






在《【Python】线程的创建、执行、互斥、同步、销毁》(点击打开链接)中介绍了Python中线程的使用,但是里面线程的创建,使用了很原始的方式,一行代码创建一条。其实,Python里是可以批量创建线程的。利用Python批量创建线程可以将之前的程序优化,具体请看如下的代码:
# -*-coding:utf-8-*-
import threading;
mutex_lock = threading.RLock(); # 互斥锁的声明
ticket = 100000; # 总票数
# 用于统计各个线程的得票数
ticket_stastics=[];
class myThread(threading.Thread): # 线程处理函数
def __init__(self, name):
threading.Thread.__init__(self); # 线程类必须的初始化
self.thread_name = name; # 将传递过来的name构造到类中的name
def run(self):
# 声明在类中使用全局变量
global mutex_lock;
global ticket;
while 1:
mutex_lock.acquire(); # 临界区开始,互斥的开始
# 仅能有一个线程↓↓↓↓↓↓↓↓↓↓↓↓
if ticket > 0:
ticket -= 1;
# 统计哪到线程拿到票
print "线程%s抢到了票!票还剩余:%d。" % (self.thread_name, ticket);
ticket_stastics[self.thread_name]+=1;
else:
break;
# 仅能有一个线程↑↑↑↑↑↑↑↑↑↑↑↑
mutex_lock.release(); # 临界区结束,互斥的结束
mutex_lock.release(); # python在线程死亡的时候,不会清理已存在在线程函数的互斥锁,必须程序猿自己主动清理
print "%s被销毁了!" % (self.thread_name);
# 初始化线程
threads = [];#存放线程的数组,相当于线程池
for i in range(0,5):
thread = myThread(i);#指定线程i的执行函数为myThread
threads.append(thread);#先讲这个线程放到线程threads
ticket_stastics.append(0);# 初始化线程的得票数统计数组
for t in threads:#让线程池中的所有数组开始
t.start();
for t in threads:
t.join();#等待所有线程运行完毕才执行一下的代码
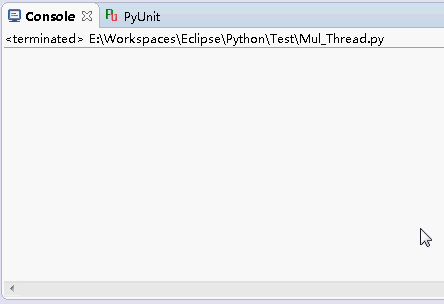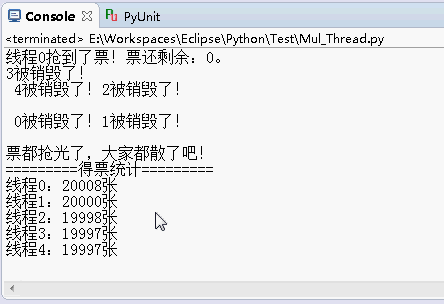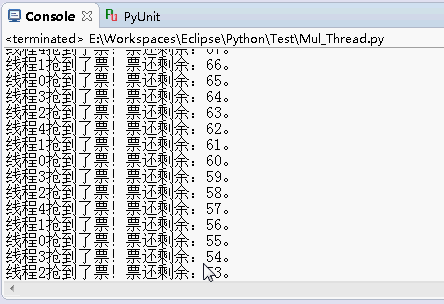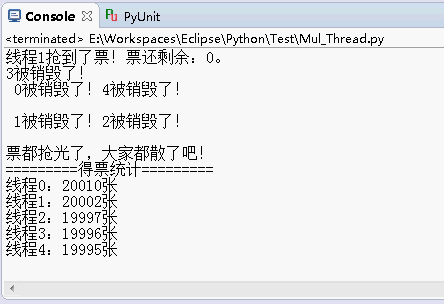
print "票都抢光了,大家都散了吧!";
print "=========得票统计=========";
for i in range(0,len(ticket_stastics)):
print "线程%d:%d张" % (i,ticket_stastics[i]);
运行结果还是原来的功能:
但是,这里利用了一个数组和for循环创建线程,先遍历创建一堆线程放到线程池threads里面,实质上所谓的“线程池”也就是存放线程的数组,再用一个for循环,让这个线程池threads里面的线程全部开始。
# 初始化线程
threads = [];#存放线程的数组,相当于线程池
for i in range(0,5):
thread = myThread(i);#指定线程i的执行函数为myThread
threads.append(thread);#先讲这个线程放到线程threads
for t in threads:#让线程池中的所有数组开始
t.start();
for t in threads:
t.join();#等待所有线程运行完毕才执行一下的代码
待所有线程开始之后,再让主线程,也就是整个主程序,等待所有子线程thread结束才执行下面的代码。
这里不能写成如下的代码段:
for t in threads:#让线程池中的所有数组开始
t.start();
t.join();#等待所有线程运行完毕才执行一下的代码
这样的话,主程序会等待线程0,跑完myThread中的所有代码,才去创建线程1,2,3.....的,这样达不到线程并发的目的,程序变成单线程执行了,这是批量创建线程需要注意的地方。
有注释的详解
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import threading as td
import time
def threadJob():
'''task01'''
threadJob2()
def threadJob2():
'''task02'''
print('create threading: %s'% td.current_thread())
print ('T1 start')
for i in range(10):
time.sleep(0.1)
print('T1 finish\n')
def threadJob3():
'''task03'''
print('create threading: %s'% td.current_thread())
print ('T2 start')
print('T2 finish\n')
def main(*args):
# 创建线程,它要去运行threadJob 命名线程名称T1
added_threading1 = td.Thread(target=threadJob,name='T1')
# 创建第二个线程 执行task03 命名T3
added_threading2 = td.Thread(target=threadJob3,name='T3')
# 开始执行T1(与主线程同时执行)
added_threading1.start()
