







目录
一、字符串操作前面的u,r,b,f的作用
1、字符串前边加u:
例如: u"我含有中文字符123"
作用: 后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
2、字符串前边加r:
应用:我们常能在正则表达式中看到,pattern = re.compile(r"吗\n|\?|?|多|哪|怎|什么|啥|么"),这样是指将该字符串表示成一个普通的字符串,没有特殊字符在原先字符串中的含义,比如\n在普通字符串中是换行的含义,而此处将其打印出来依旧是"\n"字符。
3、字符串前边加b:
例如: response = b'<h1>Hello World!</h1>'
‘b’ 表示这是一个 bytes 对象 作用:" b"前缀表示:后面字符串是bytes 类型。
用处: 网络编程中,服务器和浏览器只认bytes 类型数据。 如:send 函数的参数和 recv 函数的返回值都是 bytes 类型。
在 Python3 中,bytes 和 str 的互相转换方式如下:
str1 = b"<div>hahah!</div>"
str2 = "hahah"
print(type(str1))
print(type(str1.decode('utf-8')))
print(type(str2.encode('utf-8')))
'''
输出:
<class 'bytes'>
<class 'str'>
<class 'bytes'>4、字符串前边加f:
以f开头的字符串表示字符串内支持大括号内的表达式,例如:
import time
t = time.time()
time.sleep(1)
print(f"Now time is {time.time()-t:.2f} s")
'''
result:
Now time is 1.01 s
'''二、正则re.S
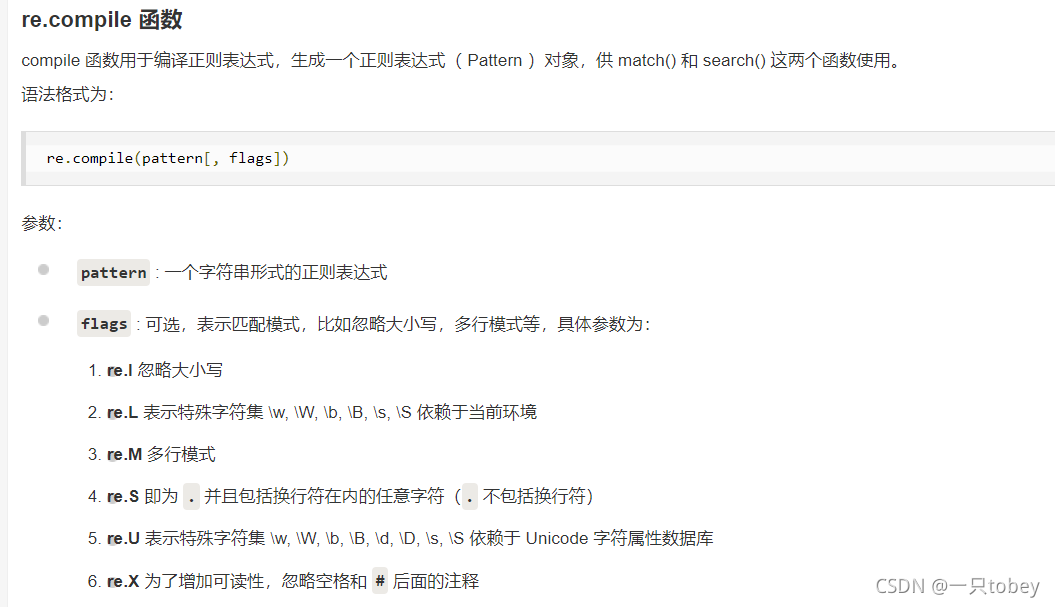
 https://blog.csdn.net/weixin_42781180/article/details/81302806
https://blog.csdn.net/weixin_42781180/article/details/81302806# 获取stream和endstream之间的部分
stream=re.compile(b'.*?FlateDecode.*?stream(.*?)endstream',re.S)
# 作用说明
import re
a = """sdfkhellolsdlfsdfiooefo:
877898989worldafdsf"""
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print ('b is ' , b)
print ('c is ' , c)
"""输出如下
b is []
c is ['lsdlfsdfiooefo:\n877898989']
"""在字符串a中,包含换行符\n,在这种情况下:
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









