







概述
GTID (Global Transaction ID)是全局事务ID,当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,对DBA来说意义就很大了,我们可以适当的解放出来,不用手工去可以找偏移量的值了,而是通过CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION=1的即可方便的搭建从库,在故障修复中也可以采用MASTER_AUTO_POSITION=‘X’的方式。
可能大多数人第一次听到GTID的时候会感觉有些突兀,但是从架构设计的角度,GTID是一种很好的分布式ID实践方式,通常来说,分布式ID有两个基本要求:
1)全局唯一性
2)趋势递增
这个ID因为是全局唯一,所以在分布式环境中很容易识别,因为趋势递增,所以ID是具有相应的趋势规律,在必要的时候方便进行顺序提取,行业内适用较多的是基于Twitter的ID生成算法snowflake,所以换一个角度来理解GTID,其实是一种优雅的分布式设计。
1。如何开启GTID
如何开启GTID呢,我们先来说下基础的内容,然后逐步深入,通常来说,需要在my.cnf中配置如下的几个参数:
①log-bin=mysql-bin
②binlog_format=row
③log_slave_updates=1
④gtid_mode=ON
⑤enforce_gtid_consistency=ON
其中参数log_slave_updates在5.7中不是强制选项,其中最重要的原因在于5.7在mysql库下引入了新的表gtid_executed。
在开始介绍GTID之前,我们换一种思路,通常我们都会说一种技术和特性能干什么,我们了解一个事物的时候更需要知道边界,那么GTID有什么限制呢,这些限制有什么解决方案呢,我们来看一下。
GTID的限制
如果说GTID在5.6试水,在5.7已经发展完善,但是还是有一些场景是受限的。比如下面的两个。
一个是create table xxx as select 的模式;另外一个是临时表相关的,我们就来简单说说这两个场景。
1)create 语句限制和解法
create table xxx as select的语句,其实会被拆分为两部分,create语句和insert语句,但是如果想一次搞定,MySQL会抛出如下的错误。
mysql> create table test_new as select *from test;
ERROR 1786 (HY000): Statement violates GTID consistency: CREATE TABLE ... SELECT.
这种语句其实目标明确,复制表结构,复制数据,insert的部分好解决,难点就在于create table的部分,如果一个表的列有100个,那么拼出这么一个语句来就是一个工程了。
除了规规矩矩的拼出建表语句之外,还有一个方法是MySQL特有的用法 like。
create table xxx as select 的方式可以拆分成两部分,如下。
create table xxxx like data_mgr;
insert into xxxx select *from data_mgr;
2)临时表的限制和建议
使用GTID复制模式时,不支持create temporary table 和 drop temporary table。但是在autocommit=1的情况下可以创建临时表,Master端创建临时表不产生GTID信息,所以不会同步到slave,但是在删除临时表的时候会产生GTID会导致,主从中断.
从三个视角看待GTID
前面聊了不少GTID的内容,我们来看看GTID的一个体系内容,如下是我梳理的一个GTID的概览信息,分别从变量视图,表和文件视图,操作视图来看待GTID.
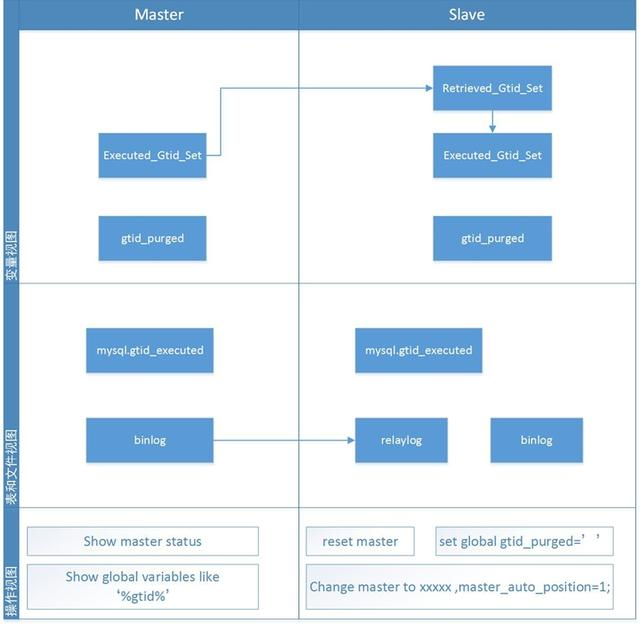
我们分别从每个视图来简单说下:
1)变量视图
我们来用下面的表格来阐述下常见的这几个变量

注意:Executed_Gtid_Set是当前MySQL上执行过的所有GTID集合(包括自身节点上的事务,也包括从主节点复制过来的事务)
2)表和文件视图
先来说下文件层面的关联,根据MySQL的复制原理,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog,主从同步时GTID_Event和事务的Binlog都会传递到从库,在从库应用Relay Log,从库在执行的时候也是用同样的GTID写binlog.