# 如果使用join() 会先执行完T1进程,再执行下面的程序,还有加载到主线程的意思
added_threading1.join()
# 开始执行T2
added_threading2.start()
# 如果使用join() 会先执行完T3进程,再执行下面的程序,还有加载到主线程的意思
added_threading2.join()
print('\nMian')
# 有多少个激活的线程
print(td.active_count())
# 哪个线程
print(td.enumerate())
# 正在运行的是哪个线程
print(td.current_thread())
if __name__=='__main__':
main()
python:threading.Thread类的使用详解
Python Thread类表示在单独的控制线程中运行的活动。有两种方法可以指定这种活动:
1、给构造函数传递回调对象
mthread=threading.Thread(target=xxxx,args=(xxxx))
mthread.start()
2、在子类中重写run() 方法
这里举个小例子:
import threading, time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
global n, lock
time.sleep(1)
if lock.acquire():
print n , self.name
n += 1
lock.release()
if "__main__" == __name__:
n = 1
ThreadList = []
lock = threading.Lock()
for i in range(1, 200):
t = MyThread()
ThreadList.append(t)
for t in ThreadList:
t.start()
for t in ThreadList:
t.join()
派生类中重写了父类threading.Thread的run()方法,其他方法(除了构造函数)都不应在子类中被重写,换句话说,在子类中只有_init_()和run()方法被重写。使用线程的时候先生成一个子线程类的对象,然后对象调用start()方法就可以运行线程啦(start调用run)
下面我们进入本文的正题threading.Thread类的常用函数与方法:
1、一旦线程对象被创建,它的活动需要通过调用线程的start()方法来启动。这方法再调用控制线程中的run方法。
2、一旦线程被激活,则这线程被认为是’alive’(活动)。当它的run()方法终止时-正常退出或抛出未处理的异常,则活动状态停止。isAlive()方法测试线程是否是活动的。大致上,线程从 start()调用开始那点至它的run()方法中止返回时,都被认为是活动的。模块函数enumerate()返回活动线程的列表。
3、一个线程能调用别的线程的join()方法。这将阻塞调用线程,直到拥有join()方法的线程的调用终止。
4、线程有名字,默认的是Thread-No形式的,名字能传给构造函数,通过setName()方法设置,用getName()方法获取。
5、线程能被标识为’daemon thread’(守护线程).这标志的特点是当剩下的全是守护线程时,则Python程序退出。它的初始值继承于创建线程。标志用setDaemon()方法设置,用isDaemon()获取。
6、存在’main thread’(主线程),它对应于Python程序的初始控制线程。它不是后台线程。
7、
class Thread(group=None, target=None, name=None, args=(), kwargs={})
构造函数能带有关键字参数被调用。这些参数是:
group 应当为 None,为将来实现Python Thread类的扩展而保留。
target 是被 run()方法调用的回调对象. 默认应为None, 意味着没有对象被调用。
name 为线程名字。默认形式为’Thread-N’的唯一的名字被创建,其中N 是比较小的十进制数。
args是目标调用参数的tuple,默认为空元组()。
kwargs是目标调用的参数的关键字dictionary,默认为{}。
8、如果子线程重写了构造函数,它应保证调用基类的构造函数(Thread._init_()),在线程中进行其他工作之前。(也就是派生类刚开始就要调用基类的构造函数)
9、start()
启动线程活动。在每个线程对象中最多被调用一次。它安排对象的run() 被调用在一单独的控制线程中。
10、run()
用以表示线程活动的方法。你可能在Python Thread类的子类重写这方法。标准的 run()方法调用作为target传递给对象构造函数的回调对象。
11、join([timeout])
等待至线程中止。阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
timeout参数不是None,它应当是浮点数指明以秒计的操作超时值。因为join()总是返回None,你必须调用isAlive()来判别超时是否发生。
当timeout 参数没有被指定或者是None时,操作将被阻塞直至线程中止。
线程能被join()许多次。
线程不能调用自身的join(),因为这将会引起死锁。
在线程启动之前尝试调用join()会发生错误。
12、
getName()
返回线程名。
setName(name)
设置线程名。
这名字是只用来进行标识目的的字符串。它没有其他作用。多个线程可以取同一名字。最初的名字通过构造函数设置。
isAlive()
返回线程是否活动的。
isDaemon()
返回线程的守护线程标志。
setDaemon(daemonic)
设置守护线程标志为布尔值daemonic。它必须在start()调用之前被调用。
当没有活动的非守护线程时,整个Python程序退出。















 1536
1536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









