










论文链接:SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
报告链接:https://scalable-interpolant.github.io/
文章目录
- Intro
- Flow and Diffusion
- Scalable Interpolant Transformers
- T i m e s p a c e \color{green}{\bf{Timespace}} Timespace
- M o d e l P r e d i c t i o n \color{#F80}{\bf{Model\,Prediction}} ModelPrediction
- I n t e r p o l a n t \color{purple}{\bf{Interpolant}} Interpolant
- S a m p l e r \color{teal}{\bf{Sampler}} Sampler
- C l a s s i f i e r − f r e e G u i d a n c e \bf{Classifier-free\,Guidance} Classifier−freeGuidance
- Conclusion
最近WALT、VideoPoet、Sora等工作都基于DiT,但主要还是集中在SDEs的原始扩散模型技术路线下,在阅读SD3论文中了解了最近很多工作将扩散生成过程描述为基于flow的插值过程。在此基于DDPM做一个通俗的解释,扩散模型的前向过程,从已知分布中的数据 x ∗ x_* x∗开始,一步步增加随机噪声,到最后成为一个遵循标准正态分布的噪声 ϵ \epsilon ϵ,而在前向过程中每个时间步的值可记为 x t = α t x ∗ + σ t ϵ x_t = \alpha_t x_* + \sigma_t \epsilon xt=αtx∗+σtϵ,就可以理解为是 x ∗ x_* x∗和 ϵ \epsilon ϵ的一个插值,实现了原始数据分布和标准正太分布之间的连接。
DiT团队最近刚好发布了基于DiT架构研究扩散模型插值技术的论文,简称为SiT,论文行文较难理解,感兴趣的读者推荐阅读官方的技术报告,见顶部链接,本文也主要基于技术报告进行初略的解释,因为内容涉及较多公式变换,如有错误,请告知。
Intro
插值框架允许以比标准扩散模型更灵活的方式连接两个数据分布,使得对影响基于动态传输的生成模型的各种设计选择进行模块化研究成为可能:
- 使用离散还是连续时间学习
- 使用何种优化对象
- 插值方式设置涉及的参数选择
- 确定还是随机的采样方式的选择
通过小心引入上述研究点,在条件 ImageNet 256x256 基准测试中,SiT 在使用完全相同的主干网、参数数量和 GFLOP 的条件下,在全模型寸尺上都超越了 DiT。通过探索可与学习分开调整的各种扩散系数,SiT 实现了 2.06 的 FID-50K 分数。

Flow and Diffusion
最近几年,通过将纯噪声
ϵ
∼
N
(
0
,
I
)
\epsilon \sim N(0, I)
ϵ∼N(0,I)转换为数据
x
∗
∼
p
(
x
)
x_* \sim p(x)
x∗∼p(x)一系列灵活的生成模型出现。这种转变可以用一个简单的时间相关过程来描述
x
t
=
α
t
x
∗
+
σ
t
ϵ
x_t = \alpha_t x_* + \sigma_t \epsilon
xt=αtx∗+σtϵ
其中
t
∈
[
0
,
T
]
t \in [0, T]
t∈[0,T],
α
t
,
σ
t
\alpha_t,\sigma_t
αt,σt是时间相关的函数,并且有
x
0
∼
p
(
x
)
,
x
T
∼
N
(
0
,
I
)
x_0 \sim p(x),x_T \sim N(0,I)
x0∼p(x),xT∼N(0,I)。在每个时间步
t
t
t,
x
t
x_t
xt的条件概率密度为
p
t
(
x
∣
x
∗
)
=
N
(
α
t
x
∗
,
σ
t
2
I
)
p_t(x|x_*)=N(\alpha_tx_*,\sigma_t^2I)
pt(x∣x∗)=N(αtx∗,σt2I),目标是估计边际概率密度
p
t
(
x
)
=
∫
p
t
(
x
∣
x
∗
)
p
(
x
)
d
x
p_t(x)=\int p_t(x|x_*)p(x)dx
pt(x)=∫pt(x∣x∗)p(x)dx。在多数情况下,边际概率密度
p
t
(
x
)
p_t(x)
pt(x)是易处理的。一些之前的工作是聚焦在极大似然
log
p
t
(
x
)
\log p_t(x)
logpt(x),而当前方法利用具有相应边际密度
p
t
(
x
)
p_t(x)
pt(x)的微分方程直接从
p
(
x
)
p(x)
p(x)中估计数据样本
Diffusion-Based Models
基于扩散的模型是这种转换最常用的框架。
α
t
\alpha_t
αt 和
σ
t
\sigma_t
σt 由时间方向的随机微分方程 (SDE) 间接设置,以
N
(
0
,
I
)
N(0,I)
N(0,I) 作为平衡分布。
d
X
