






order by优化
mysql中有两种排序方式:
- 索引排序:通过有序索引进行顺序扫描,直接返回有序的数据。
- 额外排序:对返回的数据进行文件排序。
order by优化的核心原则:尽量减少额外排序,使用索引的有序性,直接返回有序数据。
索引排序
在排序查询中,如果能利用索引,就能够避免额外的排序操作。并且expalin的extra=Using index
额外排序
除了索引排序的方式都是额外排序。extra=Using filesort。额外排序分为不同种类。
按照执行位置划分
1、sort_buffer
mysql中为每个线程各维护了一块内存区域(sort_buffer),用来进行排序。
show variables like '%sort_buffer_size%';
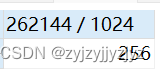
select 262144 / 1024;
注意:
1)sort_buffer_size就是sort_buffer的大小。
2)sort_buffer_size并不是越大越好,因为是connection级别的参数,也就是说每个连接mysql都会在内存开辟一个sort_buffer,高并发场景会造成系统资源的耗尽。
2、sort_buffer + 临时文件
如果加载的记录字段的总长度小于sort_buffer,就是用sort_buffer,否则就会采用sort_buffer+临时文件进行排序。
按照执行方式划分
执行方式:max_length_for_sort_data参数,如果用于排序的单表记录字段的长度<=该参数的值,就用全字段排序,否则就使用rowid排序。
show variables like '%sort_buffer_size%';

