







算法参见http://cs229.stanford.edu/notes/cs229-notes7a.pdf
function y=K_mean(data,k)
[r,c]=size(data);
%r : 数据的总数
%c: 每个数据的特征的个数
initcen=ones(k,c); %预分配initial center
initcen_cur=initcen; % current initial center
dis=ones(r,k); % distance
diff=ones(k,1);
for i=1:k
initcen(i,:)=data(ceil(r*rand),:); %随机生成k个初始中心点,(在数据集中选取)
end
while sum(diff)>0.1
for i=1:k
initvec=ones(r,1)*initcen(i,:); %将k个中心点扩展为r*c的矩阵
for j=1:r
dis(j,i)=norm(data(j,:)-initvec(j,:)); %dis是r*k 矩阵,每个数据到每个中心点的距离
end
end
[minval,tag]=min(dis'); %min按列找最小值
data_tag=[data,tag']; %给data增加一个tag的维度,即(c+1)列
for i=1:k
initcen_cur(i,:)=mean(data(find(data_tag(:,c+1)==i),:));
diff(i,:)= sum(abs(initcen_cur(i,:)-initcen(i,:)));
end
initcen=initcen_cur; %循环迭代
end
y=[initcen,[1:k]']; %第c+1列为最后收敛中心的标号[100,3]=size(data)
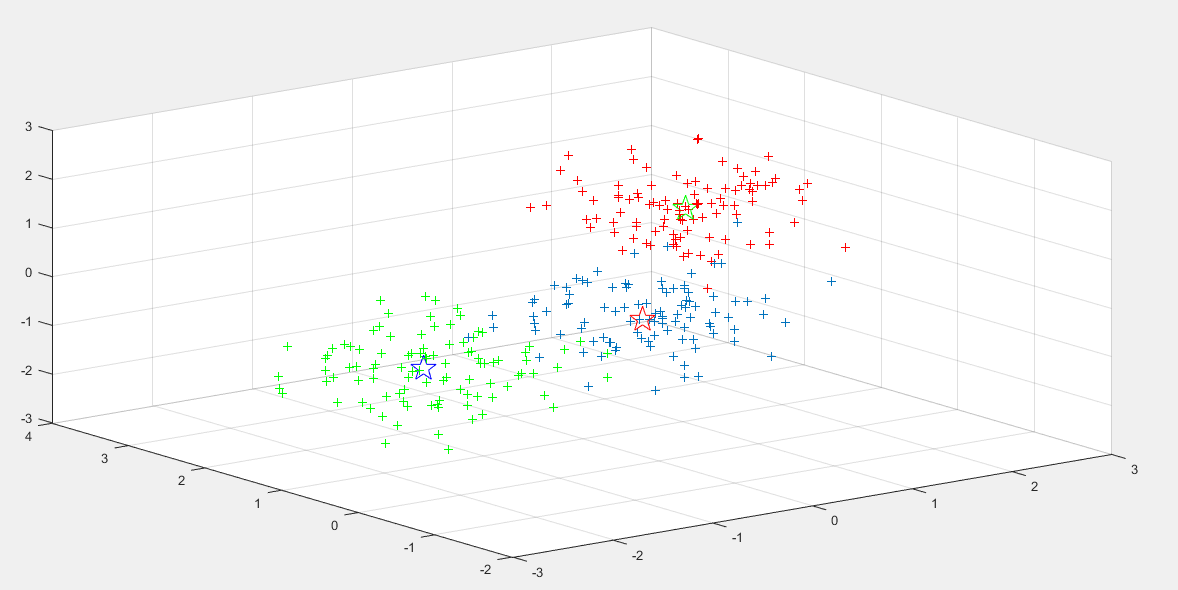
k=3
数据测试














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









