







adjust_gamma的使用方式
torchvision.transforms.functional.adjust_gamma(img: Tensor, gamma: float, gain: float = 1)
输入:
- img (PIL Image or Tensor) – PIL Image to be adjusted. If img is torch Tensor, it is expected to be in […, 1 or 3, H, W] format, where … means it can have an arbitrary number of leading dimensions. If img is PIL Image, modes with transparency (alpha channel) are not supported.(输入是tensor或PIL类型,注意当torchvision版本较低时输入只能是PIL类型)
- gamma (float) – Non negative real number, same as in the equation. gamma larger than 1 make the shadows darker, while gamma smaller than 1 make dark regions lighter.
- gain (float) – The constant multiplier. default = 1.
输出:
- gamma校正后的图像
官方文档中给出的计算过程:
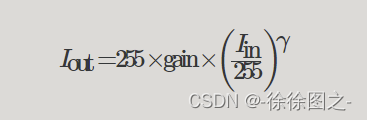
(来源:https://pytorch.org/vision/master/generated/torchvision.transforms.functional.adjust_gamma.html)
根据源码剖析注意点
(以下源码使用的是torchvision 0.10.0版本,增加了自己的注释)
def adjust_gamma(img: Tensor, gamma: float, gain: float = 1) -> Tensor:
r"""Perform gamma correction on an image.
Also known as Power Law Transform. Intensities in RGB mode are adjusted
based on the following equation:
.. math::
I_{\text{out}} = 255 \times \text{gain} \times \left(\frac{I_{\text{in}}}{255}\right)^{\gamma}
See `Gamma Correction`_ for more details.
.. _Gamma Correction: https://en.wikipedia.org/wiki/Gamma_correction
Args:
img (PIL Image or Tensor): PIL Image to be adjusted.
If img is torch Tensor, it is expected to be in [..., 1 or 3, H, W] format,
where ... means it can have an arbitrary number of leading dimensions.
If img is PIL Image, modes with transparency (alpha channel) are not supported.
gamma (float): Non negative real number, same as :math:`\gamma` in the equation.
gamma larger than 1 make the shadows darker,
while gamma smaller than 1 make dark regions lighter.
gain (float): The constant multiplier.
Returns:
PIL Image or Tensor: Gamma correction adjusted image.
"""
if not isinstance(img, torch.Tensor):
return F_pil.adjust_gamma(img, gamma, gain)
return F_t.adjust_gamma(img, gamma, gain)
其中F_t.adjust_gamma的代码如下:
def adjust_gamma(img: Tensor, gamma: float, gain: float = 1) -> Tensor:
if not isinstance(img, torch.Tensor):
raise TypeError('Input img should be a Tensor.')
# 判断输入图像的倒数第三个通道是否为1或者3,这部分要求在上文使用方式中已经提到
_assert_channels(img, [1, 3])
if gamma < 0:
raise ValueError('Gamma should be a non-negative real number')
result = img
dtype = img.dtype
# 如果输入图像的类型不是浮点型则需要转化为torch.float32类型,并归一化(除以该类型的最大值转换为0~1范围),具体可以参考下面`convert_image_dtype`的代码
if not torch.is_floating_point(img):
result = convert_image_dtype(result, torch.float32)
# 注意此处输入的result应该是0~1范围
result = (gain * result ** gamma).clamp(0, 1)
# 如果输入图像的类型不是浮点型,则在此步骤中会乘以其原本类型对应的最大值(如uint8类型便是乘以255),即输出的范围与输入一样
result = convert_image_dtype(result, dtype)
return result
其中convert_image_dtype的代码如下:
def convert_image_dtype(image: torch.Tensor, dtype: torch.dtype = torch.float) -> torch.Tensor:
if image.dtype == dtype:
return image
if image.is_floating_point():
if torch.tensor(0, dtype=dtype).is_floating_point():
return image.to(dtype)
if (image.dtype == torch.float32 and dtype in (torch.int32, torch.int64)) or (
image.dtype == torch.float64 and dtype == torch.int64
):
msg = f"The cast from {image.dtype} to {dtype} cannot be performed safely."
