







这篇论文提出了一个名为PoseFormerV2的新型3D人体姿态估计方法,它通过在频率域上对长序列的2D关节数据进行紧凑表示,有效地扩大了模型的感受野并增强了对噪声的鲁棒性。具体来说,PoseFormerV2利用离散余弦变换(DCT)来捕捉输入关节序列的低频成分,这些成分足以代表整个序列的视觉身份,同时滤除了由2D关节检测器引入的噪声。通过最小化对原始PoseFormer架构的修改,PoseFormerV2在时间域和频率域上融合特征,实现了比前身更好的速度-精度权衡。在Human3.6M和MPI-INF-3DHP这两个基准数据集上的广泛实验表明,PoseFormerV2在处理长序列输入和对噪声鲁棒性方面均优于现有的基于变换器的方法,达到了当前最先进的性能水平。
目录
6.4.1 消融实验1:转换PoseFormerV1为PoseFormerV2
1 概述
这篇论文介绍了一种新的3D人体姿态估计方法,名为PoseFormerV2。这种方法旨在提高处理长序列输入的效率,并增强对嘈杂2D关节检测的鲁棒性。下面是对论文内容和使用的方法的具体介绍:
1.1 背景与挑战
传统的基于变换器的方法(如PoseFormer)在2D到3D的人体姿态估计中取得了成功,但在处理长序列输入和对2D关节检测噪声的鲁棒性方面存在局限。
这些方法通常对输入序列的所有帧应用自注意力,导致计算成本随着帧数增加而显著提高。
1.2 方法
PoseFormerV2:提出了PoseFormerV2,它利用频域中的紧凑表示来处理长骨架序列,从而有效扩展接收场并提高对嘈杂2D关节检测的鲁棒性。
频域表示:通过离散余弦变换(DCT)将骨架序列转换到频域,并只使用部分低频系数来编码输入时间序列的多级时间信息,其中低频系数编码序列的大致轮廓,高频系数编码细节(如抖动或突变)。
1.3 架构
PoseFormerV2继承了PoseFormer的空间-时间架构,但对空间变换器编码器进行了修改,使其只观察长序列中的少数中心帧。然后,它将这些“短视”的帧级特征与完整序列的低频分量的全局特征相结合。
特征融合:提出了一个时间-频域特征融合模块,该模块采用变换层来模拟跨帧的时间依赖性,并将时域和频域特征融合在一起。
1.4 创新点总结
1. 频域表示:
V2引入了频域表示,特别是通过离散余弦变换(DCT)将输入的2D骨架序列转换到频域,并只使用低频系数来表示序列。这种表示方法可以有效地捕捉序列的整体趋势,同时过滤掉高频噪声,如关节检测中的抖动和异常值。
2. 时间-频率特征融合:
V2设计了一个时间-频率特征融合模块,该模块结合了时域中的特征(来自少数中心帧的空间Transformer编码器)和频域中的特征(来自完整序列的低频DCT系数)。这种融合方法使得模型能够同时利用局部的精细动作信息和全局的序列信息。
3. 改进的Transformer结构:
V2对Transformer结构进行了改进,使其能够更好地处理时域和频域的特征。这包括对自注意力机制的修改,以及引入了一个特殊的多层感知器(FreqMLP),它在频域特征的前馈网络中使用DCT和逆DCT来调整每个频率成分的权重。
2 摘要
背景:基于变换器的方法在顺序化的2D到3D人体姿态估计中取得了显著的成功。作为开创性的工作,PoseFormer通过级联的变换器层通过捕获每个视频帧中人体关节的空间关系以及跨帧的人体动态实现姿态估计。
挑战:PoseFormer在实际应用中面临两个主要问题:① 输入序列的长度限制;② 对2D关节检测质量的依赖,现有方法通常对输入序列的所有帧应用自注意力,当增加帧数以获得更高级的估计精度时,会导致巨大的计算负担,并且它们对2D关节检测器有限能力所带来的噪声并不鲁棒。
解决方案:文章提出的PoseFormerV2通过在频域中对骨架序列进行紧凑的表示,有效地扩展了接收场,并增强了对嘈杂2D关节检测的鲁棒性,从而解决了上述问题。这种方法通过最小化的架构改动,有效地结合了时域和频域的特征。
实验结果:在Human3.6M和MPI-INF-3DHP两个数据集上的实验显示,PoseFormerV2在速度和准确性的权衡上超越了PoseFormer和其他基于变换器的方法。
3 介绍
前半部分对于3D HPE的介绍与PoseFormer一致,主要从PoseFormer目前的缺陷以及V2做出的改进讲起。关于PoseFormer的具体介绍见上一篇。
3.1 PoseFormer面临的挑战
