







下面是java集合中最常用到的一些集合对象,以及这些对象的底层原理和特点,具体的一些方法看API文档:
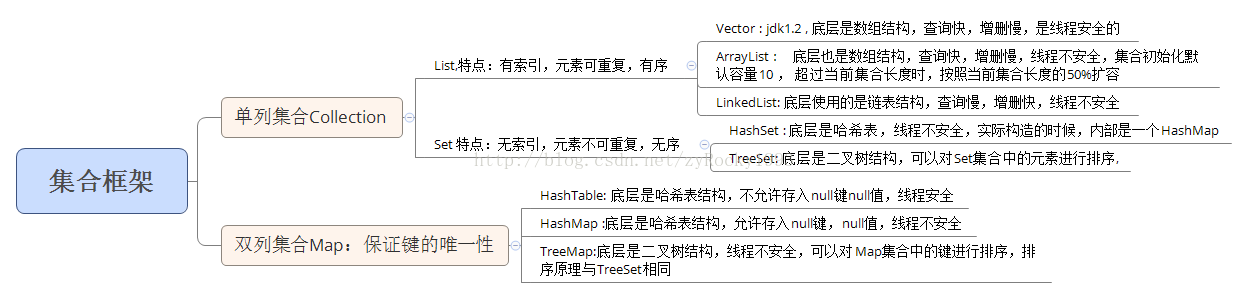
在单列集合Colleciton中,根据所存入的元素是否唯一,有序,分为List 和 Set两大类。其中List集合有索引,可以存入相同的元素,是有序的。该类型的集合常用的有ArrayList,其底层是可变数组,在创建的时候默认数组长度是10,当存满后,再次存入的时候,会创建一个新的数组,数组长度按照当前数组长度的50%增加,然后将之前数组的元素复制到当前新数组中,再继续存新添加的元素;当删除元素的时候需要把要删除位置之后的元素都往前挪一位;在添加和删除元素的时候都需要底层数组进行复制操作,虽然复制调用的是System.arraycopy()方法,底层调用的是Native方法,但是和链表结构的数据在增删这块相比是稍微慢的;但是也正因为底层是数组结构,所以查询比较快。在实际应用中,如果涉及到对集合的查询操作比较多的话,推荐使用ArrayList, , 但是注意ArrayList是线程不安全的,在多线程中注意使用的时候加同步锁。List中还有一个常用集合对象:LinkedList,其底层是链表结构,该数据结构增删快,而遍历查询的时候就比较慢了。下面是ArrayList的遍历代码,其他的一些方法就看API就行了,值的一提的是:List集合中判断元素是否存在、是否相同,其底层使用的是equals()方法。
单列集合:
ArrayList的几种遍历方式:
/**
* List遍历: 注意在遍历的时候最好不要对集合进行增删操作,
* 否则,集合的size发生变化,会出现一些角标问题,如果要在
* 遍历的时候要添加或者删除元素可以尝试这倒着遍历集合
*/
public static void listErgodic(){
ArrayList<String> list = new ArrayList<String>();
list.add("java01");
list.add("java02");
list.add("java03");
list.add("java04");
//第一种遍历方式,使用普通for循环
int size = list.size();
for(int i=0;i<size;i++){
String str = list.get(i);
System.out.println(str);
}
System.out.println("========================");
//第二中遍历方式
//注意:在使用该方法遍历集合的时候,不能使用集合的添加删除方法,
//否则会抛出ConcurrentModificationException , 并发修改异常
for(Iterator<String> it = list.iterator() ;it.hasNext();){
String str = it.next();
System.out.println("iterator: " + str);
}
System.out.println("========================");
//第三种遍历方式:
// ListIterator对象中有添加删除的方法,可以调用该方法对集合进行增删
for(ListIterator<String> lit = list.listIterator() ;lit.hasNext();){
String str = lit.next();
System.out.println("listIterator: " + str);
}
System.out.println("========================");
//第四中方式:
//强制for循环,其底层还是使用的iterator来遍历的,只要实现了Iterator接口,都可以使用强制for循环;
for(String str : list){
System.out.println("forEach: " + str);
}
//在遍历的时候添加元素
for(int i=list.size()-1;i>=0;i--){
String str = list.get(i);
if(str.equals("java03")){
list.add(i,"add java");
}
}
System.out.println(list);
}LinkedList也是Llst集合中的一成员,其底层使用链表数据结构,所以增删快,遍历则比较慢,里面的一些具体方法查看API文档就行了。List集合可以存储相同元素,而且有序,有索引;但是有时候我们需要存储元素的时候,要求所存入的元素要不能重复,这个时候就需要用到Set集合了。Set集合在存储元素的时候是无序的,而且元素不能重复,由于是无序的,所以无法使用普通for循环进行遍历,只能使用强制for循环或者iterator()方法进行便利。常用的子类:HashSet和TreeSet 。其中HashSet底层是哈希表,线程不同步,HashSet内部其实使用的HashMap来保存元素,添加的元素最终做为键保存到HashMap中。下面是HashSet添加元素的源码,以及HashMap中put()方法添加元素时候的源码;
/**
*HashSet中的添加方法;
*map就是内部HashMap对象;
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
*HashMap中的put方法;
*为什么是键唯一? 首先比较hashCode,如果HashCode相同,会比较是不是同一个对象,调用==和equals()方法,如果相同,则判断是同一个对象,替换添加
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}public static void testHashSet(){
HashSet<Person> hs = new HashSet<Person>();
hs.add(new Person("zs1" , 20));
hs.add(new Person("zs1" , 22));
hs.add(new Person("zs1" , 25));
hs.add(new Person("zs1" , 20));
System.out.println(hs);
}
public static class Person{
public String name;
public int age;
