end of the game that the reward, in the form of victory, is achieved. The reward must then be attributed appropriately to(适当的归功于) all of the moves that led to it, even though some moves will have been good ones and others less so. This is an example of a credit assignment problem. A general feature of reinforcement learning is the trade-off(权衡) between exploration, in which the system tries out new kinds of actions to see how effective they are, and exploitation, in which the system makes use of actions that are known to yield a high reward. Too strong a focus on either exploration or exploitation will yield poor results. Reinforcement learning continues to be an active area of machine learning research. However, a detailed treatment lies beyond the scope of this book(这本书不讲强化学习).
Although each of these tasks needs its own tools and techniques, many of the key ideas that underpin(加强基础) them are common to all such problems. One of the main goals of this chapter is to introduce, in a relatively informal way(相对非正式的方式), several of the most important of these concepts and to illustrate them using simple examples. Later in the book we shall see these same ideas re-emerge(再次浮现) in the context of more sophisticated models that are applicable to real-world pattern recognition applications. This chapter also provides a self contained introduction to three important tools that will be used throughout the book, namely probability theory, decision theory, and information theory. Although these might sound like daunting(令人畏惧的) topics, they are in fact straightforward(直截了当的), and a clear understanding of them is essential if machine learning techniques are to be used to best effect in practical applications.
1.1. Example: Polynomial Curve Fitting
We begin by introducing a simple regression(回归) problem, which we shall use as a running example throughout this chapter to motivate a number of key concepts. Suppose we observe a real-valued input variable
x and we wish to use this observation to predict the value of a real-valued target variable
t. For the present purposes, it is instructive(有益的) to consider an artificial example using synthetically generated data because we then know the precise process that generated the data for comparison against any learned model. The data for this example is generated from the function
sin(2πx) with random noise included in the target values, as described in detail in Appendix A.
(未完)
(未完)
other summary
与矩阵相关的英文
可逆矩阵(非奇异矩阵)- invertible matrix (non-singular matrix)
矩阵的和-sum of matrices
矩阵的积-product of matrices
矩阵的转置-transpose of matrices
矩阵的行列式-determinant of matrices
可逆矩阵-invertible matrix
单位矩阵-unit matrix
零矩阵-zero matrix
逆矩阵-matrix inverse
伴随矩阵-companion matrix
初等矩阵-elementary matrix
对角线分块矩阵-diagnal .... matrix
矩阵的和-sum of matrices
矩阵的积-product of matrices
矩阵的转置-transpose of matrices
矩阵的行列式-determinant of matrices
可逆矩阵-invertible matrix
单位矩阵-unit matrix
零矩阵-zero matrix
逆矩阵-matrix inverse
伴随矩阵-companion matrix
初等矩阵-elementary matrix
对角线分块矩阵-diagnal .... matrix















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









