







目录
1 摘要
由于深度模糊和自遮挡,使得单目视频的3D人体姿态估计更具有挑战性。现有的大部分网略都通过时空结合来解决这个问题,但是其实3DHPE其实是一个逆问题,即存在多个可行解(即假设),要从这多个假设中找出最优解。本篇论文提出了MHFormer,它是一个基于Transformer的三阶段框架,用于从单目视频中估计3D人体姿态,通过学习多个合理姿态假设的空间-时间表征来生成这些假设。
MHFormer的主要创新点如下:
1. 多假设生成(MHG):MHFormer通过MHG模块生成多个初始姿态假设,这些假设在空间域内捕获了不同深度级别的特征,从而为后续的精细化处理提供了丰富的信息。
2. 自假设精炼(SHR):该模块通过自注意力机制(MH-SA)和混合多层感知器(MLP)来独立地精炼每个假设的特征,增强了单个假设内部的信息交流和特征表示。
3. 跨假设交互(CHI):CHI模块通过多假设交叉注意力(MH-CA)机制,实现了不同假设之间的信息交流和交互,这有助于整合多个假设的信息以产生更准确的最终姿态估计。
1. 单目视频和多目视频
单目视频(Monocular Video)指的是仅使用一个摄像头捕获的视频序列。与使用多个摄像头从不同角度同时记录的多目视频(例如立体视觉或多视角视频)不同,单目视频仅从一个视角提供信息,因此缺乏直接的深度信息和从不同视角观察的立体视觉线索。
在计算机视觉中,单目视频处理通常涉及以下挑战:
深度歧义:由于只有一个视角,单目视频不能直接提供场景中物体距离相机的深度信息,这可能导致在估计物体位置和姿态时出现歧义。
自我遮挡:视频中的物体或人可能在某些时候被自身或其他物体遮挡,这使得从单一视角观察时难以观察到被遮挡部分。
光照和纹理变化:单目视频可能受到光照条件和表面纹理的影响,这些因素可能会影响特征的检测和跟踪。
尺度变化:由于缺乏立体视觉信息,单目视频中的物体尺度变化可能难以准确估计。
2. 逆问题
“逆问题”指的是从单目视频估计3D人体姿态的任务。这是一个逆问题,因为它需要从2D图像中恢复出3D信息,而这个过程不是唯一的,存在多种可能的解决方案。他的挑战除了单目视频的挑战外,还存在了如下挑战:
2D到3D的映射:从2D图像的姿态关键点到3D空间的姿态恢复是一个不适定问题,因为不同的3D姿态可能在2D图像上投影为相同或非常相似的2D关键点。
多解性:由于上述的深度歧义和自我遮挡,从单目视频恢复3D姿态可能存在多个合理的解,而不是一个唯一的解。
2 介绍
现有方法的局限性
基于单目视频的3D HPE在动作识别、人机交互和增强/虚拟现实等领域都有着广泛的应用。尽管现有的方法在2D姿态检测和 2D-to-3D lifting 方面取得很大的发展,性能也得到了很大提升,但由于2D表示中的自我遮挡和深度歧义,这个问题仍然是个很大的挑战。
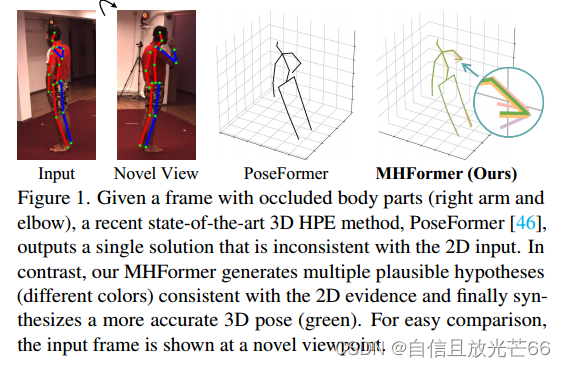