public Person(String name , int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "[ " + name + " " + age + " ]";
}
}
//打印结果: [[ zs1 25 ], [ zs1 22 ], [ zs1 20 ], [ zs1 20 ]] public static class Person{
public String name;
public int age;
public Person(String name , int age){
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return name.hashCode() + new Integer(age).hashCode();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Person){
Person person = (Person)obj;
return name.equals(person.name) && age == person.age;
}
return super.equals(obj);
}
@Override
public String toString() {
return "[ " + name + " " + age + " ]";
}
}
//打印结果:[[ zs1 22 ], [ zs1 20 ], [ zs1 25 ]]public static void testTreeSet(){
TreeSet<Person> ts = new TreeSet<Person>();
ts.add(new Person("zs1" , 20));
ts.add(new Person("zs1" , 22));
ts.add(new Person("zs1" , 25));
ts.add(new Person("zs1" , 20));
System.out.println(ts);
}
public static class Person implements Comparable<Person>{
public String name;
public int age;
public Person(String name , int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "[ " + name + " " + age + " ]";
}
@Override
public int compareTo(Person o) {
int result = name.compareTo(o.name);
if(result == 0){
result = new Integer(age).compareTo(new Integer(o.age));
}
return result;
}
}
//打印结果:[[ zs1 20 ], [ zs1 22 ], [ zs1 25 ]]public static void testTreeSet(){
TreeSet<Person> ts = new TreeSet<Person>(new MyComparator());
ts.add(new Person("zs1" , 20));
ts.add(new Person("zs1" , 22));
ts.add(new Person("zs1" , 25));
ts.add(new Person("zs1" , 20));
System.out.println(ts);
}
/**
* 自定义比较器:姓名年龄相同视为相同元素
* @author Zengyong
*
*/
private static class MyComparator implements Comparator<Person>{
@Override
public int compare(Person p1, Person p2) {
int result = p1.name.compareTo(p2.name);
if(result == 0){
result = new Integer(p1.age).compareTo(new Integer(p2.age));
}
return result;
}
}public static class Person implements Comparable<Person>{
public String name;
public int age;
public Person(String name , int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "[ " + name + " " + age + " ]";
}
//下面两个方法保证在哈希表结构的集合中元素唯一性
@Override
public int hashCode() {
return name.hashCode() + new Integer(age).hashCode();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Person){
Person person = (Person)obj;
return name.equals(person.name) && age == person.age;
}
return super.equals(obj);
}
//下面这个方法可以保证在二叉树数据结构中元素的唯一性,
@Override
public int compareTo(Person o) {
int result = name.compareTo(o.name);
if(result == 0){
result = new Integer(age).compareTo(new Integer(o.age));
}
return result;
}