然后说一下表mysql.gtid_executed,在5.6版本中必须要设置log_slave_updates,因为当slave重启后,无法得知当前slave已经运行到的GTID位置,因为变量gtid_executed是一个内存值,而这个问题在5.7中通过表mysql.gtid_executed把这个值持久化来得以解决,也就意味着log_slave_updates是一个可选项。(log_slave_updates开启后,mysql.gtid_executed表中的数据库不会实时更新,只有等flush binlog或者binlog文件切换时才会将最新的数据库更新到表mysql.gtid_executed中)
此外,引入该解决方案之后又带来了新的问题,那就是在gtid_executed里面的数据会越来越多,如何精简管理呢,MySQL引入了一个新的线程和参数来进行管理。
线程为:thread/sql/compress_gtid_table,可以查询performance_schema.threads来查看。
参数为 gtid_executed_compression_period ,主要用于控制每执行多少个事务,对表gtid_executed进行压缩,默认值为:1000 。
3)操作视图
对于操作,我们列举了较为简单常规的操作方式,为了避免歧义,我对一些命令做了取舍。
实际演示
环境介绍
| IP | 操作系统 | 数据库版本 | 用途 |
| 192.168.43.201 | CentOS 7.7 x64bit | MySQL 8.0.18,已有数据 | 作为Master主节点 |
| 192.168.43.203 | CentOS 7.7 x64bit | MySQL 8.0.18,全新库 | 作为201的Slave从节点 |
主从复制环境,应保证操作系统和数据库版本一致,减少出问题的概率。
主Master节点(IP:43.201)
1、Master节点配置文件
确保Master 和 Slave 的 server_id 不能相同,并且Master开启binlog二进制日志(设置文件名前缀为binlog),并在每次commit的同时sync写到binlog文件中。因此编辑/etc/my.cnf文件,增加配置(重点是gtid-mode和enforce-gtid-consistency)。
[mysqld]
server_id=201
log_bin=binlog
sync_binlog=1
gtid-mode=ON
enforce-gtid-consistency=ON
binlog_rows_query_log_events=ON
#binlog_format参数从8.1版起标记为废弃,未来只支持ROW类型
binlog_format=ROW
#另外还有其他参数,酌情选择设置
#log_bin_trust_function_creators=ON # 是否同步函数(默认OFF)
#binlog_expire_logs_seconds=2592000 #binlog日志文件留存多少秒(默认为30天,之前的expire_logs_day参数已经作废。)
#binlog_cache_size=1M #默认32K,根据业务繁忙程度设置,通常1~4MB
注1:配置文件中参数中的“中划线”和“下划线”都可以。无论是哪种划线(甚至混合也可以),最后显示的变量都是下划线。
注2:对于老版本MySQL5.x,关闭binlog使用“log_bin=OFF”或者“log_bin=0”即可关闭。在MySQL8中,这种方式已无法关闭binlog,需要使用:“disable_log_bin”配置关闭。
然后重启主节点的mysqld服务。
2、创建Slave连接用的用户
在Master节点上,创建一个用户,用于数据同步Slave从节点连接Master的用户。 (限制该用户只能从本局域网登录)
mysql> CREATE USER 'repl'@'192.168.43.%' IDENTIFIED BY 'Repl_999';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.43.%';
Query OK, 0 rows affected (0.00 sec)3、备份Master节点,作为Slave的初始数据
【注】因复制只复制关联建立后的数据,对于之前的数据不会复制。所以需要人工通过备份恢复方式,形成主、从机器的初始数据时一致的。
备份的方式可以多样:
- 如果数据量不大,备份耗时可以接收,则使用mysqldump工具进行逻辑备份。
- 如果数据量比较大备份耗时,且Master节点可以停止,在停止后使用操作系统文件拷贝传输至Slave节点进行物理备份(这种方式最快)。
下文以mysqldump方式进行说明。
a、为保证备份期间数据一致性,对主库执行以下命令,将主库设置为禁止写操作。
mysql> FLUSH TABLES WITH READ LOCK;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL read_only=ON;
Query OK, 0 rows affected (0.00 sec)注:①set global read_only是全局级别的参数(不是锁),置为ON之后,普通用户只能读不能写,具有super权限的用户仍可以写。 此属性设置在从节点上,不会影响binlog的relay和应用,既在从节点上设置此属性为只读,从节点salve仍然会读取master上的日志,并且在slave库中应用日志,保证主从数据库同步一致。
②FLUSH TABLES WITH READ LOCK(FTWRL)是表级别的锁(tables指所有表,还可以指定具体的表),执行之后,包括具有super权限的所有用户都不能写表。一直锁定直到unlock。 在从节点执行FTWRL后,由于表都被锁住,从节点对binlog的relay应用也无法写到表中,影响从节点的数据同步。 因此FTWRL通常仅在临时彻底只读时使用。
