







文章目录
Overcome RAW/WAR/WAW by Tomasulo Approach
1. Dlxview模拟器的使用
Execute ~\bin\f.s (f.d) or prim.s or code sequence you designed in dlxview simulator.
执行~ \ bin \ f。S (f.d)或prim.s或你在dlxview模拟器中设计的代码序列。
-
点击运行
\bin目录下的dlxwin.exe文件。
-
点击进入
configure,进行相关配置

- 选择
Tomasulo模拟算法
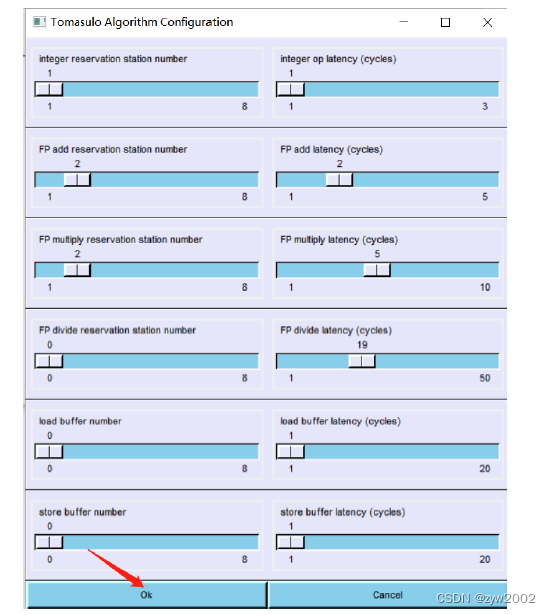
- 进入如下配置页面,选择不同指令占用的时钟周期。然后点击OK
- 点击
Load加载代码

- 选择需要加载的文件,并再次点击
Load

- 加载完成,点击
Done

- 点击
step foward
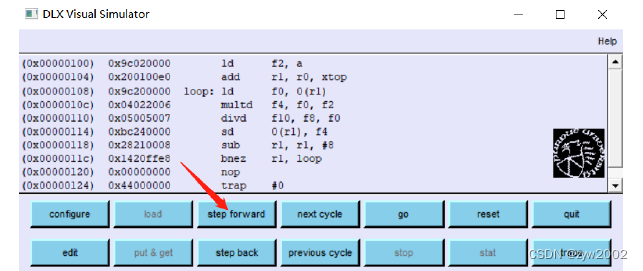
-
选择内存的起始地址 (可以自定义或者选择默认的
Default)
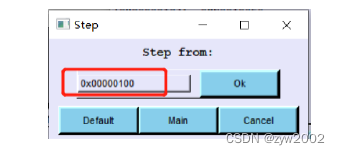
-
可以观察到如下的架构图

-
点击
Step Forword执行指令

2. f.s 代码的执行和分析
Indicate when out-of-order execution or register renaming occurs.
指示何时发生乱序执行或寄存器重命名。
2.1 逐步分析
f.d 内容如下:

f.s 代码如下
ld f2, a // f2=pi
add r1, r0, xtop // r1=28
loop: ld f0, 0(r1) // f0= 0(r1)
multd f4, f0, f2 // f4= f0*f2 = f0*pi
divd f10, f8, f0 // f10= f8/f0
sd 0(r1), f4 // f4=0(r1)
sub r1, r1, #8 // r1=r1-8
bnez r1, loop // 跳转继续执行
nop // 暂停
trap #0 // 退出
-
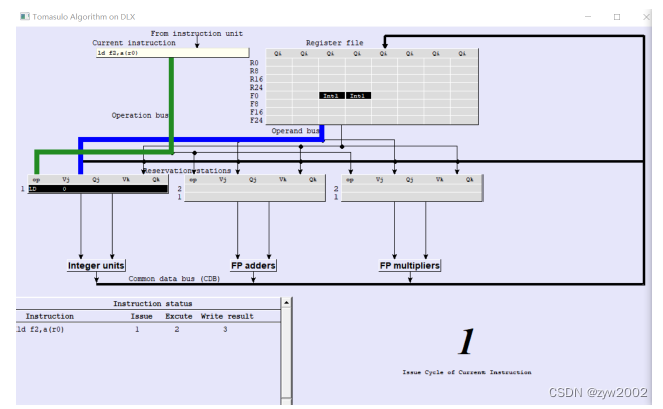
ld f2, a: 从内存中将a的值加载到寄存器f2中-
Cycle1
ld f2, a指令的发射初始时,
Integer units缓冲器中有空间,因此指令进入发射阶段。并在Integer units缓冲器中将其重命名为LD。并将F0对应的Qi域置为Int1 -
Cylce2:
ld f2, a指令的执行指令从发射阶段进入到执行阶段,计算得到待存储数a的地址。
-
Cycle3:
ld f2, a结果的写回将结果写回到f2寄存器中
-
-
add r1, r0, xtop-
Cycle 4:
add r1, r0, xtop指令的发射Integer units缓冲器中有空间,因此指令进入发射阶段。并在Integer units缓冲器中将其重命名为ADDI。并将R0对应的Qi域置为Int1 -
Cycle 5:
add r1, r0, xtop指令的执行将r0和xtop的值进行求和
-
Cycle 6:
add r1, r0, xtop指令的写回将结果写回到R1寄存器中

