






前言
JOIN:mysql中用来进行连表操作,用来匹配两个表的数据,筛选合并出符合我们要求的结果集。
实验创建表:
create table student(
id int(11) not null,
number VARCHAR(20) default null,
username VARCHAR(20) default null,
primary key(id)
)engine=innodb default charset=utf8mb4;
create table score(
id int(11) not null,
number varchar(20) default null,
chinese double(4,0) default null,
math double(4,0) default null,
PRIMARY key(id)
)engine=innodb default charset=utf8mb4;
insert into student values(1,'10086','大师兄');
insert into student values(2,'10087','大祭祀');
insert into student values(3,'10088','大司马');
insert into student values(4,'10081','大将军');
insert into score values(1,'10086',99,60);
insert into score values(2,'10087',99,60);
insert into score values(3,'10089',78,100);提示:以下是本篇文章正文内容,下面案例可供参考
一、JOIN操作的方式
左外连接:
#左外连接,查询出左表的全部数据,以及右表相匹配的数据,不存在的用空表示。
explain
select * from student s1 left join score c1 on s1.number = c1.number;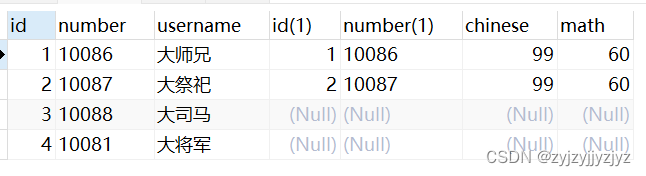
右外连接:
#右外连接,查询出右表的全部数据,以及左表相匹配的数据,不存在的用空表示。
explain
select * from student s1 right join score c1 on s1.number = c1.number; 
内连接:
#内连接,只获取两张表有交集的数据。
explain
select * from student s1 inner join score c1 on s1.number = c1.number; 
二、驱动表和被驱动表
1.什么是驱动表
1)多表关联查询的时候,第一个被处理的表就是驱动表,使用驱动表关联其他表。
2)驱动表的确定是非常关键的,会直接影响到多表关联的顺序,还有决定了后续的关联查询的查询。
通过explain执行计划,验证一下不同的连接查询情况下,驱动表的选择。
1)连接查询除连接条件外没有where的其他条件
左外连接
#左外连接时,驱动表的选择:左面的是驱动表,故student是驱动表
explain
select * from student s1 left join score c1 on s1.number = c1.number;
注意:按执行顺序,第一个表是驱动表。
右外连接
#右外连接时,驱动表的选择,后面的表示驱动表
explain
select * from student s1 right join score c1 on s1.number = c1.number; 内连接
内连接
#内连接,驱动表的选择:谁的数据少,谁就是驱动表
explain
select * from student s1 inner join score c1 on s1.number = c1.number;
2)连接查询有where条件(带where条件的表就是驱动表,否则就被驱动表)
#左外连接
explain
select * from student s1 left join score c1 on s1.number = c1.number where c1.id = 1;
上面的where条件是主键索引列,下面的是普通列,可以看出来驱动表还是where条件的表。
#左外连接
explain
select * from student s1 left join score c1 on s1.number = c1.number where c1.number = '10086';
右连接和内连接同理。
总结:驱动表的选择原则:在对最终的结果集没有影响的情况下,优先选择结果集小的那张表为驱动表。
三、JOIN算法原理
Simple Nested Loop JOIN 简单嵌套循环连接
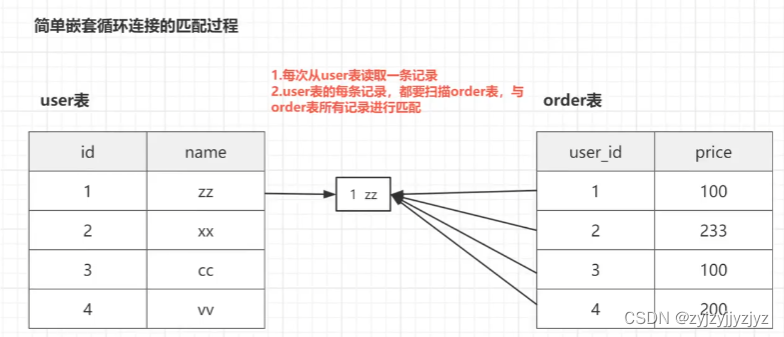
简单嵌套循环连接就是一个双层for循环,通过循环外层表的行数据,逐个与内层表的行数据进行比较来获取结果。
#连接用户与订单表,连接条件,用户表id=订单表的user_id
select * from user u left join order o on u.id = o.id;
#转换成代码后
for(URow : user表){
for(ORow : order){
if(URow.id = ORow.id){
return URow;
}
}
}
SNL的特点:
简单粗暴,容易理解,就是通过双层循环比较数据,获取结果。
查询效率非常低,假设A表有N行,B表有M行,SNL开销:N*M
Index Nested Loop join索引嵌套循环连接
与SNL的区别:减少了内层表的数据匹配次数,主要是因为在join字段(得是被驱动表中的用于连接的字段)上建立索引。
原理:减少了内循环的匹配次数,用INLJ后只需要3次io就可以匹配到。
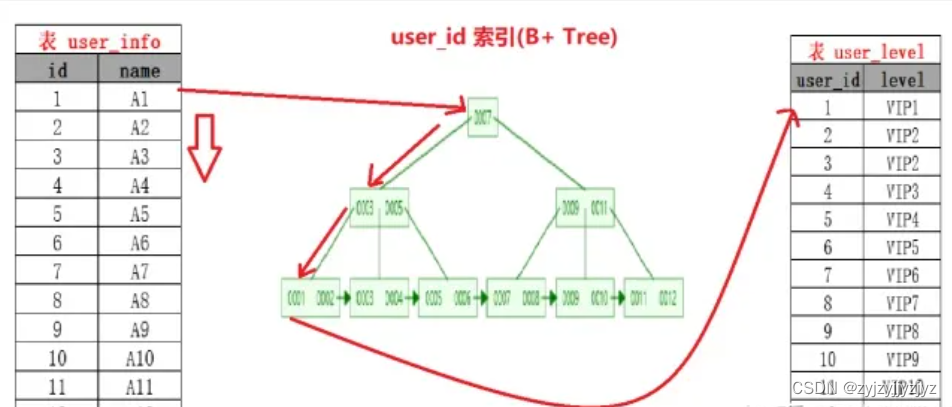
注意:使用Index Nested loop join算法,前提是被驱动表的匹配字段,必须建立索引。
Block Nested Loop Join(缓存块嵌套循环连接)
优化思路是减少内层表的扫表次数,通过简单的嵌套循环查询的图,我们可以看到,左表的每一条记录都会对右表进行一次扫表,这个过程其实是很消耗性能的。
bnlj算法是通过一次性缓存外层表的多条数据(用Join Buffer缓存),来减少外层循环次数,故此减少了内层表的扫表次数,从而达到提升性能的目的。
如果无法使用index nested loop join,数据库默认使用的是bnlj算法。
1、使用bnlj算法需要开启优化器的optimizer_switch的设置block_nested_loop为on,默认是开启的:
show variables like '%optimizer_switch%';

