









1、实验目的与环境
1.1实验目的
搭建
hadoop
分布式集群
1.2实验环境
Linux
版本:
Centos6.5
Jdk
版本:
jdk7
Hadoop
版本:
hadoop2.6
使用工具:
SecureCRT,vmware12
2、步骤
2.1配置网络环境
(1)
安装完成三台
centos
机器后,为它们分别配置网络环境。
虚拟机网络配置选用
vmnet0
,通过
setup
命令设置静态
ip
和
dns
服务器。
如下:
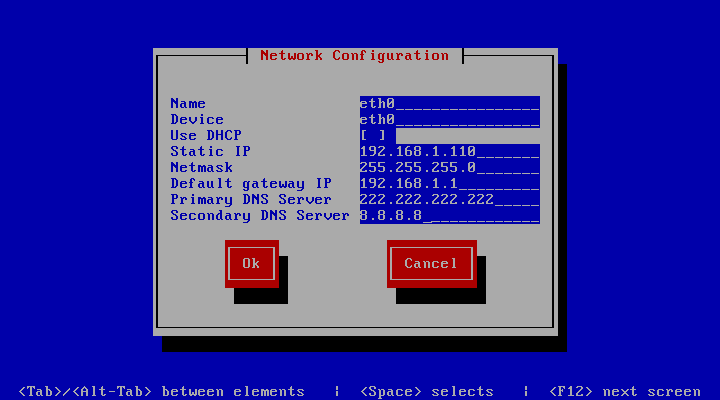
分别为三台机器配置
ip
为
192.168.1.110
,
192.168.1.111
,
192.168.1.112
(2)
开启
eth0
的网卡。
输入命令如下:
vim /etc/sysconfig/network-scripts/ifcfg-eth0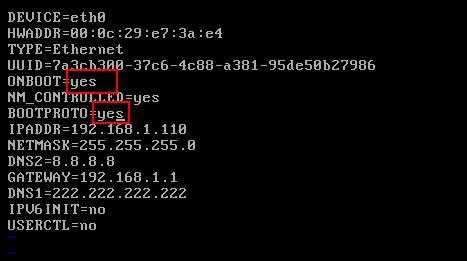
将
eth0
网卡的
ONBOOT=no
修改为
ONBOOT=yes
将
BOOTPROTO=no
修改为
BOOTPROTO=yes
完成后重启网卡:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
(3)
输入
ifconfig
测试。
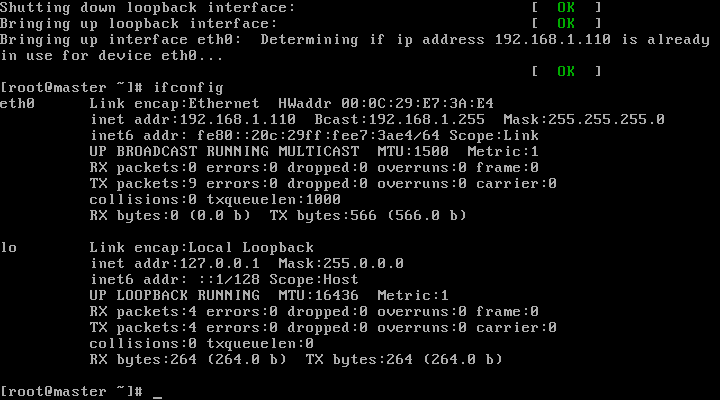
说明网络配置成功。
(
4
)
同理,另外两台机器也是一样的方式配置。完成网络的配置后就可用
SecureCRT
工具进行远程登录了。
(
5
)
Centos
默认情况下的防火墙会阻止机器间进行通信,也不会开放
hadoop
用到的端口。所以为了方便,这里直接将防火墙关闭。
临时关闭防火墙命令:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
若想永久关闭防火墙,可输入命令:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
(6)修改主机名并添加域名映射
本次实验
hadoop
分布式由三台
centos
组成,其中一台作为主节点
master
,另外两台作为从节点
slave
,所以为了更直观,分别修改主机名为
master
,
slave1
,
slave2.
输入
hastname
可以查看当前机器名字。
修改主机名方式:
vim /etc/sysconfig/network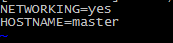
将
hostname
修改为需要的名字。
添加域名映射,需要修改
/etc/hosts
文件。输入:
vim /etc/hosts
在每台机器都执行如上操作并添加如图所示的三句,使得对应的主机名能与ip映射。

