







本人重点做的是多任务学习,但是这方面资料有限,进展缓慢,平时做的是人脸属性分析,在查找文献时,偶然看到这篇论文,感觉看起来思想还可以~因为对行人重识别领域没什么了解,所以只从多任务角度来重点记录下这篇论文。
首先提下这篇文章作者,是一位在UTS在读的博三学生,发过好几篇顶会文章,羡煞我也,主页在此,有很多行人重识别方向的研究,基本都有代码,唯独这篇没有,有点难过!
下面进入正文,相比之前工作,本篇文章有两方面不同:
- 文章系统地研究了通过一个联合学习网络,行人重识别任务和属性识别任务怎么互相受益
- 在先前工作中,属性间的联系很少被考虑,但现实中,对同一个人来说,很多属性经常同时发生
1.本篇文章的贡献:
- 人工标记了两个数据库的行人属性(在做多任务时候,很多数据库标签有限真的是很苦恼啊,不得不自己想办法打一些标签)
- 提出了APR框架,做行人识别和属性识别
- 介绍了属性重权重模块(ARM),根据学到的属性间的依赖和联系来更正属性的预测
- 提出了属性加速过程,通过用不同属性从搜索的照片中过滤来加速检索过程
- 在属性识别和行人重识别任务上准确率都得到了提升
2.属性标记
人为标记了Market-1501和DukeMTMC-reID数据库的属性标签,这两个数据库都是在大学采集的,处于不同季节,Market-1501中很多人穿裙子或短袖,但在DukeMTMC-reID穿长裤。因此,对于两个数据库,采用了不同的属性集。
属性是根据数据库的特点选择的,所以一个属性的类别标记,比如是否戴帽子,是严重不均衡的。(文中好像也没提怎么缓解这个严重不均衡问题,所以后面将是否戴帽子这个属性去掉后,行人重识别的结果还有上升,是不是和这里的数据严重失衡有关,如何解决?)
以其中一个为例,Market-1501,标记了27个属性,从性别、头发长度、袖子长度等标记,可以通过文中给出的表看出袖长、年龄、帽子等属性严重比例失衡。
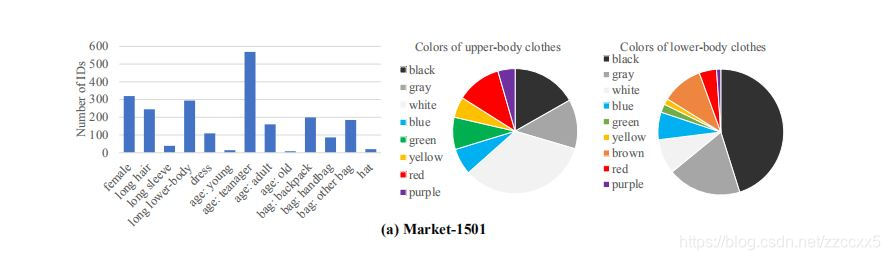
所有属性是在身份层面标注的。比如说在下面图中,虽然第二张图看不见背包,但第一二张图是同一身份的人(可能说的有点问题,不知道咋表达),所以依旧给第二张照片打上有背包的标签。

