







一、感知器原理
感知器的原型是神经元模型。是在1943年,由McCulloch 和 Pitts提出,所以也被叫做“M-P神经元模型”。
这个模型的工作原理可由下图展示:
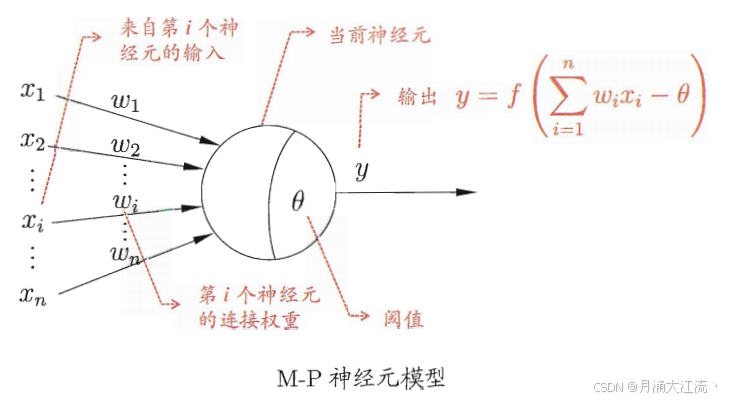
- 本神经元接收N个来自外界(或其他神经元)的输入信号,分别是 x 1 x_1 x1, x 2 x_2 x2, …, x n x_n xn;
- 输入信号 x 1 x_1 x1, x 2 x_2 x2, …, x n x_n xn与各自对应的权重 w 1 w_1 w1, w 2 w_2 w2, …, w n w_n wn作用,得到该神经元的总输入a = x 1 ⋅ w 1 x_1·w_1 x1⋅w1+ x 2 ⋅ w 2 x_2·w_2 x2⋅w2+ …+ x n ⋅ w n x_n·w_n xn⋅wn;
- 该神经元接收到的总输入a将与本神经元的阈值θ进行比较;
- 比较后,通过“激活函数”处理,产生最后输出;
二、单层感知器
单层感知器是可以解决二分类问题的。
2.1、数据集与对应标签
# 输入数据
X = np.array([[1,2,3],
[1,4,5],
[1,1,1],
[1,5,3],
[1,0,1]])
# 标签
Y = np.array([1,1,-1,1,-1])
这里 X X X的输入维度是3, X i = [ 1 , x i , y i ] X_i=[1,x_i,y_i] Xi=[1,xi,yi]相当于上图中有3个输入支,在这3个输入支中,第一个值"1"相当于偏置值(也可以说与阈值的意义相同),后两个值 [ x i , y i ] [x_i,y_i] [xi,yi]组成平面的一个点。实验中一共输入了5组值,每组值对应的正负标签由 Y Y Y存储,我们需要做的就是找到一条直线,将正负值区域划分开。
2.2、初始化权重
# 权重初始化,取值范围-1到1
W = (np.random.random(X.shape[1])-0.5)*2
print('初始化权值:',W)
随机生成权重,且要求权重范围落在(-1,1),权重的个数与输入支个数相同
2.3、如何更新权重函数
实现思路:当随机生成的权重 W W W不能将正负值区域划分开来,就要根据当前输出集和原有标签集差值的大小,乘以输入集 X i X_i Xi,再乘以学习率 l r lr lr得到改变权重,改变权重加上旧权重,就得到新权重;
#更新权值函数
def get_update():
global X,Y,W,lr,n
n += 1
#新输出:X与W的转置相乘,得到的结果再由阶跃函数处理,得到新输出
new_output = np.sign(np.dot(X,W.T))
#调整权重: 新权重 = 旧权重 + 改变权重
new_W = W + lr*((Y-new_output.T).dot(X))/int(X.shape[0])
W = new_W
说明:这里将改变权重除以 i n t ( X . s h a p e [ 0 ] ) int(X.shape[0]) int(X.shape[0])是归一化操作,防止乘积的数值过大;
2.4、求分割线,并画图展示
def get_show():
# 所有样本的坐标
all_x = X[:, 1]
all_y = X[:, 2]
# 额外注释标签为-1的负样本的坐标
all_negative_x = [1, 0]
all_negative_y = [1, 1]
# 计算分界线斜率与截距
k = -W[1] / W[2]
b = -W[0]/ W[2]
print('斜率 k=', k)
print('截距 b=', b)
print('分割线函数:y = ', k,'x +(', b, ')')
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.plot(all_x, all_y,'bo')
plt.plot(all_negative_x, all_negative_y, 'yo')
plt.show()
下图解释说明斜率与截距怎么求得