完成域名映射后,就可以使用其中一台机器直接通过名字ping通另外两台机器了。
2.2
建立集群间的
SSH
无密钥认证
SSH
的配置并不是必须的步骤,但是后续的操作需要在机器间传送文件或者集群在启动过程中需要启动从节点,为避免频繁输入密码,可以配置
SSH
无密钥认证。
配置过程:
(1)在每台机器输入:
ssh-keygen -t rsa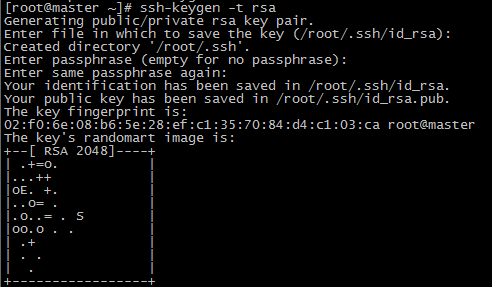
(2)
在每服务器上将公钥复制到需要免验证登录的服务器上
进入ssh目录:
cd ~/.ssh
类似下面在各台机上依次输入:
ssh-copy-id -i id_rsa.pub "-p 22 root@slave1"
ssh-copy-id -i id_rsa.pub "-p 22 root@slave2"
ssh-copy-id -i id_rsa.pub "-p 22 root@master"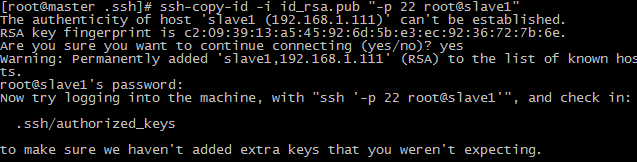
(3)测试
完成配置后,可通过
ssh
主机名的方式尝试登录到另一台机器,如果不需要输入密码即可登录,所以配置成功。

创建新的用户hadoop,使用
useradd hadoop
新建用户,使用
passwd hadoop
为新用户设置密码。并且可以为
hadoop
用户配置
ssh
免密钥登录。方式同上。这样使用
hadoop
用户时使用
scp ssh
等相关命令时可以不需要频繁输入密码。
2.3
安装
JDK
(1)下载jdk
Centos
自带
openjdk
,一般不使用自带的jdk版本。可以自己卸载,并安装自己下载的
jdk
。可以去
oracl
e官网下载jdk的
rpm
包或者
gz
包。本次实验的
jdk
版本为
1.7
。我下载的是
jdk-7u79-linux-x64.gz
并通过
SecureCRT
工具的
sftp
功能将该包传输到
master
的
/user/local
目录下。
(2)解压
tar -zxvf jdk-7u79-linux-x64.gz
(3)设置环境变量
vim /etc/profile
在该文件尾添加jdk安装目录并添加到path如下:

刚配置完的环境变量并不会立即生效,可以重启或者输入如下命令让其立即生效:
source /etc/profile- 测试
输入
java -version
,如果出现如下界面,说明配置成功。

2.4
搭建
hadoop
环境
(1)下载
hadoop
安装包
可以去
hadoop
官网下载。本次实验我用的
hadoop
版本为
hadoop-2.6.0
。同样使用
sftp
将该文件复制到
master
的
hadoop
用户目录下,即
/home/hadoop
。

(2)解压
source /etc/profile
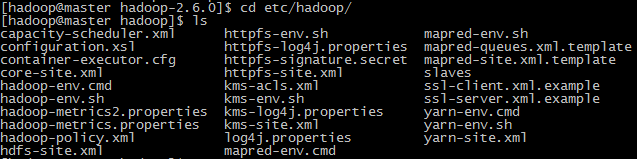
(3)配置
hadoop-env.sh
进入安装目录下的
etc/hadoop
,可以看到有许多配置文件,接下来就是要对其中的文件进行修改配置。
修改
hadoop-env.sh
下
hadoop
的jdk变量配置:
vim hadoop-env.sh
将
JAVA_HOME
的值改为具体的
jdk
安装位置。

改为:

(4)修改
core-site.xml
在
<configuration>
标签中添加如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0/tmp</value>
</property>
</configuration>
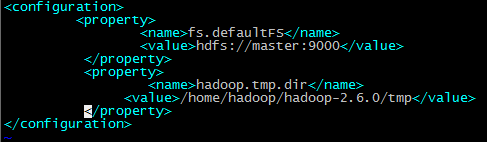
其中第一个配置的是hdfs的访问路径,第二个配置的是数据文件存放的路径。
(5)修改
mapred-site.xml
由于
hadoop
默认提供的是样本文件,名字为:
mapred-site.xml.template
,并不会起效,所以需要修改该文件名字,再进行配置。
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在
<configuration>
标签中添加如下内容:
<configuration>
<property>
<name>mapreduce.framawork.name</name>
<value>yarn</value>
</property>
</configuration>

