






首先应该理解英文字母在计算机中也是按照一个个的字节进行存储的,也就是char类型的大小,对应于ASCII编码的方式。
RLE(Run Length Encoding)算法:行程长度编码!
算法的大致思想就是将一串连续的英文字母中连续重复出现的次数计算出来,然后只是使用对应的单个字符和出现的次数来进行重新计数。如下面的例子:
AAAAAABBCDDEEEEEF:一共是17个字符!很容易发现其中很多的字符是连续的重复出现的情况,则可以优先计算出出现的次数后再进行标记!
A6B2C1D2E5F1结果如此,因为A字母出现了六次后面的依次如此使用完成即可!
优缺点:算法简单、容易实现;但是基于其本身的压缩思想,其只能对一些特定的序列数据才有效,有的数据使用该算法压缩后反而会出现数据空间占用率更高!如:ABCDEFG当数据没有重复出现的时候对应的得到的结果为:A1B1C1D1E1F1G1这样的结果很显然占据了更多内存!
哈夫曼编码:将出现频率最高的字符使用最短的数字的来表示,依次递增。出现频率最低的字符使用最长的数字来表示:
如AAAAAABBCDDEEEEEF:则如下表所示:
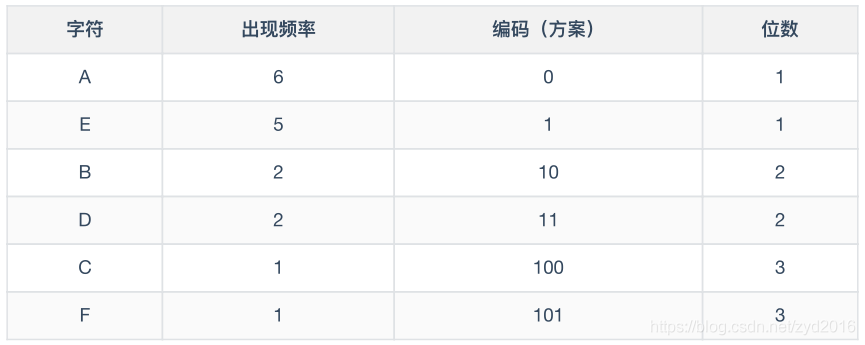
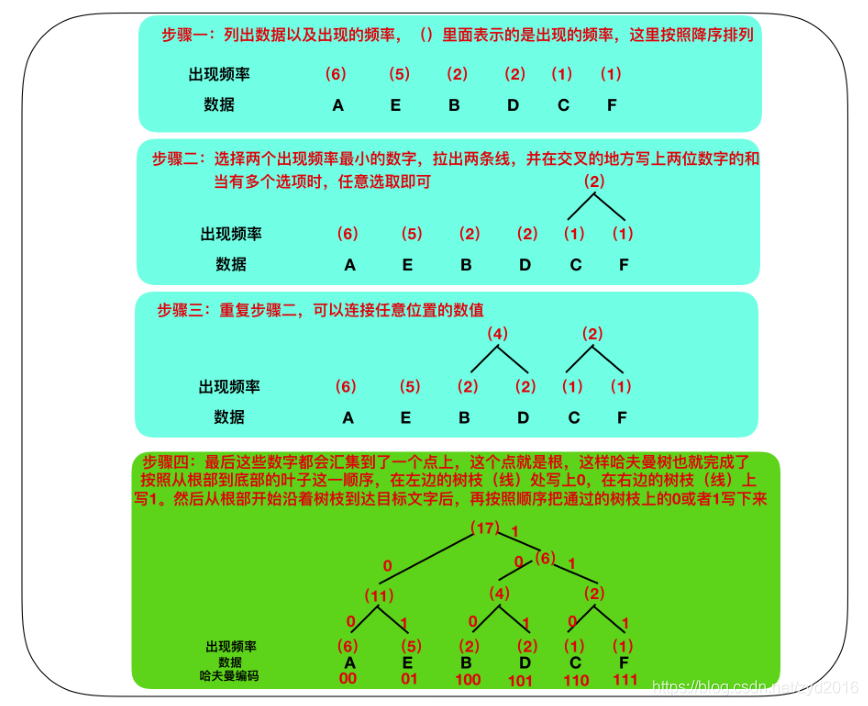
哈夫曼树可以很好的提升其的压缩效率,实现很好的压缩。
上面的哈夫曼的原理如果有不明白的话,可以百度查看一下哈夫曼的算法原理去理解分析。
最后是两种关于可逆压缩和非可逆压缩的方法:
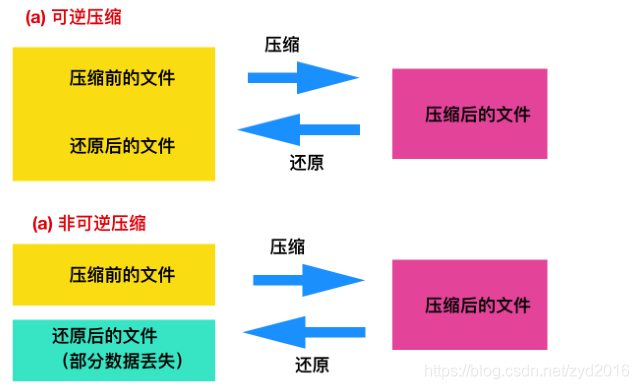
现有的还有一些更加高级的压缩实现。读者可以自己了解!















 2738
2738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