全字段排序:
将查询的所有字段全部加载进来进行排序。

优点:查询快,执行过程简单,缺点是需要的空间比较大。
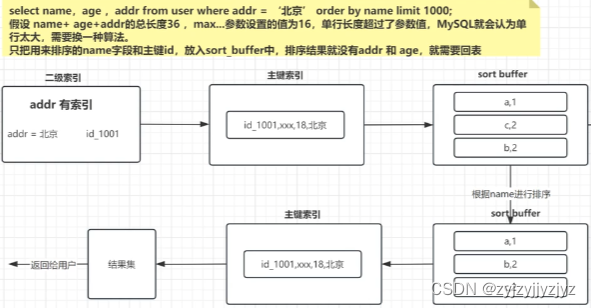
rowid排序:
rowid排序 不会将全部字段放入sort_buffer中,只放order by的字段和主键值,所以在sort_buffer中排序之后,还要回表查询。
排序总结:
- 如果内存够大,优先选择全字段排序。
- mysql的设计思想:多利用内存,尽量减少磁盘访问。
order by优化
情况1:联合索引的order by需要满足最左匹配原则
explain
select name,age from emp order by name ,age;
情况2:排序字段是多个索引,无法使用索引进行排序。
explain
select name ,sal from emp order by name ,sal;
未使用索引,进行了文件排序
情况3:排序的索引字段,没有出现在查询的字段列表中,不会利用索引排序。
explain
select sal from emp order by name;
explain
select * from emp order by name;
情况4:where条件是等值查询,不强制要求是索引列中的第一个字段,仍然可以利用索引排序。
explain
select name ,age from emp where age = 10 order by age;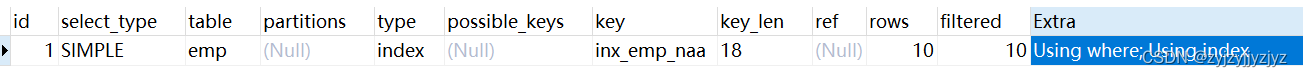
group by优化
group by一般用于分组统计
select name,count(*) from emp group by name; 问题1:group by一定要配合聚合函数吗
答:分组就是要做统计的,否则分组没有意义,所以要配合聚合函数使用,比如:count,sum,avg......
问题2:group by后面的字段,一定要出现在select列表中吗?
答:一定要出现。如果不出现分组就不知道哪个分组的值了。在标准的sql规范中,这点事必须的(mysql中没有强制规定,oracle中强制规定的)
问题3:where和having的区别
答:
group by+where
alter table emp add index inx_emp_sal(sal);
alter table emp add index inx_emp_age(age);
explain
select sal,count(*) from emp where age >20 group by sal;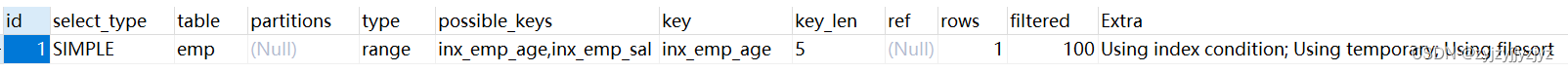 可以看到extra信息,使用到了临时表,也进行了文件排序。
可以看到extra信息,使用到了临时表,也进行了文件排序。
group by+having
explain
select sal,count(*) from emp group by sal having count(*) >=2; 删除sal列上的索引看执行计划,可以看出用到了临时表,为什么用临时表呢?下面解释
删除sal列上的索引看执行计划,可以看出用到了临时表,为什么用临时表呢?下面解释
drop index inx_emp_sal on emp;
explain
select sal,count(*) from emp group by sal having count(*) >=2;
where和having的区别:
- having子句用于分组后的筛选,where子句用于行条件的筛选。
- having都是配合分组和聚合函数一起出现。
- where子句中不能使用聚合函数。
group by原理分析
drop index inx_emp_sal on emp;
explain
select sal,count(*) from emp group by sal having count(*) >=2;问题: 为什么group by上的列没有索引,就需要文件排序?
答:
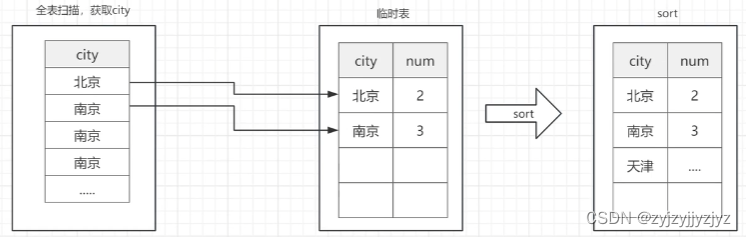
group by的执行流程
1)创建临时表,表中有两个字段,city、num(自动创建)
2)全表扫描emp表记录,依次取出city的记录
3)判断临时表中city的行记录,又该记录num就+1,没改记录就插入该记录
4)遍历完成之后,根据分组的字段city做排序,最终把排序结果返回客户端
mysql中的分组中为什么包含排序?
- 聚合函数的使用:排序可以快速找到最大和最小的值
- top n查询:排序后获取前n个值很快。
group by优化方案
方案1:合适的场景下,取消这个默认排序。
explain
select sal,count(*) from emp group by sal order by null;
方案2: 为group by字段添加索引。
explain
select sal,count(*) from emp group by sal 
方案3: 尽量使用内存表
如果group by需要统计的数据不多,可以尽量使用内存临时表,因为如果内存放不下,就会到磁盘临时表中,导致性能下降。
show global variables like '%tmp_table_size%';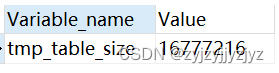
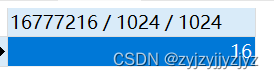
可以看到临时表的大小16M。可以设置临时表大小,在mysql配置文件中,[mysqld]下面添加:tmp_table_size=值,重启生效。
方案4:使用sql_big_result优化
如果数据特别大,数据就算放到临时表(临时表已经够大了),但是还是会因为数据的插入达到上先,在转成磁盘临时表,还是影响数据库性能。
如果与数据量比较大,我们使用SQL_BIG_RESULT直接提示mysql直接使用磁盘临时表。
- 禁用内存优化的情况
- 使用与大结果集的情况
一旦添加了SQL_BIG_RESULT,mysql就不会再用B+树结构存储临时表数据,存储效率低,会选择使用数组,直接用数据存储。
explain
select sal,count(*) from emp where age >20 group by sal;
explain
select SQL_BIG_RESULT sal,count(*) from emp where age >20 group by sal;
可以看到加入SQL_BIG_RESULT后没有使用临时表。















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