-
-
loop: ld f0, 0(r1)-
Cycle7:
ld f0, 0(r1)指令的发射Integer units缓冲器中有空间,因此指令进入发射阶段。并在Integer units缓冲器中将其重命名为LD。并将R0对应的Qi域置为Int1 -
Cycle8:
ld f0, 0(r1)指令的执行指令从发射阶段进入到执行阶段,计算得到对应存储器的地址为
R[R1]+0,并取出对应指令的值M[R[R1]+0] -
Cycle9:
ld f0, 0(r1)指令的写回将上一步取出的值放入f0寄存器中。
-

-
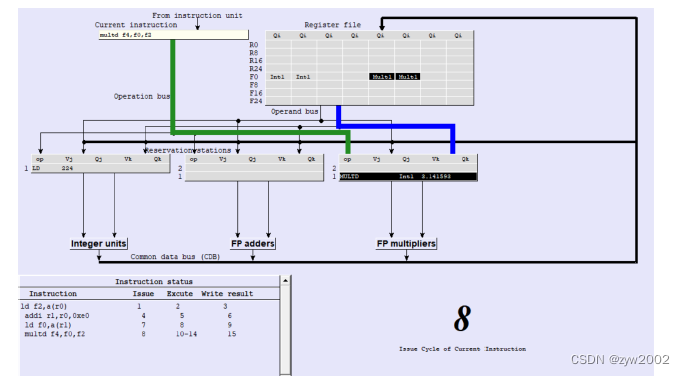
multd f4, f0, f2-
Cycle8:
multd f4, f0, f2指令的发射FP multipliers中有空闲缓冲区,因此发送该指令,并被重命令为mult1。 但是操作数f0仍未算出,因此乘法保留站中Vj 为空,Qj 为int1 (需等待int1将f0的结果算出); 此时f2处于可用状态,因此乘法保留站中Vk=0.1415…, Qk =0 。 -
Cycle10-14:
multd f4, f0, f2指令的执行由于第9周期结束时,int1指令才能把f0的结果计算出,所以只能等到第9周期时,才能执行该乘法指令。
-
Cycle15:
multd f4, f0, f2指令的写回由于一开始设定的乘法指令需要5个时钟周期才能完成。因此第15个周期时才能将计算结果写回到
f4中。
-
-
divd f10, f8, f0-
Cycle 9 :
divd f10, f8, f0指令的发射FP multipliers中有空闲缓冲区,因此发送该指令,并被重命令为mult2。 此时乘法保留站中操作数f8可用,因此Vj=0.000,Qj为空。但是操作数f0等待int1指令写回f0的值,因此Vk为空,Qk为Int1。此时由于int1指令正在写回阶段,因此通过CDB总线(红色)广播f0的值。
-
Cycle 10-28 :
divd f10, f8, f0指令的执行由
FP multipliers执行部件计算出结果除法的结果。由于一开始设定的乘法指令需要19个时钟周期才能完成。因此该过程的持续时间为cycle10-cycle28 -
Cycle 29 :
divd f10, f8, f0指令的写回第29个周期时才能将计算结果写回到
f4中。
-