PoseFormer模型在性能上主要受到了两个因素的限制:
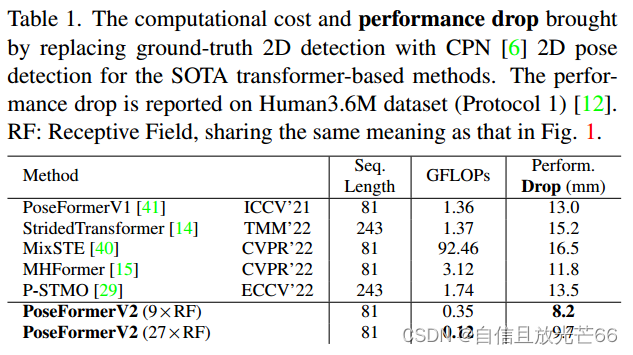
① 输入2D骨架序列长度:为了获得先进的性能,基于变换器的方法通常需要使用非常长的输入序列,现有方法通常对输入序列的所有帧应用自注意力,导致计算负担巨大,且对2D关节检测的噪声敏感。例如,PoseFormer使用81帧,P-STMO使用243帧,而MHFormer使用351帧。对于这些长序列使用自注意力机制进行处理在计算上非常昂贵。例如,在RTX 3090 GPU上,3帧的PoseFormer单轮训练成本约为5分钟,而81帧的PoseFormer成本激增至约1.5小时。
② 2D关节检测的质量:2D关节检测器由于其训练数据集的偏差以及单帧估计范式带来的时间一致性问题,不可避免地会引入噪声。例如,在Human3.6M数据集上,使用ground-truth 2D检测的PoseFormer达到了31.3mm的MPJPE(Mean Per Joint Position Error,每个关节的平均位置误差)。当将ground-truth的输入替换为CPN [6] 2D姿态检测时,这个结果显著下降到44.3mm。
在实际应用中,PoseFormer可能会有长序列推理很难部署在资源有限的设备的硬件上(如AR/VR头显),且很难获得高质量的2D检测的挑战。
表1提供了有关现有基于变换器的方法处理长序列的效率以及对嘈杂2D关节检测的鲁棒性的更多定量结果。
Tips:ground-truth
"ground truth"(真实值或真实数据)指的是真实、准确且客观的数据,通常用作评估模型性能的标准答案或基准。在3D人体姿态估计的上下文中,ground truth指的是人体关节在3D空间中的真实位置。当使用ground-truth作为输入时,他的作用可能是:
1. 数据集的ground truth标注:在训练和评估3D人体姿态估计模型时,通常有一个数据集,其中包含了视频帧或图像以及对应的人体关节的3D位置标注。这些标注是人工标注或使用高精度设备(如运动捕捉系统)获得的,代表了关节位置的真实值。
2. 评估模型性能:为了评估模型的性能,会将模型预测的3D姿态与ground truth进行比较。常用的评估指标,如MPJPE(Mean Per Joint Position Error),会计算模型预测的关节位置与ground truth之间的平均欧氏距离。
3. 使用ground truth进行训练:在某些情况下,可能会使用ground truth数据来训练模型,尤其是在数据量有限或为了获得最佳性能时。
4. 消融研究:在消融研究中,研究者可能会使用ground truth数据来测试模型在没有2D检测噪声干扰时的性能,以此来评估模型对2D检测噪声的敏感度。
5. 模型的上限性能:通过使用ground truth 2D关节检测数据作为输入,研究者可以评估模型在理想情况下的上限性能,即在没有2D检测误差时模型能够达到的最好结果。
在PoseFormer面临的挑战下, 作者主要提出了两个关键问题:
1. 如何有效地利用长关节序列获得更好的估计精度?
这个问题关注的是如何从视频序列中提取并利用长期的时间信息来提升3D人体姿态估计的准确性。在视频数据中,长关节序列包含了丰富的动态信息,可以帮助模型更好地理解人体运动和姿态变化。然而,处理这些长序列数据也带来了挑战,包括但不限于:
① 计算复杂性:长序列数据需要更多的计算资源,尤其是在应用自注意力机制时。
② 内存消耗:长序列可能导致模型的内存需求大幅增加。
③ 信息冗余:并非所有帧的信息都是对最终姿态估计至关重要的。
2. 如何增强模型对不可靠2D姿态检测的鲁棒性?
这个问题关注的是提高模型对2D姿态检测噪声的容忍度。在实际应用中,2D姿态检测器可能会因为遮挡、快速运动、复杂背景等因素产生误差。这些误差会对3D姿态估计的结果产生负面影响。
3.2 PoseFormerV2的改进
一些工作尝试通过引入手工设计的模块来解决这些问题,例如:
1. 下采样和上采样模块:只处理视频帧的一部分以提高效率。
2. 多假设模块:模拟身体部位的深度歧义和2D检测器的不确定性。
但是这些方法并不能同时解决上述的两个问题,例如多假设方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









