






参照完整性
一对多
1.例:1.客户和订单的关系就是一对多,一个客户可以有多张订单,一张订单属于一个客户:
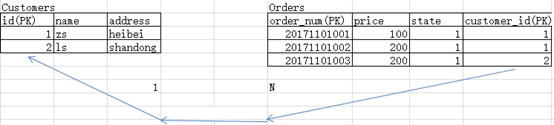
创建客户表:
CREATE TABLE customers(
id int,
name varchar(100),
address varchar(255),
PRIMARY KEY(id)
);
创建订单表:
CREATE TABLE orders(
order_num int primary key,
price float(8,2),
status int,
customer_id int,
CONSTRAINT customer_id_fk FOREIGN KEY(customer_id) REFERENCES customers(id)
);
其中,外键约束为:
constraint customer_id_fk foreign key(customer_id) references customers(id);
表示创建一个名叫customer_id_fk的外键约束,其中外键指的是customer_id,并且参照的是 customers表中的id列。
多对多
2.例:老师和学生是多对多关系, 一个老师对应多个学生,一个学生被多个老师教:
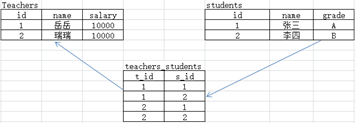
创建老师表:
Create table teachers(
id int,
name varchar(100)
salary float(8,2),
primary key(id)
);
创建学生表:
Create table students(
id int,
name varchar(100),
grade varchar(100),
primary key(id)
);
建立多对多的关系需要借助第三个表格来设置外键:
第三张表格:
Create table teacher_student(
t_id int,
s_id int,
primary key(t_id,s_id)
CONSTRAINT teacher_id_fk FOREIGN KEY(t_id) REFERENCES teachers(id),
CONSTRAINT student_id_fk FOREIGN KEY(s_id) REFERENCES students(id)
);
多表查询
交叉连接
1.笛卡儿积:显示第一个表格的所有行和第二个表格的所有行。
语法:
隐式语法(不使用关键字): select * from 表1,表2;
显式语法(使用关键字): select * from 表1 CROSS JOIN 表2;
注意:交叉连接结果集是不正确的。
内连接
因为交叉连接获得的结果集是错误的。因此内连接是在交叉连接的基础上
只列出连接表中与连接条件相匹配的数据行,匹配不上的记录不会被列出。
语法:
隐式语法:
select * from customers,orders where customers.id=orders.customer_id;
显式语法:
select * from customers c INNER JOIN orders o ON c.id=o.customer_id;
外连接
外链接是以一张表为基表,其他表信息进行拼接,如果有就拼接上,如果没有显示null; 外链接分为左外连接和右下连接。
左外连接: 以关键字左边的表格为基表进行拼接
语法: select * from customers c LEFT JOIN orders o ON c.id=o.customer_id;
右外连接: 以关键字右边的表格为基表
语法: select * from orders o RIGHT JOIN customers c ON c.id=o.customer_id;
子查询
当进行查询的时候,需要的条件是另外一个select语句的结果,这个时候就会用到子查询,为了给主查询(外部查询) 提供数据而首先执行的查询(内部查询)被叫做子查询; 子查询分为嵌套子查询和相关子查询。
1.嵌套子查询:
内部查询的执行独立于外部查询,内部查询仅执行一次,执行完毕后将结果作为外部查询的条件使用(嵌套子查询中的子查询语句可以拿出来单独运行。
例:建立一个老师与学生关系表;
(1)老师:
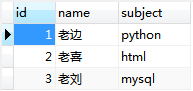
(2)学生:
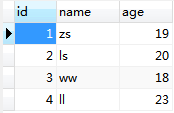
(3)关联表:
例如:查询出id为1的老师教过的所有学生。
select * from students where id in(select s_id from teacher_student where t_id=1);
内部只执行一次,找到t_id=1的结果,是s_id为1,2,然后以s_id=1,2为筛选学生姓名和其他信息;
2.相关子查询:
内部查询的执行依赖于外部查询的数据,外部查询每执行一次,内部查询也会执行一次。每一次都是外部查询先执行,取出外部查询表中的一个元组,将当前元组中的数据传递给内部查询,然后执行内部查询。根据内部查询执行的结果,判断当前元组是否满足外部查询中的where条件,若满足则当前元组是符合要求的记录,否则不符合要求。然后,外部查询继续取出下一个元组数据,执行上述的操作,直到全部元组均被处理完毕。
常用函数
聚合函数
1.count() :求满足列条件的总的行数。
2. sum(): 求总和。
3.avg(): 求平均数。
4.min() 和 max() 求最大值和最小值。
5.group by 分组.
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。分组函数忽略空值。
注意:
(1)分组函数的重要规则
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表 中的字段,要么出现在聚合函数里,要么出现在GROUP BY 子句中。
GROUP BY 子句的字段可以不出现在SELECT列表当中。
(2)、having where 的区别
①、where和having都是用来做条件限定的,
②、WHERE是在分组(group by)前进行条件过滤,
③、HAVING子句是在分组(group by)后进行条件过滤,
④、WHERE子句中不能使用聚合函数,HAVING子句可以使用聚合函数。
⑤、HAVING子句用来对分组后的结果再进行条件过滤
having sum(price)>2000 相当于 拿着 列名为sum(price)去查询。















 2444
2444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