-
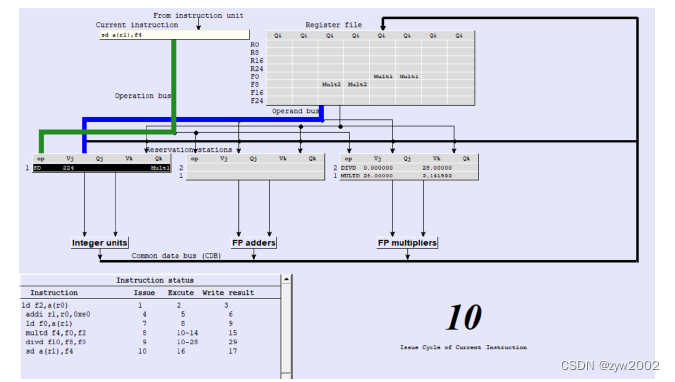
sd a(r1), f4-
Cycle10:
sd 0(r1), f4指令的发送Integer units存在空闲缓冲区,因此此时将该存储指令存入保留站中,并重命名为sd。操作数r1可用,因此Vj=224 ; 但是操作数f4需要等到乘法指令mult2写回,因此Vk为空,Qk=mult2。 -
Cycle16:
sd 0(r1), f4指令的执行由于mult2指令在cycle15时才进行写回,因此在cycle16时, f4的操作数才可用。并在该周期计算得到存储器的对应的地址和该地址存放的数值。
-
Cycle17:
sd a(r1), f4指令的写回在该周期完成指令的写回,将
a(r1)的值写入到f4中。
-
-
sub r1, r1, #8-
Cycle 18 :
sub r1, r1, #8指令发送源操作数r1需要等待sd指令在cycle17写回后才能执行,因此在cycle18时,才开始发射指令。
Integer units存在空闲缓冲区,因此此时将该存储指令存入保留站中,并重命名为int1。 此时可以得到r1的值,因此保留站中Vj=224,Qj 为空 -
Cycle 19 :
sub r1, r1, #8指令执行取操作数,并执行该减法
-
Cycle 20 :
sub r1, r1, #8指令写回将上一步的计算结果写回到r1中。
-

-
bnez r1, loop-
Cycle21:
bnez r1, loop指令发送此时
Integer units存在空闲缓冲区,因此此时将该存储指令存入保留站中,并重命名为int1。此时可以得到r1的值,因此保留站中Vj=216,Qj 为空。 -
Cycle22:
bnez r1, loop指令执行判断r1寄存器中的值是否为0, 如果不为0则发生跳转
-
Cycle23:
bnez r1, loop指令写回将新的PC值写入。

-
-
nop- Cycle24:
nop指令的发送 - Cycle25:
nop指令的执行 - Cycle26:
nop指令的写回

- Cycle24:
-
loop: ld f0, a(r1)-
Cycle27
ld f0, a(r1)指令的发射初始时,
Integer units缓冲器中有空间,因此指令进入发射阶段。并在Integer units缓冲器中将其重命名为LD。并将F0对应的Qi域置为Int1 -
Cylce28:
ld f0, a(r1)指令的执行指令从发射阶段进入到执行阶段,计算得到待存储数a的地址。
-
Cycle30:
ld f0, a(r1)结果的写回由于divd指令在cycle29时才完成指令的写回操作,同时该指令也用到的f0操作数。因此要等到Cycle30时,才能将结果写回到f0寄存器中
-

-
multd f4, f0, f2-
Cycle 28:
multd f4, f0, f2指令的发射FP multipliers中有空闲缓冲区,因此发送该指令,并被重命令为mult1。 但是操作数f0仍未算出,因此乘法保留站中Vj 为空,Qj 为int1 (需等待int1将f0的结果算出); 此时f2处于可用状态,因此乘法保留站中Vk=0.1415…, Qk =0 。 -
Cycle 31-35:
multd f4, f0, f2指令的执行由于第30周期结束时,int1指令才能把f0的结果计算出,所以只能等到第31个周期时,才能执行该乘法指令。
-
Cycle36:
multd f4, f0, f2指令的写回此第36个周期时才能将计算结果写回到
f4中。
-