2、设置join buffer大小
通过join_buffer_size 参数可以设置join buffer的大小
show variables like '%join_buffer_size%';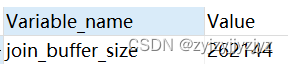
262144/1024 = 256Kb
已知一个页大小16Kb,能容纳256/16 = 16个页。
在被驱动表没有索引的情况下,使用的是bnlj(块嵌套循环)算法:
每次都从驱动表加载n个数据页(n<=join_buffer_size/1024/16),优化后左表io次数减少了
四、JOIN算法总结
INLJ是通过索引的机制减少内层表的循环匹配次数达到优化效果,BNLJ是通过一次缓存多条数据批量匹配的方式来减少外层表的io次数,同时也减少了内层表的扫表次数。
表连接的优化思路:
1、用小表(小结果集)驱动大表(大结果集)————本质上减少外层循环的数据数量
2、为被驱动表匹配的条件增加索引(减少内层循环的匹配次数)
3、增大join buffer size大小
4、减少不必要的字段查询(字段越少,join buffer缓存的数据越多)
五、关于join驱动表被驱动表加不加索引的执行计划情况
情况1:两个表都建索引,驱动表不会走索引,被驱动表会走索引。
explain
select * from student s inner join score c on s.number = c.number;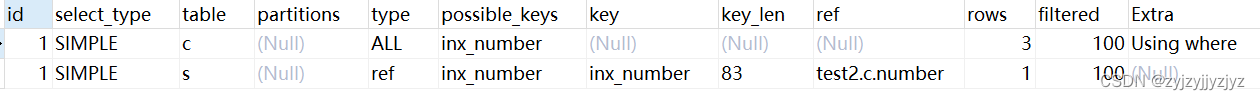
总结:驱动表因为是外循环所以是需要把所有数据取出来,所以全表扫描比较好。想要驱动表使用索引,需要有where子句,并且where的列需要有索引。
explain
select * from student s inner join score c on s.number = c.number where c.id=2;















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