为了缓解这些问题,大多数方法侧重于探索空间和时间的关系。要么使用图卷积网络通过人体骨骼的时空图表示来估计3D姿势,要么应用纯基于transformer的模型从2D姿势序列中捕获时空信息。但是这些方法忽略了这个问题,只估计了一个单一的解决方案,这通常会导致不满意的结果,特别是当人的关节严重被阻挡时。如图1所示,图中给定一个身体部位(右臂和肘部)遮挡的帧,最新的最先进的3D HPE方法PoseFormer输出一个与2D输入不一致的单一解。相比之下,MHFormer生成与2D输入一致的多个貌似合理的假设(不同的颜色),并最终合成更准确的3D姿势(绿色)。为了便于比较,输入帧的另一个视角如“Novel View”所示
逆问题的挑战
因为缺乏直接的深度信息,从单目视频中进行2D-to-3D lifting是一个逆问题,存在多个可行的解决方案(即假设)。最近提出的一些方法通过使用特征提取器,向现有架构中添加多个相同的输出头来生成多个假设,但这些方法未能建立不同假设特征之间的关系,这是提高模型表达能力和性能的一个重要短板。
MHFormer的核心思想
针对三维HPE的模糊逆问题,作者认为应该首先进行一对多的映射,然后通过各种中间假设进行多对一的映射,因为这样可以丰富 特征的多样性 并更好地合成最终的三维姿态。
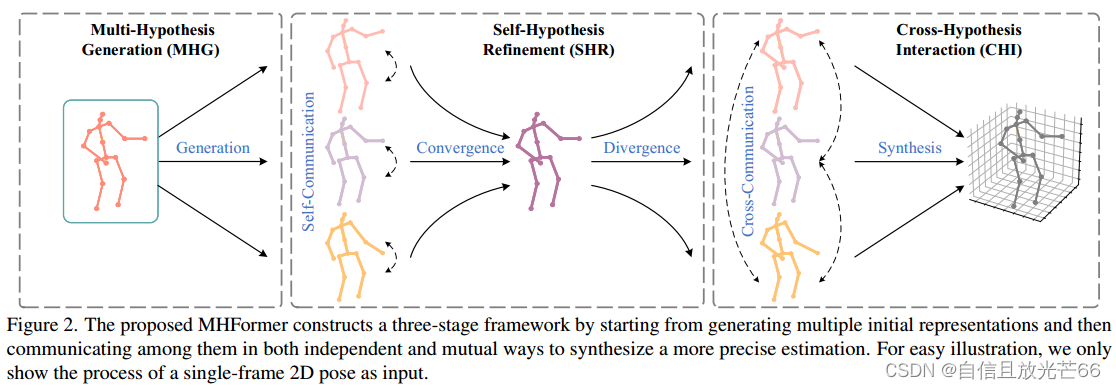
三阶段框架:
MHFormer采用三阶段框架,包括:
1. 多假设生成(MHG):模拟人体关节的内在结构信息在空间域中生成多个多层次特征。这些特征包含了从浅到深不同深度的不同语义信息,因此可以看作是多个初始表示。
2. 自假设精炼(SHR):SHR由两个新的区块组成,第一个模块式多假设自注意力(MH-SA)和假设混合多层感知器(MLP)组成。通过自注意力机制和混合MLP来独立地精炼每个假设的特征。MH-SA的目的是为每个单独的假设内部构建自假设通信,这样可以通过特征增强来传递消息。这里的MLP主要是用于在自假设中的多个特征串联整合,然后收敛这些特征。
3. 跨假设交互(CHI):由于SHR中的MH-SA只传递假设内部信息,因而不同假设之间的联系不够强。故在最后阶段,通过多假设交叉注意力机制(MH-CA)和混合MLP来模拟多假设特征之间的交互。MLP是在经过MH-SA处理后,用于假设交换信息的过程。这个过程涉及将多个假设的特征进行整合。具体来说,它将多个假设的特征串联起来,然后输入到MLP中,以合并(收敛)这些特征。接着,这个合并后的特征表示被均匀地分割(发散)成多个不重叠的块,形成经过精炼的假设表示。
如图2所示,该框架更有效地模拟多假设依赖关系,同时也在假设特征之间建立更强的关系。
Transformer模型的应用
MHFormer将多假设空间-时间特征层次明确地纳入Transformer模型中,以端到端的方式独立且相互处理身体关节的多个假设信息。
贡献
1. MHFormer在两个具有挑战性的数据集Human3.6M和MPI-INF-3DHP上的性能显著优于先前的方法PoseFormer,特别是在Human3.6M数据集上,性能提升了3%。
2. 提出了一种新的基于Transformer的方法MHFormer,用于处理单目视频中的3D HPE任务,并通过独立和相互之间的多假设特征通信,提供了强大的自假设和跨假设信息传递能力,建立了假设之间的强关系。
3 相关工作
3.1 3D HPE
略
3.2 ViT