2.2 整体分析
不同指令类型耗时:
- 整数运算, 加载,存储:1 cycles
- 浮点加法:2 cycles
- 浮点乘法:5 cycles
- 浮点除法:19 cycles
| 编号 | 指令 | 运算类型(执行所需时钟周期数) | 发射 | 执行 | 写回 |
|---|---|---|---|---|---|
| 1 | ld f2, a | 加载(1 c) | 1 | 2 | 3 |
| 2 | add r1, r0, xtop | 整数运算(1 c) | 4 | 5 | 6 |
| 3 | ld f0, 0(r1) | 加载(1 c) | 7 | 8 | 9 |
| 4 | multd f4, f0, f2 | 浮点乘法(5 c) | 8 | 10-14 | 15 |
| 5 | divd f10, f8, f0 | 浮点除法(19 c) | 9 | 10-28 | 29 |
| 6 | sd 0(r1), f4 | 存储(1 c) | 10 | 16 | 17 |
| 7 | sub r1, r1, #8 | 整数运算(1 c) | 18 | 19 | 20 |
| 8 | bnez r1, loop | 跳转指令(1 c) | 21 | 22 | 23 |
| 9 | nop | 空指令(1 c) | 24 | 25 | 26 |
| 10 | ld f0, 0(r1) | 加载(1 c) | 27 | 28 | 30 |
| 11 | multd f4, f0, f2 | 浮点乘法(5 c) | 28 | 31-35 | 36 |
-
执行过程分析
-
由于指令1-3都使用整数运算保留站,且该保留站只能存放一条指令记录,因此指令1-3必须等待前一个指令写回操作做完才能进行发射。
-
指令4在指令3发射完就可以立即发射,因为指令4使用的是浮点乘法保留站,此保留站存在空闲。但是指令4和指令3关于f0发生了RAW冲突,因此必须等到指令3写回完成,指令4才可以执行。因此指令4的开始执行时间为cycle10.
-
在cycle9时,浮点乘法保留站仍有空闲,因此指令5在指令4发射完就可以立即发射。在cycle10时,指令3已经写回了f0的值,因此在指令5的执行阶段不会与指令4发生RAW冲突
-
在cycle10时,整数运算保留站仍有空闲,指令6在指令4发射完即可以发射。但是指令4和指令6关于f4发生了RAR冲突,因此必须等到指令4写回完成,指令4才可以执行。因此指令6的开始执行时间为cycle16.
-
指令6,7,8,9, 10都使用整数运算保留站,且该保留站只能存放一条指令记录,因此指令6-10必须等待前一个指令写回操作做完才能进行发射。
-
指令11在指令10发射完就可以立即发射,因为指令4使用的是浮点乘法保留站,此保留站存在空闲。但是指令11和指令10关于f0发生了RAW冲突,因此必须等到指令3写回完成,指令11才可以执行。因此指令4的开始执行时间为cycle31.
-
-
乱序执行
- 比如指令6,7, 8 在指令5之后发射,但是在指令5之前完成执行。说明了指令6,7,8 提前获得了所需的操作数,则可以先执行。因此是乱序执行的。
-
寄存器重命名
- 在上述执行过程中,如指令1被重命名为int1,指令4被重命名为mult1, 指令5被重命名为mult2等。