2.5、单层感知器实现二分类
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2018/01/11;10:05
# -*- python3.5
import numpy as np
import matplotlib.pyplot as plt
n = 0 #迭代次数
lr = 0.11 #学习速率
# 输入数据
X = np.array([[1,2,3],
[1,4,5],
[1,1,1],
[1,5,3],
[1,0,1]])
# 标签
Y = np.array([1,1,-1,1,-1])
# 权重初始化,取值范围-1到1
W = (np.random.random(X.shape[1])-0.5)*2
print('初始化权值:',W)
def get_show():
# 所有样本的坐标
all_x = X[:, 1]
all_y = X[:, 2]
# 额外注释标签为-1的负样本的坐标
all_negative_x = [1, 0]
all_negative_y = [1, 1]
# 计算分界线斜率与截距
k = -W[1] / W[2]
b = -W[0]/ W[2]
print('斜率 k=', k)
print('截距 b=', b)
print('分割线函数:y = ', k,'x +(', b, ')')
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.plot(all_x, all_y,'bo')
plt.plot(all_negative_x, all_negative_y, 'yo')
plt.show()
#更新权值函数
def get_update():
global X,Y,W,lr,n
n += 1
#新输出:X与W的转置相乘,得到的结果再由阶跃函数处理,得到新输出
new_output = np.sign(np.dot(X,W.T))
#调整权重: 新权重 = 旧权重 + 改变权重
new_W = W + lr*((Y-new_output.T).dot(X))/int(X.shape[0])
W = new_W
def main():
for _ in range(100):
get_update()
print('第',n,'次改变后的权重:',W)
new_output = np.sign(np.dot(X, W.T))
if (new_output == Y.T).all():
print("迭代次数:", n)
break
get_show()
if __name__ == "__main__":
main()
效果展示:


三、感知器解决异或问题
感知器解决异或问题有两种方式:
- 用多个线性函数对区域进行划分,然后再对每个神经元的输出做出逻辑运算。
- 对神经元添加非线性项输入,使等效的输入维度变大:之前的输入只有 x 1 , x 2 x_1,x_2 x1,x2,但如果添加 x 1 2 , x 1 ⋅ x 2 , x 2 2 x_1^2, x1·x2, x_2^2 x12,x1⋅x2,x22项后,就由以前的两项可以生成后三项,而且这五项不再是线性的了。
方法2的实现如下:
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2018/01/11;16:30
# -*- python3.5
'''
异或问题的解决方式有:增加非线性项:
输入x1,x2;
增加x1^2,x1*x2,x2^2
'''
import numpy as np
import matplotlib.pyplot as plt
n = 0 #迭代次数
lr = 0.11 #学习速率
#输入数据分别:偏置值,x1,x2,x1^2,x1*x2,x2^2
X = np.array([[1,0,0,0,0,0],
[1,0,1,0,0,1],
[1,1,0,1,0,0],
[1,1,1,1,1,1]])
#标签
Y = np.array([-1,1,1,-1])
# 权重初始化,取值范围-1到1
W = (np.random.random(X.shape[1])-0.5)*2
print('初始化权值:',W)
def get_show():
# 正样本
x1 = [0, 1]
y1 = [1, 0]
# 负样本
x2 = [0,1]
y2 = [0,1]
xdata = np.linspace(-1, 2)
plt.figure()
plt.plot(xdata, get_line(xdata,1), 'r')
plt.plot(xdata, get_line(xdata,2), 'r')
plt.plot(x1, y1, 'bo')
plt.plot(x2, y2, 'yo')
plt.show()
def get_line(x,root):
a = W[5]
b = W[2] + x*W[4]
c = W[0] + x*W[1] + x*x*W[3]
if root == 1:
return (-b+np.sqrt(b*b-4*a*c))/(2*a)
if root == 2:
return (-b-np.sqrt(b*b-4*a*c))/(2*a)
#更新权值函数
def get_update():
global X,Y,W,lr,n
n += 1
#新输出:X与W的转置相乘,得到的结果再由阶跃函数处理,得到新输出
new_output = np.dot(X,W.T)
#调整权重: 新权重 = 旧权重 + 改变权重
new_W = W + lr*((Y-new_output.T).dot(X))/int(X.shape[0])
W = new_W
def main():
for _ in range(10000):
get_update()
get_show()
last_output = np.dot(X,W.T)
print('最后逼近值:',last_output)
if __name__ == "__main__":
main()
效果展示:




















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











