








MapReduce
前几天看了google的mapreduce论文,里面有很多学习的知识点,故在此记录。
其中难免有错误,希望指出,有评论立即会回。
mapreduce基本概念
写过一些mapreduce程序之后,觉得mapreduce程序分为两部分
-
map阶段,输入时的<key,value>对,key一般为文件的offset,value一般为一行的字符串
经过自己编写的map代码处理后,输出自定义的<key,value>对。结果存储在本地磁盘中
-
reduce阶段,输入为<key,list>形式,是map输出的中间结果按照key排序,相同key
聚集起来形成set的结果,经过自己编写的reduce代码处理后,输出自定义的<key,value>对。
结果存储在HDFS。
mapreduce基本执行流程
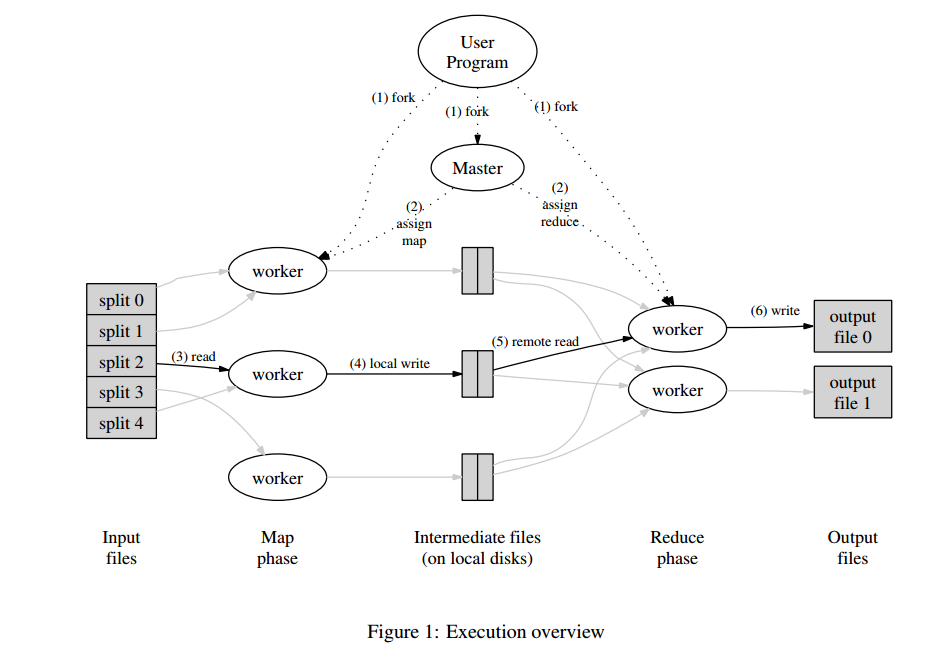
-
将输入数据分为M份(M为Map任务数),并且将用户程序拷贝到集群中的各个机器中。
-
master(主节点)分配M个map任务,和R个reduce任务
-
map任务读取对应的数据,将数据以<key, value>的格式提交给map fuction
执行map fuction先将结果缓存到内存中
-
定期的,将map产生的中间结果写入到本地磁盘中,并且分成R个部分。
中间结果数据在本地磁盘的位置信息会发送给master,以便Reducer执行的时候
能找到相应的数据
-
reducer通过master读取存在本地磁盘中的中间结果数据,之后对读取到的数据
按照key进行排序,拥有相同key的数据被聚集在一起,这样做的目的是防止中间数据
过大,致使内存溢出(只返回Iterable)
-
将处理后的中间数据,<key, list>的形式作为reduce程序的输入,运行reduce程序
最后输出最后的结果。
-
所有的map任务和reduce任务完成后,对用户程序进行返回。
map, reduce函数我就不介绍了,没有意义。
Partitioner类
决定中间数据分到那个reduce任务
一个简单的排序代码, 可以具体了解partition的作用
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.Logger;
public class Sort {
private static Logger log = Logger.getLogger(Sort.class);
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String hdfs = "hdfs://192.168.56.4:9000";
conf.set("fs.defaultFS", hdfs);
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: StepOne <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Sort");
job.setJarByClass(Sort.class);
job.setMapperClass(SortMapper.class);
job.setNumReduceTasks(10);
//job.setCombinerClass(StepOneReducer.class);
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class);
job.setPartitionerClass(Partition.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class SortMapper extends Mapper<LongWritable, Text, LongWritable, LongWritable>{
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(new LongWritable(Long.parseLong(value.toString())),new LongWritable(Long.parseLong(value.toString())));
}
}
public static class SortReducer extends Reducer<LongWritable, LongWritable, LongWritable, LongWritable> {
private static LongWritable index = new LongWritable(0);
public void reduce(LongWritable key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException{
log.info(key.toString());
for(LongWritable value : values) {
index = new LongWritable(index.get() + 1);
context.write(index, key);
}
}
}
public static class Partition extends Partitioner<LongWritable, LongWritable> {
@Override
public int getPartition(LongWritable key, LongWritable value, int numPartitions) {
long maxValue = 10000;
long board = maxValue / numPartitions + 1;
for(int i = 0; i < numPartitions; i++) {
if(key.get() >= i * board && key.get() < (i+1)*board) return i;
}
return -1;
}
}
}
Combiner类
对保存在本地的map的中间输出结果进行简单合并,以减少带宽
以后遇到相应的例子,会补上代码
一些要点
-
为什么map输出的结果要保存到本地,而reduce输出的结果要保存在HDFS上?
首先reduce输出的结果是最后我们需要的结果,保存在HDFS,可以实现较好的容错性。
而map得输出是中间数据,如果保存在HDFS上,会耗费很大的网络带宽用于复制中间
数据,形成其三个副本,实现容错性。所以我们没有必要把map的输出保存到HDFS上。
map输出的数据没有实现容错,所以如果保存其中间数据的机器宕机了,需要重新执行
map task.而丢失了reduce的结果数据,就不需要重新执行reduce task.因为其在别的机器
上还有副本
-
Backup Tasks
google的map reduce论文强调了Backup Task这个概念。
具体说得是:集群中的机器参差不齐,有性能很好的,有性能很差的,经常会出现老机器
“拖后腿”的情况,就是老机器性能很难,执行一个相同的任务,花费的时间要多很多。
老机器增加了mapreduce的整体运行时间。所以google提出了Backup Task的概念。
就是mapreduce程序接近执行完的时候,检查还有那些程序再执行,选择另外空闲的机器
执行这些程序,只要其中得到程序的结果,就认为程序执行完了,不管程序结果是由那个机器
得出的。这样有效得改善了老机器“拖后腿”得情况
-
Skipping Bad Records
skipping bad records也是提高mapreduce性能得一项举措。
造成程序崩溃可能是由于记录错误得原因。所以如果master检查到程序多次在这个记录下
crash,就跳过这个记录,使程序依旧向前执行。















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









