







在上一篇文章中根据坏的样本和坏的数据的表格中得到如下推论:
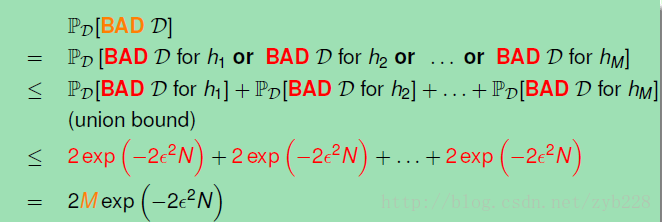
对于所有的M(假设的个数),N(数据集规模)和阈值,Hoeffding Inequality都是有效的,
我们不必要知道Eout,可以通过Ein来代替Eout(这句话的意思是Ein(g)=Eout(g) is PAC)。
由上篇文章所讲的Hoeffding Inequality可得到下面式子:

我们的希望
- 我们希望Eout(g)越接近Ein(g)越好;
- 我们希望Ein(g)越小越好,最好是接近于0.
我们的期待
- M是有限的(不要太大);
M不能太小,能让我们找到比较多的hypothesis.
根据式子:
分析:
如果M很小的话,表示坏事情发生的概率很小(坏事情:假设hypothesis在Data上训练错误率)–这是我们所期待的,但是M很小的缺陷是我们的选择有限了,我们不一定能找到这样的hypothesis来进行学习。而如果M很大,可能是一个大于1的数,这不是我们想要的。但是M很大时能满足我们的另一个期待:有很多hypothesis供我们选择,不然做了很多最后得不到hypothesis,就相当于做无用功。

化无限为有限
猜想:
我们是否可以用一个有限的和假设集相关的量mH来替换不可求得M,然后我们根据mH来证明坏事情发生的概率很小?
验证:
(在二维空间上我们采用线性分类举例,更高维的空间方法类似)对于二维空间上的每一个点xi来说世界上只有两种线:
xi在一种线的眼里是x以及xi在一种线的眼里是o。
所以可以得到一个最直观的结论(不一定对):在二维空间上的N个点来说可能有2^N种线。
这个结论对不对呢?
当然是不对的。(采用数学归纳法证明)
如下图:

由此可以实现我们的一个希望了,Eout(g)是可以很接近Ein(g)的。因为mH在一定情况下是有限的,故式子

的左边也是一个有限的数,且很大几率是小于1的值,所以Eout(g)是可以很接近Ein(g)的。
感谢林老师的课。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











