







快速排序
def partition(A, p, r):
j = p - 1
for i in range(p, r + 1):
if A[i] <= A[r]:
j += 1
A[j], A[i] = A[i], A[j]
return j
def quickSort(A, p, r):
if p < r:
q = partition(A, p, r)
quickSort(A, p, q - 1)
quickSort(A, q + 1, r)7.1-2
A[p...r] 中元素都相同时,返回 q=r
def partition(A, p, r):
j = p - 1
same = True
for i in range(p, r + 1):
if A[i] != A[r]:
same = False
if A[i] <= A[r]:
j += 1
A[j], A[i] = A[i], A[j]
return (p + r) / 2 if same else j7.1-3
partition中只有一层循环,循环内部操作时间复杂度为 O(1) ,循环次数为子数组规模n,循环外操作时间复杂度为 Θ(1) ,综上partition的时间复杂度为 Θ(n)
7.1-4
def partition(A, p, r):
j = p - 1
for i in range(p, r + 1):
if A[i] >= A[r]:
j += 1
A[j], A[i] = A[i], A[j]
return j
def qsort(A, p, r):
print A, p, r
if p < r:
q = partition(A, p, r)
qsort(A, p, q - 1)
qsort(A, q + 1, r)快速排序性能分析
依赖于划分是否均衡,均衡—>归并排序,不均衡—>插入排序
最坏情况: T(n)=T(n−1)+Θ(n) ,时间复杂度 Θ(n2)
与插入排序不同,当输入有序时,插入排序的时间复杂度为 Θ(n) ,而快速排序的时间复杂度为 Θ(n2)
最好情况:均衡划分,
7.2-1
7.2-2
当所有的元素都相等时,即最坏情况,时间复杂度为 Θ(n2)
7.2-3
对规模为
n
的输入,partition的时间复杂度为固定的
7.2-5
以
nk
记第
k
层占比
最后一层的问题规模 nk=1
同理可求最大深度约为
7.2-6
∵ 输入数组是完全随机
∴ 可以认为partition给出的划分结果q的在 1...n 上分布是等可能的,即
∴ 原问题就变成了一个古典概型问题
P( 产生比 1−α:α 更平衡的划分) =
快速排序的随机化版本
import random
def randomPartition(A, p, r):
i = random.randint(p, r)
A[i], A[r] = A[r], A[i]
partition(A, p, r)
def qsort(A, p, r):
if p < r:
q = randomPartition(A, p, r)
qsort(A, p, q - 1)
qsort(A, q + 1, r)7.3-1
如果输入是完全随机的,那么最坏情况出现的概率应该是很小的,对算法整体效率的参考价值不大,我们更加关注综合考虑的各种输入情况下,算法的平均效率,也就是期望运行时间。
7.3-2
不论好坏,总要调用 Θ(n) 次
递归树中在每个非叶节点处调用一次随机数生成器,叶节点一共n个
非叶子节点数目为
当输入数据已经基本有序时,插入排序的速度很快,接近线性时间复杂度
7.4-5
因为当子数组的长度小于k时结束递归,那么递归树的深度为
所以快排阶段时间复杂度为
插入排序阶段,每个元素比较的次数为
综上,整体的时间复杂度为
如何选择合适的k,以优化时间复杂度???
