







5.trie树(字典树)
文章目录
参考自leedcode宫水三叶姐姐和bilibili极客学院老师的思想
(1) 字典树的数据结构
字典树,即tire树,又称单词树或键树,是一种树形结构。
典型应用是用于统计和排序大量的字符串,所以常被应用来作为搜索引擎系统的文本词频统计。
优点:最大限度地减少无谓的字符串比较,查询效率比哈希表高
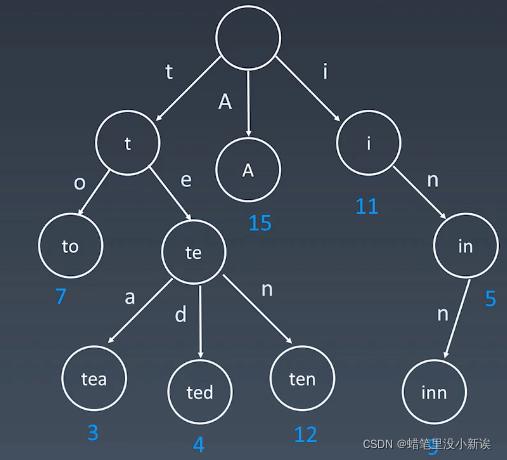
(2) 字典树的核心思想
利用了字母的公共前缀,进行查找操作的时候,每次只需找到下一个字母的存储地址即可。
(3)字典树的基本性质
(1)结点本身不存完整单词
(2)从根结点到某一结点,路径上经过的字符连接起来,为该结点对应的字符串。
(3)每个结点的所有自己诶单路径代表的字符都不相同
1) 通过二维数组来构建trie树
public class Trie {
int N = (int)1e5+9;
int[][] trie;
int[] count;
int index;
public Trie() {
trie = new int[N][26];
count = new int[N];
index = 0;
}
public void insert(String s) {
int p = 0;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(trie[p][u] == 0) trie[p][u] = ++index;
p = trie[p][u];
}
count[p] ++;
}
public boolean search(String s) {
int p = 0;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(trie[p][u] == 0) return false;
p = trie[p][u];
}
return count[p] != 0;
}
public boolean startsWith(String s) {
int p = 0;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(trie[p][u] == 0) return false;
p = trie[p][u];
}
return true;
}
}
这是其中一种写法,以二维数组来巧妙的代替了链表。根据公共前缀来判断是否需要将index++来使用新的一行数组空间。
构建过程:构造函数将数组进行初始化,将index置为0,0行数组即为跟
insert函数:若插入一个单词,如‘hi’,找第0行中 h-‘a’的存储空间,看看是否已经有了c这个公共前缀,若没有,链接新的一行数组,让第0行中的[h - ‘a’]指向新一行数组的下标,此时index是1,我们要继续插入‘i’找1行中的[i - ‘a’]是否为0,若为0,则表示无此公共前缀,链接新的一行数组,让第1行的[i - ‘a’]指向新的一行数组下标,此时为2,已经将hi单词插入完毕,但是此时2行数组的所有空间全为0,即是说,叶子结点是没有存任何数据的,此时我们同时对第2行的count[2]数组进行 ++,表示此处有该单词,而不只是公共前缀。
search函数:同insert函数过程,如果可以遍历完单词的每个字母,且判断count[p]不为0,即存在该单词。
searchWith函数:和search函数唯一不同点在于,最后不用判断count[p]是不是为0,如果前面过程理解了,这一步也就好理解了,因为如果只是公共前缀的话,count[p] 是不是0不影响返回true or false,只要能保证不在遍历每个字母过程中遇到0返回false就行。
时间复杂度:Trie数的每次调用时间复杂度取决于入参字符串的长度,复杂度为O(len)
空间复杂度:二维数组的高度为n,字符集大小为k,复杂度为O(nk)
2)trie树的常规构造过程
随着数据的不断插入,根据需要不断创建TrieNode结点
package dataStructure_Tree;
public class Trie {
class TrieNode {
boolean end;
TrieNode[] tns = new TrieNode[26];
}
TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(p.tns[u] == null) p.tns[u] = new TrieNode();
p = p.tns[u];
}
p.end = true;
}
public boolean search(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(p.tns[u] == null) return false;
p = p.tns[u];
}
return p.end;
}
public boolean startsWith(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); ++i) {
int u = s.charAt(i) - 'a';
if(p.tns[u] == null) return false;
p = p.tns[u];
}
return true;
}
}
后面总结引用leedcode宫水姐姐的总结。
3)两种方式的对比
常用的方法更方便我们去理解,但二维数组巧用不用每次都去new一个对象,只需要在一开始预估好数组要开多大的空间便可,但是我们需要去估算一个行数,即二维数组开多少行,估多会导致内存开销过大,估小会导致数组越界。
同时还有另一个问题,OJ每测试一个样例会创建一个Trie对象,那这么说的话,内存就会大量浪费,此时我们可以将Trie里的数组设置为静态(static)即可,通过构造函数每次将数组中的数据进行重置。
有coding:
class Trie { // 以下 static 成员独一份,被创建的多个 Trie 共用 static int N = 100009; // 直接设置为十万级 static int[][] trie = new int[N][26]; static int[] count = new int[N]; static int index = 0; // 在构造方法中完成重置 static 成员数组的操作 // 这样做的目的是为减少 new 操作(无论有多少测试数据,上述 static 成员只会被 new 一次) public Trie() { for (int row = index; row >= 0; row--) { Arrays.fill(trie[row], 0); } Arrays.fill(count, 0); index = 0; } public void insert(String s) { int p = 0; for (int i = 0; i < s.length(); i++) { int u = s.charAt(i) - 'a'; if (trie[p][u] == 0) trie[p][u] = ++index; p = trie[p][u]; } count[p]++; } public boolean search(String s) { int p = 0; for (int i = 0; i < s.length(); i++) { int u = s.charAt(i) - 'a'; if (trie[p][u] == 0) return false; p = trie[p][u]; } return count[p] != 0; } public boolean startsWith(String s) { int p = 0; for (int i = 0; i < s.length(); i++) { int u = s.charAt(i) - 'a'; if (trie[p][u] == 0) return false; p = trie[p][u]; } return true; } }
关于「二维数组」是如何工作 & 1e5 大小的估算
要搞懂为什么行数估算是 1e5,首先要搞清楚「二维数组」是如何工作的。在「二维数组」中,我们是通过 indexindex 自增来控制使用了多少行的。
当我们有一个新的字符需要记录,我们会将 indexindex 自增(代表用到了新的一行),然后将这新行的下标记录到当前某个前缀的格子中。
举个🌰,假设我们先插入字符串 abc 这时候,前面三行会被占掉。
第 0 行 a 所对应的下标有值,值为 1,代表前缀 a 后面接的字符串会被记录在下标为 1 的行内
第 1 行 b 所对应的下标有值,值为 2,代表前缀 ab 后面接的字符串会被记录在下标为 2 的行内
第 2 行 c 所对应的下标有值,值为 3,代表前缀 abc 后面接的字符串会被记录在下标为 3 的行内
当再插入 abcl 的时候,这时候会先定位到 abl 的前缀行(第 3 行),将 l 的下标更新为 4,代表 abcl 被加入前缀树,并且前缀 abcl 接下来会用到第 4 行进行记录。
但当插入 abl 的时候,则会定位到 ab 的前缀行(第 2 行),然后将 l 的下标更新为 5,代表 abl 被加入前缀树,并且前缀 abl 接下来会使用第 5 行进行记录。
当搞清楚了「二维数组」是如何工作之后,我们就能开始估算会用到多少行了,调用次数为 104,传入的字符串长度为 103
,假设每一次的调用都是 insertinsert,并且每一次调用都会使用到新的 103行。那么我们的行数需要开到 107 。但由于我们的字符集大小只有 26,因此不太可能在 104
次调用中都用到新的 103行。而且正常的测试数据应该是 searchsearch 和 startsWithstartsWith 调用次数大于 insertinsert 才有意义的,一个只有 insertinsert 调用的测试数据,任何实现方案都能 AC。
因此我设定了 105为行数估算,当然直接开到 106也没有问题。
作者:AC_OIer
链接:https://leetcode-cn.com/problems/implement-trie-prefix-tree/solution/gong-shui-san-xie-yi-ti-shuang-jie-er-we-esm9/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先,在纯算法领域,前缀树算是一种较为常用的数据结构。不过如果在工程中,不考虑前缀匹配的话,基本上使用 hash 就能满足。
如果考虑前缀匹配的话,工程也不会使用 Trie 。
一方面是字符集大小不好确定(题目只考虑 26 个字母,字符集大小限制在较小的 26 内)因此可以使用 Trie,但是工程一般兼容各种字符集,一旦字符集大小很大的话,Trie 将会带来很大的空间浪费。
另外,对于个别的超长字符 Trie 会进一步变深。
这时候如果 Trie 是存储在硬盘中,Trie 结构过深带来的影响是多次随机 IO,随机 IO 是成本很高的操作。
同时 Trie 的特殊结构,也会为分布式存储将会带来困难。
因此在工程领域中 Trie 的应用面不广。
至于一些诸如「联想输入」、「模糊匹配」、「全文检索」的典型场景在工程主要是通过 ES (ElasticSearch) 解决的。
而 ES 的实现则主要是依靠「倒排索引」。
作者:AC_OIer
链接:https://leetcode-cn.com/problems/implement-trie-prefix-tree/solution/gong-shui-san-xie-yi-ti-shuang-jie-er-we-esm9/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