t
=
f
(
X
t
,
t
)
d
t
+
g
(
t
)
d
W
t
dX_t=f(X_t,t)dt+g(t)dW_t
dXt=f(Xt,t)dt+g(t)dWt
其中
W
t
W_t
Wt是一个标准布朗运动。
在实践中,模型通过在分数匹配目标下使用生成模型
s
θ
(
x
t
,
t
)
s_{\theta}(x_t,t)
sθ(xt,t) 学习似然
∇
log
p
t
(
x
)
\nabla\log p_t(x)
∇logpt(x)(分数)的梯度来对过程进行采样
L
s
(
θ
)
=
∫
E
[
∣
∣
σ
t
s
θ
(
x
t
,
t
)
+
ϵ
∣
∣
2
]
d
t
L_s(\theta)=\int \mathbb{E}[||\sigma_ts_{\theta}(x_t,t)+\epsilon||^2]dt
Ls(θ)=∫E[∣∣σtsθ(xt,t)+ϵ∣∣2]dt
推理过程是通过执行确定的概率流ODE计算
d
X
t
=
[
f
(
X
t
,
t
)
−
1
2
g
2
(
t
)
∇
log
p
t
(
x
)
]
d
t
dX_t=[f(X_t,t)-\frac{1}{2}g^2(t)\nabla \log p_t(x)]dt
dXt=[f(Xt,t)−21g2(t)∇logpt(x)]dt
或一个随机的逆向时间SDE计算
d
X
t
=
[
f
(
X
t
,
t
)
−
g
2
(
t
)
∇
log
p
t
(
x
)
]
d
t
+
g
(
t
)
d
W
ˉ
t
dX_t=[f(X_t,t)-g^2(t)\nabla \log p_t(x)]dt+g(t)d\bar{W}_t
dXt=[f(Xt,t)−g2(t)∇logpt(x)]dt+g(t)dWˉt
其中
W
ˉ
t
\bar{W}_t
Wˉt是一个逆向时间的标准布朗运动。对上述两个方程,以高斯噪声的初始条件看似是,从时间步 t=T 到 t=0 ,可以推导出近似
p
(
x
)
p(x)
p(x) 的数据样本
Stochastic Interpolant and Flow-Based Models
随机插值和其他基于流的模型是该系列的最新成员,其中 α t \alpha_t αt 和 σ t \sigma_t σt被限制在时间区间 [ 0 , 1 ] [0,1] [0,1],且 α 0 = σ 1 = 1 , α 1 = σ 0 = 0 \alpha_0=\sigma_1=1,\alpha_1=\sigma_0=0 α0=σ1=1,α1=σ0=0,因此 x t x_t xt恰好在 x ∗ x_* x∗和 ϵ \epsilon ϵ之间插值。注意这为插值函数的选择提供了更大的灵活性,因为它们不再受前向 SDE 的影响
此外,这些模型使用更简单的概率流 ODE 进行推理
d
X
t
=
[
f
(
X
t
,
t
)
−
1
2
g
2
(
t
)
∇
log
p
t
(
x
)
]
⏟
d
i
r
e
c
t
l
y
l
e
a
r
n
t
h
i
s
d
t
dX_t=\underbrace{[f(X_t,t)-\frac{1}{2}g^2(t)\nabla \log p_t(x)]}_{directly\,learn\, this}dt
dXt=directlylearnthis
[f(Xt,t)−21g2(t)∇logpt(x)]dt
⟹
d
X
t
=
v
(
X
t
,
t
)
d
t
\implies dX_t=v(X_t,t)dt
⟹dXt=v(Xt,t)dt
其中向量场velocity
v
(
X
t
,
t
)
v(X_t,t)
v(Xt,t)由flow matching目标估计
L
v
(
θ
)
=
∫
E
[
∣
∣
v
(
X
,
t
)
−
α
˙
t
x
∗
−
σ
˙
t
ϵ
∣
∣
2
]
d
t
L_v(\theta)=\int \mathbb{E}[||v(X,t)-\dot{\alpha}_tx_* - \dot{\sigma}_t\epsilon||^2]dt
Lv(θ)=∫E[∣∣v(X,t)−α˙tx∗−σ˙tϵ∣∣2]dt
直观上,这可以被视为预测粒子在时间
t
t
t 从某个
ε
ε
ε 开始移动的速度
将上述模型的组成部分总结如下表:
Diffusion-Based
Flow-Based
t
{
0
,
⋅
⋅
⋅
,
T
}
(
D
D
P
M
)
/
[
0
,
1
]
(
S
B
D
M
)
[
0
,
1
]
L
(
θ
)
L
s
∼
∣
∣
σ
t
s
θ
(
x
t
,
t
)
+
ϵ
∣
∣
2
L
v
∼
∣
∣
v
θ
(
x
t
,
t
)
−
α
˙
t
x
∗
−
σ
˙
t
ϵ
∣
∣
2
x
t
α
t
x
+
σ
t
ϵ
α
t
x
+
σ
t
ϵ
O
D
E
d
X
t
=
[
f
(
X
t
,
t
)
−
1
2
g
2
(
t
)
∇
log
p
t
(
x
)
]
d
t
d
X
t
=
v
(
X
t
,
t
)
d
t
S
D
E
d
X
t
=
[
f
(
X
t
,
t
)
−
g
2
(
t
)
∇
log
p
t
(
x
)
]
d
t
+
g
(
t
)
d
W
ˉ
t
?