b、全库备份。
[zyplanke@centosb ~]$ mysqldump -h 192.168.43.201 -u root -p --all-databases --single-transaction > dump_of_master.sql
Enter password:
[zyplanke@centosb ~]$ ls -l dump_of_master.sql
-rw-rw-r--. 1 zyplanke zyplanke 15943508 May 6 00:11 dump_of_master.sqlc、备份完毕后,对主库执行以下命令,恢复Master主节点写操作。
mysql> SET GLOBAL read_only=OFF;
Query OK, 0 rows affected (0.00 sec)
mysql> UNLOCK TABLES;
Query OK, 0 rows affected (0.00 sec)从Slave节点(IP:43.203)
1、Slave节点配置文件
Slave 的 server_id 不能与主节点相同。
[mysqld]
server_id=203
read_only=ON
gtid-mode=ON
enforce-gtid-consistency=ON注:若从节点不用于写入用途,则将从节点设置为只读(如上)。 若从节点将用于写入用途,则不要设置为只读,并且开启写从节点自身的binlog(既log_bin=binlog和sysc_binlog=1两个参数)。从节点自身的binlog记录的是写操作对从节点的自身binlog,而不是从主节点复制过来的relaylog。
注:如果从节点可能接替Master,升为主节点,则Slave节点的应设置为read_only=OFF。
如果已经启动了GTID模式,还需要删除从节点datadir目录下的auto.cnf文件(删除后,重启时会自动新生成UUID),避免与主节点具有相同的UUID。
然后重启从节点的mysqld服务。 (如果重启之前已经配置了同步设置,则在配置文件中增加skip-slave-start参数,这样启动后不会立即从主库上进行同步。)
2、Slave从库导入
[zyplanke@centosb ~]$ mysql -h 192.168.43.203 -u root -p < dump_of_master.sql
Enter password: 注:即使将从库设置read_only属性,也能导入成功,因为导入使用的root用户具有super权限。 read_only不限制具有super权限的用户进行写操作。
导入完毕后,检查导入后的数据库。
3、从库同步设置
在43.203从库中,执行以下语句连接到master主库:
如果之前已经配置了复制,则应先执行:
stop slave ;
reset slave all;
然后再执行以下语句:
mysql> change master to
master_host='192.168.43.201',
master_port=3306,
master_user='repl',
master_password='Repl_999',
master_auto_position=1;
(以上命令还可以增加:for channel 'channel_201_3306'; 设置channel的名字。 不显示设置名字则为默认channel名。)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)启动slave后,立即能看到slave的状态
注意:MySQL8.0.18可能存在bug:在相同的MySQL版本且密码正确的情况下,从库仍会一致处于connecting状态,且错误信息为:Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection。 按道理应该能正常连上才对。 解决这个bug,可以在从库服务器上,人为先使用mysql客户端远程连接一次主库然后退出。 然后在从库上重启slave就能正常连上。
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.43.201
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000034
Read_Master_Log_Pos: 924
Relay_Log_File: centosb-relay-bin.000003
Relay_Log_Pos: 670
Relay_Master_Log_File: binlog.000034
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 924
Relay_Log_Space: 1634
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 201
Master_UUID: 146490ea-9116-11ea-8eff-000c29939c22
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 146490ea-9116-11ea-8eff-000c29939c22:1-3
Executed_Gtid_Set: 146490ea-9116-11ea-8eff-000c29939c22:1-3
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set (0.00 sec)其中:
- Retrieved_Gtid_Set,从库IO线程已经接受到的GTID事务集合(包括可能仍在从库的relay log文件中,也包括可能已经并清除)。该值也可以从表:performance_schema.replication_connection_status获得。 在执行reset slave all 或者change master to命令时,本集合会被清空。
- Executed_Gtid_Set, 从库SQL线程已经执行的GTID事务集合,还包括本节点自身产生的事务集合(不是通过主库复制而来的)。该值等同于系统global变量:gtid_executed,也等于在从库上执行show master status。 在执行reset slave all 或者change master to命令时,本集合不会被清空(因为这个属性不仅是主从复制用,还包括自身事务,是一个全库所有操作公用的属性)
- 实际上:从库会将当前从库的Retrieved_Gtid_Set和Executed_Gtid_Set做并集后发给主库(为何是并集,因为Retrieved_Gtid_Set可能被清空),主库与自身的Executed_Gtid_Set比较,将从库缺少的GITD事务集合发给从库。
分别查看主库和从库上面的process。
# 以下为43.201的信息:
mysql> show processlist;
+----+-----------------+----------------------+------+------------------+------+---------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+----------------------+------+------------------+------+---------------------------------------------------------------+------------------+
| 4 | event_scheduler | localhost | NULL | Daemon | 1244 | Waiting on empty queue | NULL |
| 9 | root | localhost | NULL | Query | 0 | starting | show processlist |
| 27 | repl | 192.168.43.203:49894 | NULL | Binlog Dump GTID | 405 | Master has sent all binlog to slave; waiting for more updates | NULL |
+----+-----------------+----------------------+------+------------------+------+---------------------------------------------------------------+------------------+
3 rows in set (0.00 sec)
# 以下为43.203的信息:
mysql> show processlist;
+----+-----------------+-----------------+------+---------+------+--------------------------------------------------------+---------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------+---------+------+--------------------------------------------------------+---------------------------------------------------------+
| 4 | event_scheduler | localhost | NULL | Daemon | 696 | Waiting on empty queue | NULL |
| 23 | root | localhost | NULL | Query | 0 | starting | show processlist |
| 24 | system user | connecting host | NULL | Connect | 413 | Waiting for master to send event | NULL |
| 25 | system user | | NULL | Query | 218 | Slave has read all relay log; waiting for more updates | GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.43.%' |
+----+-----------------+-----------------+------+---------+------+--------------------------------------------------------+---------------------------------------------------------+
4 rows in set (0.00 sec)一主一从复制效果验证
在主库上更新一条数据后,在从库上几乎立即就能看到更新后的结果,而且从库的show slave status中,gtid_executed的值也发生了变化。 说明主从数据同步已经能正常运行。
------- 至此,一主一从GTID复制搭建完毕 --------

















 94
94

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