最近,由于其强大的全局自注意力机制,Transformer模型在计算机视觉社区引起了越来越多的研究兴趣。在基本的图像分类任务中,ViT(Vision Transformer)模型提出了将标准的Transformer架构直接应用于图像块序列的方法。PoseFormer模型将纯粹的Transformer应用于捕捉人体关节之间的关联性和时间依赖性。该模型引入了一种结合了步幅卷积(strided convolutions)的Transformer架构,用于将长序列的2D姿态转换为单一的3D姿态。Strided Transformer模型引入了一种结合了步幅卷积(strided convolutions)的Transformer架构,用于将长序列的2D姿态转换为单一的3D姿态。MHFormer的工作受到了上述模型的启发,并采用了Transformer作为基础架构。但与仅使用单一表示的简单架构不同,MHFormer将多假设和多级特征层次的关键思想整合到Transformer中,这使得模型不仅具有表现力,而且更加强大。MHFormer引入了交叉注意力机制,以实现有效的多假设学习。这是对Transformer模型的一个重要扩展,它允许模型在不同的假设之间交换信息,从而提高了学习多姿态假设的能力。
3.3 多假设方法
单目3D HPE具有很多不确定性的问题存在,意味着从2D图像恢复3D姿态可能存在多个合理的解决方案。一些研究工作通过为逆问题生成多样化的假设来实现显著的性能提升。这些方法通过考虑多种可能的姿态来处理逆问题的不确定性。Jahangiri等人通过组合模型和解剖学约束来生成与2D关键点一致的多个3D姿态候选。Wehrbein使用归一化流(normalized flows)来建模3D姿态假设的后验分布。与现有工作不同,MHFormer采用了一种先进行一对多映射(生成多个假设),然后进行多对一映射(从多个假设中合成最终姿态)的策略。这种方法允许对不同假设对应的不同特征进行有效建模,从而提高姿态表示的能力。
4 MHFormer
4.1 概述
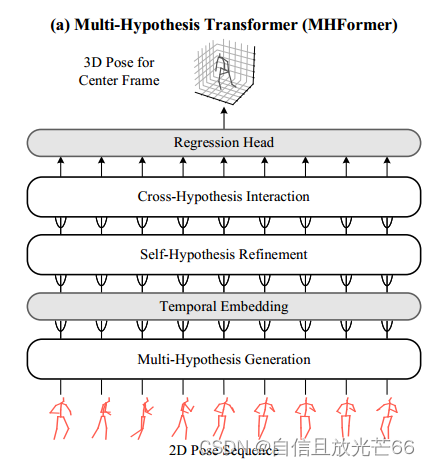
MHFormer旨在重建视频中心帧的3D姿态,它通过充分利用多假设特征层次结构中的空间和时间信息来实现。
输入是一系列由现成的2D姿态检测器从视频中估计的连续2D姿态序列。
MHFormer构建在三个主要模块之上,形成一个三阶段的处理流程:
(1)多假设生成(MHG):负责生成多个初始姿态假设。
(2)自假设精炼(SHR):对每个单独的假设进行精炼,以增强特征表示。
(3)跨假设交互(CHI):在不同假设之间建立交互,以改进最终的姿态估计。
除了这三个主要模块,MHFormer还包括两个辅助模块:
(1)时间嵌入(Temporal Embedding):将空间域的特征转换为时间域,以捕获时间依赖性。
(2)回归头(Regression Head):用于将处理后的特征转换为最终的3D姿态估计。
4.2 准备阶段
由于Transformer对长距离依赖关系建模表现良好,所以本篇论文选择了Transformer作为基础架构。Transformer的基础组件为多头自注意力机制(MS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