3. 解决WAR和WAW冒险
Find WAR and WAW hazards (or design it if not existed) and focus on how to overcome them by Tomasulo approach.
找到WAR和WAW冒险(或者设计它,如果不存在的话),并专注于如何通过Tomasulo方法克服它们
由于上述的f.s指令结构和运行设置导致在运行过程中并不能观察WAR和WAW冒险,因此采用重新设计代码的方式来观察Tomasulo方法克服WAR和WAW冒险方法。
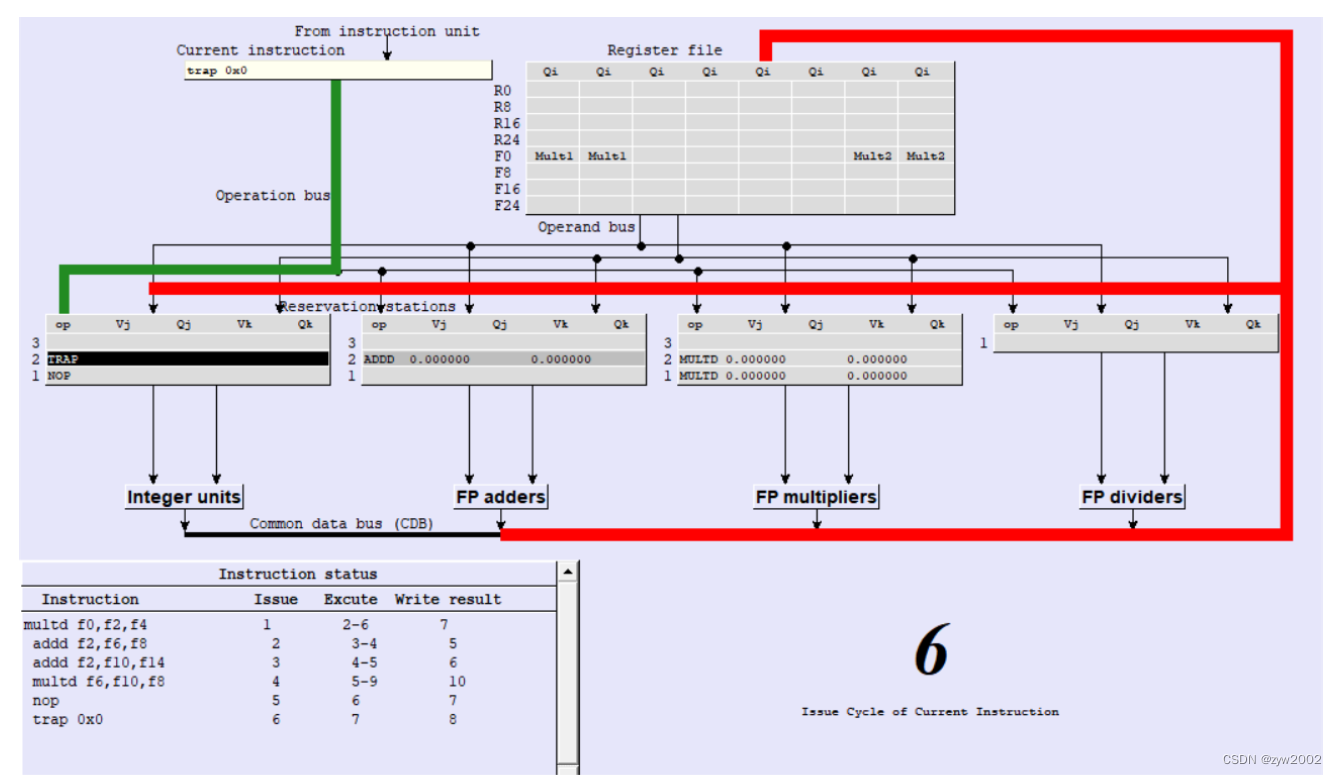
| 序号 | 指令 | 运算类型(执行所需时钟周期数) | 发射 | 执行 | 写回 |
|---|---|---|---|---|---|
| 1 | multd f0,f2,f4 | 浮点乘(5 c) | 1 | 2-6 | 7 |
| 2 | addd f2,f6,f8 | 浮点加(2 c) | 2 | 3-4 | 5 |
| 3 | addd f2,f10,f14 | 浮点加(2 c) | 3 | 4-5 | 6 |
| 4 | multd f6,f10,f8 | 浮点乘(5 c) | 4 | 5-9 | 10 |
| 5 | nop | 空指令(1 c) | 5 | 6 | 7 |
| 6 | trap #0 | 结束(1 c) | 6 | 7 | 8 |
- 流程分析
- 指令1和指令2之间关于f2存在WAR冒险,但是浮点乘法保留站将f2重命名为mul1, 并提前取出f2的值放入保留站中。因此指令2不需要任何等待,在cycle2发射指令完成后,顺次执行,且指令2的结束时间要早于指令1,即乱序执行
- 指令2和指令3之间关于f2d存在WAW冒险,但是加法保留站将f2右重命名为add1, 后一个指令的写回结果并不影响前一个指令的写回结果,因此在指令3发射完成后,顺次执行。
- 指令3和指令1之间关于f2存在WAR冒险,但是浮点乘法保留站将f2重命名为mul1, 并提前取出f2的值放入保留站中。因此指令3不需要任何额外的等待时间。
- 指令4和指令2之间关于f6存在WAR冒险,但是浮点加法保留站将f6重命名为add1, 并提前取出f6的值放入保留站中。因此指令4不需要任何额外的等待时间。
- 总结
- 冒险检测和执行控制是分布的,每个功能单元保留站中的信息决定了一条指令何时可以开始执行
- 结果直接从缓冲的保留站中通过CDB传递给功能单元,而不需要经过寄存器。
- 在指令发射并开始等待源操作数之后,将使用一个保留站的编号来引用该操作数,这个保留站保存着对寄存器进行写操作的指令。如果使用一个未用保留站编号的值来引用该操作数,则表明操作数已经在寄存器中准备就绪。由于保留站的个数多于实际寄存器的数目,因此使用保留站编号对结果进行重命名,就可以避免WAW和WAR冒险。
- 在Tomasulo算法中,采用顺序指令发射,但是只要当一条指令的操作数可用时就立即开始执行,因此会导致一些指令的发射顺序和完成顺序并不一致,即乱序完成。
















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