raise RuntimeError(msg)
eps = 1e-3
max_val = _max_value(dtype)
result = image.mul(max_val + 1.0 - eps) # 乘以最大值还原
return result.to(dtype)
else:
input_max = _max_value(image.dtype)
if torch.tensor(0, dtype=dtype).is_floating_point():
image = image.to(dtype)
return image / input_max # 除以最大值归一化
output_max = _max_value(dtype)
if input_max > output_max:
factor = int((input_max + 1) // (output_max + 1))
image = torch.div(image, factor, rounding_mode='floor')
return image.to(dtype)
else:
factor = int((output_max + 1) // (input_max + 1))
image = image.to(dtype)
return image * factor
看完了源码,可以发现其中有一个容易被忽略的坑:
输入如果是float,则默认输入范围为0~1
输入如果是uint8,则默认输入范围为0~255
也就是说,如果输入是0~255的float型,则adjust_gamma会将输入当作范围为0 ~ 1来对待,输出的范围也是0 ~ 1,但我们却可能误以为输出是0 ~ 255的,导致之后的一系列错误。
举一个直观的例子:
from torchvision.transforms.functional import adjust_gamma
img = torch.rand((3,4,4)) * 255 # torch.rand生成[0, 1)的随机数,*255之后是0~255范围的float型
img_gamma = adjust_gamma(img, random.uniform(0.3, 0.7))
print(img)
print(img_gamma)
输出:
tensor([[[144.6765, 134.3208, 122.1481, 75.6207],
[ 4.3333, 121.7625, 132.8604, 128.8029],
[144.2919, 51.2689, 177.2873, 19.5260],
[125.2977, 31.0344, 35.3149, 251.4274]],
[[ 74.2166, 236.5022, 74.3550, 118.2496],
[126.0812, 221.0599, 86.6827, 41.8263],
[186.3450, 137.9159, 83.8027, 168.9428],
[120.4041, 187.6483, 67.4965, 206.5327]],
[[229.5066, 247.4427, 100.7691, 134.6318],
[220.0865, 152.7486, 132.1260, 149.1300],
[139.2620, 23.8025, 180.3390, 103.8246],
[ 50.4213, 45.8973, 125.0840, 7.6014]]])
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
可以看到此时输出最大为1,与输入的范围不符
正确的用法:
1、输入0~1范围的float型
from torchvision.transforms.functional import adjust_gamma
img = torch.rand((3,4,4)) # torch.rand生成[0, 1)的随机数
img_gamma = adjust_gamma(img, random.uniform(0.3, 0.7))
print(img)
print(img_gamma)
# 输出:
tensor([[[2.0054e-01, 8.4895e-01, 9.9618e-01, 9.2060e-02],
[6.4187e-01, 3.4642e-04, 1.9543e-01, 4.5496e-01],
[4.1164e-01, 5.6198e-01, 1.2069e-01, 5.1976e-01],
[4.1374e-02, 6.6692e-01, 3.3000e-01, 1.1573e-01]],
[[3.2046e-01, 9.7046e-01, 6.4137e-01, 9.8334e-01],
[2.9510e-01, 3.0055e-02, 7.3637e-01, 7.7969e-01],
[7.4160e-01, 5.1506e-01, 1.6576e-01, 5.9945e-01],
[4.9224e-01, 1.9660e-01, 1.4290e-01, 2.9252e-01]],
[[6.6981e-01, 1.5963e-01, 6.7751e-01, 2.9439e-02],
[6.3300e-01, 5.3336e-02, 9.2091e-01, 9.7790e-01],
[4.4257e-01, 6.8394e-01, 8.9644e-01, 3.7795e-01],
[1.1071e-01, 7.5518e-01, 7.6905e-02, 7.1750e-01]]])
tensor([[[0.4428, 0.9203, 0.9981, 0.2984],
[0.7987, 0.0176, 0.4370, 0.6708],
[0.6376, 0.7466, 0.3423, 0.7176],
[0.1989, 0.8143, 0.5700, 0.3351]],
[[0.5616, 0.9849, 0.7984, 0.9915],
[0.5386, 0.1692, 0.8563, 0.8815],
[0.8594, 0.7143, 0.4020, 0.7715],
[0.6981, 0.4384, 0.3729, 0.5362]],
[[0.8161, 0.3944, 0.8209, 0.1674],
[0.7931, 0.2262, 0.9591, 0.9887],
[0.6615, 0.8248, 0.9461, 0.6106],
[0.3276, 0.8673, 0.2724, 0.8451]]])
2、输入0~255范围的uint8型
from torchvision.transforms.functional import adjust_gamma
img = torch.randint(0,255,(3,4,4), dtype=torch.uint8) # 生成0~255的随机数,注意类型需为uint8,否则会报错
img_gamma = adjust_gamma(img, random.uniform(0.3, 0.7))
print(img)
print(img_gamma)
# 输出:
tensor([[[ 19, 1, 34, 206],
[137, 143, 117, 58],
[114, 36, 46, 119],
[ 70, 109, 27, 87]],
[[ 97, 189, 29, 223],
[232, 243, 203, 93],
[ 40, 105, 191, 46],
[183, 103, 164, 133]],
[[ 72, 233, 215, 228],
[216, 147, 155, 111],
[175, 12, 210, 31],
[230, 142, 198, 73]]], dtype=torch.uint8)
tensor([[[ 60, 11, 83, 227],
[181, 185, 165, 112],
[163, 85, 98, 167],
[124, 159, 73, 140]],
[[149, 216, 76, 237],
[242, 249, 225, 145],
[ 91, 156, 217, 98],
[212, 154, 200, 178]],
[[126, 243, 232, 240],
[233, 188, 193, 160],
[207, 46, 229, 79],
[241, 184, 222, 127]]], dtype=torch.uint8)















 3081
3081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