选用
mapreduce
的资源调度
yarn
。
(6)修改
yarn-site.xml
在
<configuration>
标签中添加如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
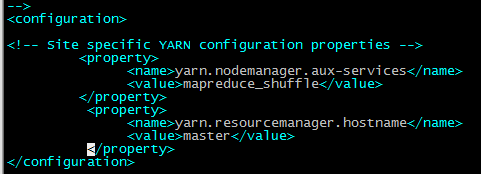
配置资源主服务器的位置和相应的策略。
(7)修改
hdfs-site.xml
在
<configuration>
标签中添加如下内容:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-2.6.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.6.0/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
配置
dfs
副本的数量以及相关
datanode
和
namenode
存放路径。
(8)修改
slaves
文件
vim /home/hadoop/hadoop-2.6.0/etc/hadoop/slaves
删除原有内容,并添加如下:

这个文件是配置从节点的。我的从节点是名字为
slave1
和
slave2
的两台机器。
如果你没有配置ip与域名映射,这里就必须写具体的ip地址。
(9)将配置好的
hadoop-2.6.0
文件夹通过
scp
发送给另外两台
slave
机器的
/home/hadoop
目录下。
由于我用hadoop用户配置了ssh,所以这一步不需要输入密码验证
scp -r hadoop-2.6.0/ hadoop@slave1:/home/hadoop/
scp -r hadoop-2.6.0/ hadoop@slave2:/home/hadoop
-r表示传输的是文件夹
(10)修改环境变量
切换回
root
用户,输入:
vim /etc/profile
,修改如下:

三台机器做同样修改
输入
source /etc/proflie
让配置立即生效。
到此。整个
hadoop
的环境配置基本完成了。
3、测试集群
第一次启动需要格式化主节点命名空间。
输入命令:
hadoop namenode -format
启动集群,可以分别启动
dfs
和
yarn
:
start-dfs.sh
和
start-yarn.sh
也可以一次性启动:
start-all.sh
如果没有配置
hadoop
的
path
环境变量,需要进入hadoop安装目录的sbin下运行该命令。
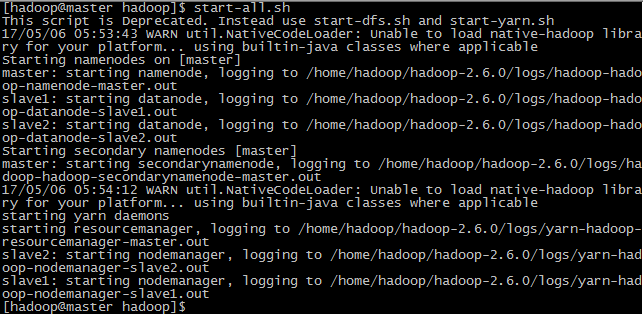
可以看到在启动过程相继启动了
salve1
和
slave2
这两台机器的
datanode
,由于配置了
ssh
,所以这一步无需输入密码。
分别在三台机器上输入jps查看当前进程:
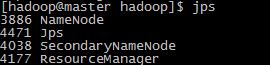


可以看到,
Namenode
服务节点和资源服务都位于主节点
master
机上,而
dataNode
数据节点位于两台从节点机器上。
测试文件上传:
将原先
master
机上的
hadoop
压缩包上传

输入
hadoop
的
hdfs
命令:
hadoop fs -put hadoop-2.6.0.tar.gz hdfs://master:9000/
将该文件上传到
hdfs
文件系统。
输入:
hadoop fs -ls /
查看
hdfs
上的文件情况:

同样,
slave
机器上也能看到相同的文件,说明集群搭建成功。

打开电脑本机的浏览器,输入:
http://192.168.1.110:50070/
(由于
window
系统并没有配置
master
与其
ip
的映射,所以这里必须使用具体
ip
地址访问)
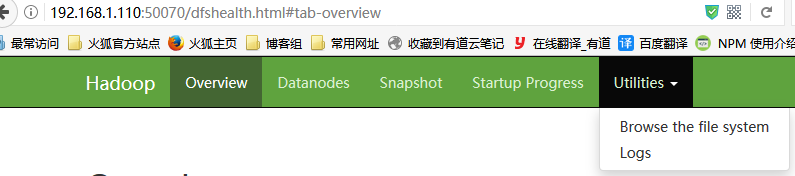
点击
Utilities
下的
Browse the file system
,可以查看到刚刚上传的文件。

这说明集群搭建成功了。















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