}好了,说完常见的单列集合,下面来唠唠双列集合Map集合。当我们要存入的数据具有一定的映射关系的时候,我们就需要使用到双列集合。说到映射关系,我们应该知道在数学中映射只能是一对一或者一对多,不能够多对一,所以体现在map集合中就是:map集合中的键必须要是唯一的,其元素的唯一性判断在上面已经提到过,如果是哈希表数据结构的,那么就根据hashCode()和equals()方法来判断是否相同, 如果是二叉树数据结构,则是根据比较器Comparator或者对象实现Comparable接口,根据里面的方法返回值,如果返回是0的话,表示是相同对象,替换添加。Map集合中常用的对象有HashMap和TreeMap,其中HashMap底层是哈希表数据结构,线程不安全,无序;TreeMap底层是二叉树数据结构,也是线程不安全,但是可以按照键来排序。这里要注意的时:使用TreeMap来存数据的时候,键所对应的元素一定要实现Comparable接口,覆写里面compare()方法;或者在创建TreeMap对象的时候,传入比较器Comparator对象,这里和之前的一样,如果键对应的对象实现了Comparable接口,同时在创建TreeMap集合的时候也传入了比较器Comparator对象,那么优先使用的是传入的比较器对象。这里我们也很好理解:当对象实现的Comparable接口具有可比性后,但是需要的可比性和对象本身的可比性不同时,为了不改变类本身,而直接传入一个我们自定义的比较器就可以了。下面是HashMap和TreeMap添加元素的实例代码,再次注意:Map集合中键是唯一的,哈希表数据结构的HashMap判断元素是否相同根据hashCode()和equals()方法,二叉树数据结构的TreeMap判断元素是否相同是根据元素本身实现comparable接口,具有可比性,根据compare方法返回值,如果返回为0,表示是相同元素;或者在创建TreeMap的时候,传入一个比较器进行比较。
/**
* 自定义比较器:姓名年龄相同视为相同元素
* @author Zengyong
*
*/
private static class MyComparator implements Comparator<Person>{
@Override
public int compare(Person p1, Person p2) {
int result = p1.name.compareTo(p2.name);
if(result == 0){
result = new Integer(p1.age).compareTo(new Integer(p2.age));
}
return result;
}
}
public static void testTreeMap(){
TreeMap<Person,String> tm = new TreeMap<Person,String>(new MyComparator());
tm.put(new Person("zs1" , 20) ,"a");
tm.put(new Person("zs1" , 23) ,"b");
tm.put(new Person("zs1" , 25) ,"c");
tm.put(new Person("zs1" , 20) ,"d");
System.out.println(tm);
}
public static void testHashMap(){
HashMap<Person,String> hm = new HashMap<Person,String>();
hm.put(new Person("zs1" , 20) ,"a");
hm.put(new Person("zs1" , 23) ,"b");
hm.put(new Person("zs1" , 25) ,"c");
hm.put(new Person("zs1" , 20) ,"d");
System.out.println(hm.toString());
}
public static class Person implements Comparable<Person>{
public String name;
public int age;
public Person(String name , int age){
this.name = name;
this.age = age;
}
//下面两个方法保证在哈希表结构的集合中元素唯一性
@Override
public int hashCode() {
return name.hashCode() + new Integer(age).hashCode();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Person){
Person person = (Person)obj;
return name.equals(person.name) && age == person.age;
}
return super.equals(obj);
}
//下面这个方法可以保证在二叉树数据结构中元素的唯一性,
@Override
public int compareTo(Person o) {
int result = name.compareTo(o.name);
if(result == 0){
result = new Integer(age).compareTo(new Integer(o.age));
}
return result;
}
@Override
public String toString() {
return "[ " + name + " " + age + " ]";
}
}private static void testMapErgodic(){
HashMap<Person,String> hm = new HashMap<Person,String>();
hm.put(new Person("zs1" , 20) ,"a");
hm.put(new Person("zs1" , 23) ,"b");
hm.put(new Person("zs1" , 25) ,"c");
hm.put(new Person("zs1" , 20) ,"d");
//第一种方式:
Set<Person> set = hm.keySet();
for(Person p : set){
String value = hm.get(p);
System.out.println(p+" = " + value);
}
System.out.println("==========================");
//第二种方式
Set<Map.Entry<Person, String>> setEntry = hm.entrySet();
for(Map.Entry<Person, String> entry : setEntry){
System.out.println(entry.getKey() + " = " + entry.getValue());
}
}













 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