7.4-6
在题意表述的情况下,最坏划分是生成大小为1和n-2的子问题
以 z1, z2, … zn 记数组的顺序排序结果
思考题
7-1
def hoarePartition(A, p, r):
x = A[p]
i = p - 1
j = r + 1
while True:
j -= 1
while A[j] > x:
j -= 1
i += 1
while A[i] < x:
i += 1
if i < j:
A[i], A[j] = A[j], A[i]
else:
return j7-1.b
循环不变量:
每次迭代前一定存在 k∈[p,j−1], A[k]≤x ,一定存在 l∈[i+1,r], A[l]≥x
初始化:
第一次迭代前, k=p, l=p ,满足循环不变量
保持:
因为第i次迭代前,一定存在 k∈[p,j−1], A[k]≤x, 一定存在 l∈[i+1,r], A[l]≥x
所以第i次迭代时,7、8行循环和10、11行循环一定能在合法的索引值处结束循环,合法索引值即为 j=k, i=l
如果 i<j ,交换 A[i],A[j] 后,存在 k=i∈[p,j−1], A[k]≤x, 存在 l=j∈[i+1,r], A[l]≥x ,循环不变量得以保持
结束:
i≥j ,结束循环,至此为止从未发生越界访问,所以算法不会访问 A[p...r] 以外的数据
7-1.c
只要证 j≠r ,再结合7-1.b,即证得 p≤j<r
反证,如果返回值 j=r ,则 i≥j=r
又由7-1.b知 p≤i≤r
所以只能有 i=r
因为 j=r 意味着外层循环只执行了一次就返回结果
又已知在外层循环第一次执行时,第11行循环根本不会执行,所以 i=p
i=p=r ,意味着输入数组规模为1,与大前提数组至少包含两个元素相矛盾
所以 j≠r
7-1.d
循环不变量:
每次迭代后 A[p...i] 中的每一个元素都小于等于 A[j...r] 中的元素
保持:
6、7、8行结束后,确保 A[j]≤x , A[j+1…r] 中的元素都大于 x
9、10、11行结束后,确保
结束:
6、7、8行结束后,确保 A[j]≤x , A[j+1…r] 中的元素都大于 x
9、10、11行结束后,确保
7-1.e
def qsort(A, p, r):
if p < r:
q = hoarePartiton(A, p, r)
qsort(A, p, q)
qsort(A, q + 1, r)7-2
7-2.a
当所有元素都相同,每次分割时间为 Θ(n)
分割后生成大小为0和n-1的子问题,所以时间复杂度 T(n)=T(n−1)+Θ(n)
解得 T(n)=Θ(n2)
7-2.b
import random
def modifiedPartition(A, p, r):
x = A[r]
q = p - 1
for i in range(p, r + 1):
if A[i] < x:
q += 1
A[i], A[q] = A[q], A[i]
t = r + 1
for i in reversed(range(p, r + 1)):
if A[i] > x:
t -= 1
A[i], A[t] = A[t], A[i]
return q, t
def randomPartition(A, p, r):
x = random.randint(p,r)
A[x], A[r] = A[r], A[x]
modifiedPartition(A, p, r)
def qsort(A, p, r):
if p < r:
q, t = modifiedPartition(A, p, r)
qsort(A, p, q)
qsort(A, t, r)7-3
7-3.a
古典概型,
7-3.b&c
Xq 与 T 独立
7-4
7-4.a
循环不变量:
每次迭代前 A[1,p−1] 中的元素有序排列,且都小于等于 A[p,A.length] 中的元素
初始化:
第一次迭代前,A[1,0]是空的子数组,满足循环不变量
保持:
第i次迭代前 A[1,p−1] 中的元素有序排列,且都小于等于 A[p,A.length] 中的元素
对 A[p,r] 进行分割后, A[p,q−1] 中的元素都小于等于 A[q+1,r] ,对 A[p,q−1] 排序后,其内元素有序
此时 A[1,q−1] 中的元素有序排列,且都小于等于 A[q+1,A.length]
令 p=q ,循环不变量保持
结束:
p>=A.length
A[p,A.length]
或为空的子数组或者只有一个元素,
A[1,p−1]
中的元素有序排列,且都小于等于
A[p,A.length]
中的元素,所以
A
被正确排列
7-4.b
每次递归调用的规模比当前规模小1
7-4.c