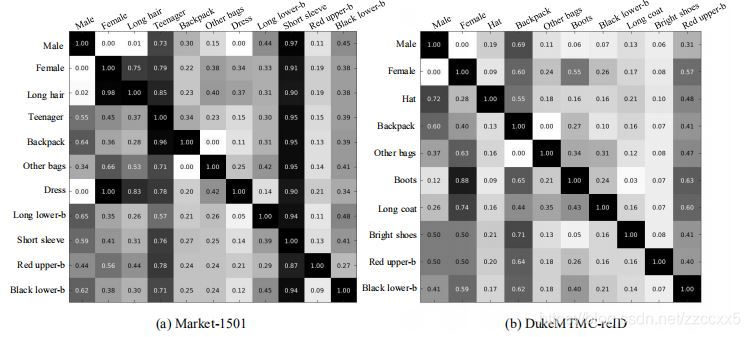
我们将在同一张图片中两个属性同时发生的可能性定义为两个属性间的联系,下图是一些代表性属性间的联系。
3.提出的方法
3.1 两个baseline
- IDE:训练行人重识别模型,将行人重识别任务视为图像识别分类任务(多分类任务,可用softmax函数,最终将置信度最大的那类作为预测标签)
- ARN:属性识别网络,多个输出的多分类(二分类也可视为多分类)
3.2 联合属性的行人重识别网络(APR)
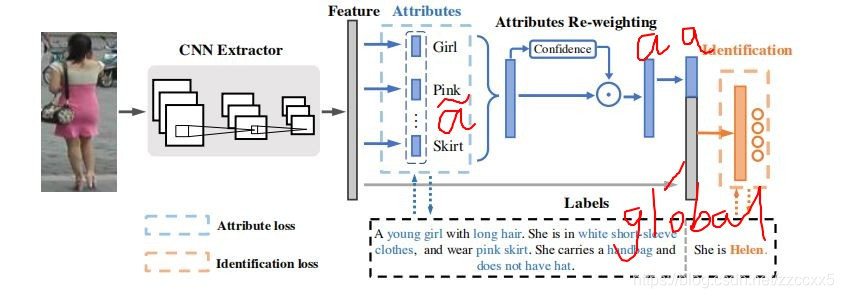
APR网络包含两个预测部分,一个是属性分类任务,另一个是身份分类任务。输入一张行人图片,APR网络首先通过CNN提取器提取人的特征。接下来APR网络基于图片特征预测属性。通过属性预测的标签和真实标签算出属性的loss。对于身份分类部分,由于局部的描述符(属性)辅助全局的身份,我们将属性预测作为身份分类的额外线索。
为了更好利用属性,给定一张图片,ARP网络首先计算M个属性的loss,然后M个属性预测的分数被整合,喂入ARM模块。ARM的输出被整合到全局图片特征来计算身份分类的loss。
对于ARM模块来说,具体的实现流程为:集合a为输入的属性预测结果,其中每个属性的预测值在[0,1]之间,共m个值,置信度得分,其中v和b是需要训练的参数,随后ARM模块将原始的预测转为
(对应点相乘)。ARM的输出a被整合到全局图片特这个中来进行身份预测,具体可见图中标识。
在优化过程中,分为属性识别和身份识别两个大类的loss,用进行衡量权重,最终loss为
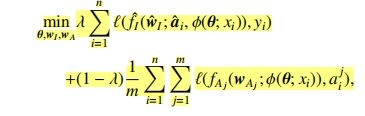
3.3属性任务加速身份识别过程
在现实应用中,计算检索间的距离成为重识别系统主要消耗时间步骤。属性任务可以加速评估过程。主要思想是过滤掉和要查找图片没有相同属性的图片。
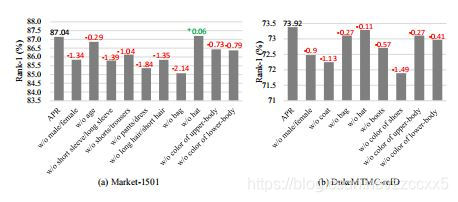
4.消融实验
通过将属性集中的属性依次去掉,来证明该属性的有效性。
5.一点或许并不怎么对的想法
在看这篇文章的Introduction时候是很激动的,因为提到探究了为啥属性会对重识别任务有益。通篇读下来过后,发现应该就是通过这个消融实验来证明了有效性,没有我想象的理论上的计算的支撑。
因为我现在做的实验遇到的一个问题是,实验并不能朝着我想象的方向发展。我的网络性能有一定提升,我的预期是以为多任务之间的相互作用,通过消融实验排除发现并不是这样,这篇论文也没能帮我有这方面原因查找的启发。
另外一方面,这个多任务的多个损失函数的权重之间也是使用的手动调参方式,想要找到更多自学习调差文献啊!
总之实验遇到很大瓶颈,以上很多想法可能并不正确,只是作为自己学习的一个记录,如有错误指出,立即订正!
如果有研究多任务方面的大佬,麻烦给我多安利一点学习资料啊!有点迷茫不知道该怎么做!多谢!














 1552
1552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









