









如需完整项目,请私信博主
基于Pytorch的人脸识别及人像卡通化算法设计与实现综述
一、引言
随着深度学习技术的飞速发展,人脸识别与人像卡通化作为计算机视觉领域的两大重要应用,近年来受到了广泛关注。基于Pytorch的人脸识别技术通过构建深度学习模型,实现对人脸特征的提取与比对,从而完成身份识别任务。而人像卡通化算法则利用神经网络将真实的人脸图像转换为具有卡通风格的图像,为用户提供了丰富多样的视觉体验。本文将综述基于Pytorch的人脸识别及人像卡通化算法的设计与实现过程。
二、基于Pytorch的人脸识别算法设计与实现
人脸识别算法通常包括人脸检测、特征提取和特征比对三个关键步骤。在Pytorch框架下,我们可以利用预训练的神经网络模型来完成这些任务。
首先,人脸检测是识别过程的第一步,其目标是从输入图像中定位出人脸区域。常用的方法包括MTCNN、YOLO等,这些算法能够准确地检测出人脸的位置和大小。
接下来,特征提取是人脸识别的核心环节。在Pytorch中,我们可以使用深度卷积神经网络(CNN)来提取人脸特征。这些网络经过大量人脸数据的训练,能够学习到人脸的深层特征表示。通过将人脸图像输入到网络中,我们可以得到对应的特征向量。
最后,特征比对是将提取到的人脸特征与注册库中的人脸特征进行比对,以判断其身份。这通常通过计算特征向量之间的相似度来实现,常用的相似度度量方法包括余弦相似度、欧氏距离等。
三、基于Pytorch的人像卡通化算法设计与实现
人像卡通化算法的目标是将真实的人脸图像转换为具有卡通风格的图像。在Pytorch框架下,我们可以利用生成对抗网络(GAN)等深度学习模型来实现这一任务。
首先,我们需要构建一个能够学习真实人脸到卡通人脸映射的神经网络模型。这通常包括一个生成器网络和一个判别器网络。生成器网络负责将输入的人脸图像转换为卡通风格的图像,而判别器网络则用于判断生成的卡通图像是否真实。
在训练过程中,我们通过优化生成器网络和判别器网络的参数,使得生成器能够生成更逼真的卡通图像,同时判别器能够更准确地判断图像的真实性。这通常通过交替训练生成器和判别器来实现。
最终,经过训练的生成器网络可以用于将任意的人脸图像转换为卡通风格的图像。用户只需将人脸图像输入到网络中,即可得到对应的卡通化结果。
四、总结与展望
本文综述了基于Pytorch的人脸识别及人像卡通化算法的设计与实现过程。通过利用深度学习技术和神经网络模型,我们能够实现对人脸的准确识别以及将人脸图像转换为卡通风格的图像。这些技术为计算机视觉领域的发展提供了有力支持,并为用户提供了更加丰富多样的视觉体验。
未来,随着深度学习技术的不断进步和新的神经网络模型的出现,我们可以期待人脸识别和人像卡通化算法的性能将得到进一步提升。同时,我们还可以探索将这两种技术与其他计算机视觉任务相结合,以实现更广泛的应用和更高级的功能。
项目描述
人像卡通风格渲染的目标是,在保持原图像ID信息和纹理细节的同时,将真实照片转换为卡通风格的非真实感图像。我们的思路是,从大量照片/卡通数据中习得照片到卡通画的映射。一般而言,基于成对数据的pix2pix方法能达到较好的图像转换效果,但本任务的输入输出轮廓并非一一对应,例如卡通风格的眼睛更大、下巴更瘦;且成对的数据绘制难度大、成本较高,因此我们采用unpaired image translation方法来实现。
Unpaired image translation流派最经典方法是CycleGAN,但原始CycleGAN的生成结果往往存在较为明显的伪影且不稳定。近期的论文U-GAT-IT提出了一种归一化方法——AdaLIN,能够自动调节Instance Norm和Layer Norm的比重,再结合attention机制能够实现精美的人像日漫风格转换。
与夸张的日漫风不同,我们的卡通风格更偏写实,要求既有卡通画的简洁Q萌,又有明确的身份信息。为此我们增加了Face ID Loss,使用预训练的人脸识别模型提取照片和卡通画的ID特征,通过余弦距离来约束生成的卡通画。
此外,我们提出了一种Soft-AdaLIN(Soft Adaptive Layer-Instance Normalization)归一化方法,在反规范化时将编码器的均值方差(照片特征)与解码器的均值方差(卡通特征)相融合。
模型结构方面,在U-GAT-IT的基础上,我们在编码器之前和解码器之后各增加了2个hourglass模块,渐进地提升模型特征抽象和重建能力。
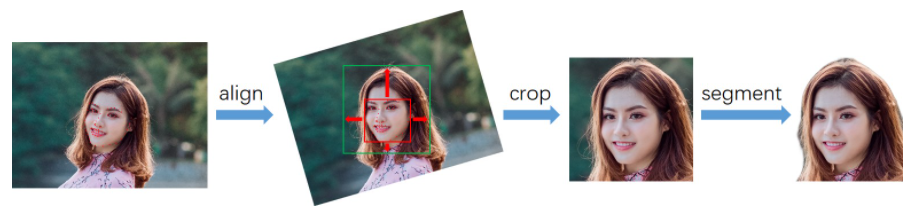
由于实验数据较为匮乏,为了降低训练难度,我们将数据处理成固定的模式。首先检测图像中的人脸及关键点,根据人脸关键点旋转校正图像,并按统一标准裁剪,再将裁剪后的头像输入人像分割模型去除背景。
 ### 安装依赖库
### 安装依赖库
项目所需的主要依赖库如下:
- python 3.6
- pytorch 1.4
- tensorflow-gpu 1.14
- face-alignment
- dlib
训练
1.数据准备
训练数据包括真实照片和卡通画像,为降低训练复杂度,我们对两类数据进行了如下预处理:
- 检测人脸及关键点。
- 根据关键点旋转校正人脸。
- 将关键点边界框按固定的比例扩张并裁剪出人脸区域。
- 使用人像分割模型将背景置白。
python data_process.py --data_path YourPhotoFolderPath --save_path YourSaveFolderPath
2.训练
重新训练:
python train.py --dataset photo2cartoon
加载预训练参数:
python train.py --dataset photo2cartoon --pretrained_weights models/photo2cartoon_weights.pt















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