每次迭代挑选规模较小的子问题来递归处理,而规模较大的子问题使用迭代处理
def tailRecursiveQuickSort(A, p, r):
while p < r:
q = randomPartition(A, p, r):
if (q - p) < (r - q):
tailRecursiveQuickSort(A, p, q - 1)
p = q + 1
else:
tailRecursiveQuickSort(A, q + 1, r)
r = q - 1栈深度
最坏栈深度,每次都对半分, d=Θ(lgn)
7-5
7-5.a
7-5.b
平凡实现
7-5.c
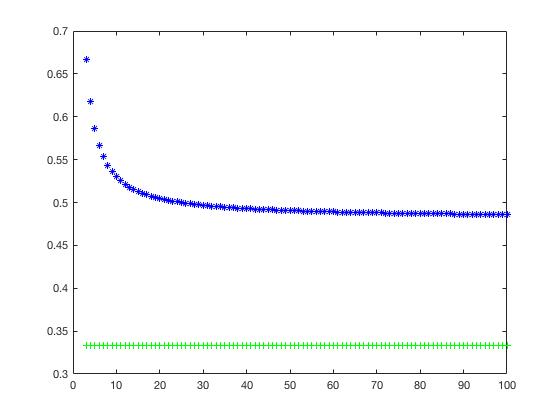
clear All;
x = 3:1:100;
y = zeros(1,98);
z = ones(1,98) ./ 3;
syms t
for i = 1:1:98
y(i) = int(6*(t-1)*(x(i)-t)/(x(i)*(x(i)-1)*(x(i)-2)), x(i)/3, 2*x(i)/3);
end
plot(x,y,'b*',x,z,'g+');两种实现的差距
7-6
思路:
参考7-2的思想
选定主元,根据是否与主元的位置关系进行分割
与主元不重叠,位于主元左侧则向左集中,与主元不重叠,位于主元右侧则向右集中
如果与主元重叠,则更新主元范围为重叠部分,重叠部分不需要排序
def intersect(x, y):
if y[0] <= x[0] and y[1] < x[1]:
return [x[0], y[1]]
elif y[0] > x[0] and y[1] < x[1]:
return list(y)
elif y[0] < x[0] and y[1] >= x[1]:
return [y[0],x[1]]
else:
return x
def partition(A, p, r):
x = list(A[r])
q = p - 1
t = r + 1
i = p
for n in range(p, r + 1):
if A[i][1] <= x[0]:
q += 1
A[i], A[q] = A[q], A[i]
i += 1
elif A[i][0] >= x[1]:
t -= 1
A[i], A[t] = A[t],A[i]
else:
x = intersect(x, A[i])
i += 1
def fuzzySort(A, p, r):
if p < r:
q, t = partition(A, p, r)
fuzzySort(A, p, q)
fuzzySort(A, t, r)bug:分割后问题规模可能不会减小
import random
def intersect(x, y):
if y[0] <= x[0] and y[1] < x[1]:
return [x[0], y[1]]
elif y[0] > x[0] and y[1] < x[1]:
return list(y)
elif y[0] < x[0] and y[1] >= x[1]:
return [y[0],x[1]]
else:
return x
def partition(A, p, r):
x = list(A[r])
q = p - 1
t = r
i = p
for n in range(p, r):
if A[i][1] <= x[0]:
q += 1
A[i], A[q] = A[q], A[i]
i += 1
elif A[i][0] >= x[1]:
t -= 1
A[i], A[t] = A[t],A[i]
else:
x = intersect(x, A[i])
i += 1
A[r], A[t] = A[t], A[r]
return q, t + 1
def randomPartition(A, p, r):
i = random.randint(p,r)
A[r], A[i] = A[i], A[r]
return partition(A, p, r)
def fuzzySort(A, p, r):
if p < r:
q, t = randomPartition(A, p, r)
fuzzySort(A, p, q)
fuzzySort(A, t, r)当所有元素都重叠时,调用randomPartition后生成的两个子问题的规模都是0
randomPartition的时间复杂度为 Θ(n) ,所以这个时候算法的时间复杂度为 Θ(n)















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