\begin{array}{lll} \hline & \text{Diffusion-Based} & \text{Flow-Based} \\ \hline t & \{0,\cdot\cdot\cdot,T\}(DDPM) / [0,1](SBDM) & [0,1] \\ L(\theta) & L_s \sim ||\sigma_ts_{\theta}(x_t,t)+\epsilon||^2 & L_v \sim ||v_{\theta}(x_t,t)-\dot{\alpha}_tx_* - \dot{\sigma}_t\epsilon||^2 \\ x_t & \alpha_tx+\sigma_t\epsilon & \alpha_tx+\sigma_t\epsilon \\ ODE & dX_t=[f(X_t,t)-\frac{1}{2}g^2(t)\nabla \log p_t(x)]dt & dX_t=v(X_t,t)dt \\ SDE & dX_t=[f(X_t,t)-g^2(t)\nabla \log p_t(x)]dt+g(t)d\bar{W}_t & ? \\ \hline \end{array}
tL(θ)xtODESDEDiffusion-Based{0,⋅⋅⋅,T}(DDPM)/[0,1](SBDM)Ls∼∣∣σtsθ(xt,t)+ϵ∣∣2αtx+σtϵdXt=[f(Xt,t)−21g2(t)∇logpt(x)]dtdXt=[f(Xt,t)−g2(t)∇logpt(x)]dt+g(t)dWˉtFlow-Based[0,1]Lv∼∣∣vθ(xt,t)−α˙tx∗−σ˙tϵ∣∣2αtx+σtϵdXt=v(Xt,t)dt?
当
α
t
\alpha_t
αt和
σ
t
\sigma_t
σt相同时,扩散和基于流的方法共享相同的时间演化过程已被证明;基于流的 ODE 对应的
p
t
(
x
)
p_t(x)
pt(x) 与基于扩散的 ODE 和 SDE 的一致。本工作继续证明上表中其他组件的数学等价性和性能影响。还通过展示基于流的方法也可以通过逆向 SDE 进行采样来填补上表中的问号,尽管缺乏正向 SDE。
Scalable Interpolant Transformers
从上表中,将设计空间总结为四个部分:
- T i m e s p a c e \color{green}{\bf{Timespace}} Timespace:离散或连续时间间隔
- M o d e l P r e d i c t i o n \color{#F80}{\bf{Model\,Prediction}} ModelPrediction:优化对象 L S L_S LS和 L v L_v Lv的选择
- I n t e r p o l a n t \color{purple}{\bf{Interpolant}} Interpolant:插值参数 α t \alpha_t αt和 σ t \sigma_t σt的选择
- S a m p l e r \color{teal}{\bf{Sampler}} Sampler:ODE或SDE
在设计空间中系统地改变这些组件,构建了 SiT 模型,在 256 × 256 ImageNet 图像生成任务,SiT全面优于DiT
Model
Params(M)
Training Steps
FID ↓
D
i
T
−
S
33
400
K
68.4
S
i
T
−
S
33
400
K
57.6
D
i
T
−
B
130
400
K
43.5
S
i
T
−
B
130
400
K
33.5
D
i
T
−
L
458
400
K
19.5
S
i
T
−
L
458
400
K
17.2
D
i
T
−
X
L
675
400
K
9.6
S
i
T
−
X
L
675
400
K
8.6
D
i
T
−
X
L
(
c
f
g
=
1.5
)
675
7
M
2.27
S
i
T
−
X
L
(
c
f
g
=
1.5
)
675
7
M
2.06
\begin{array}{lccc} \hline \text{Model} & \text{Params(M)} & \text{Training Steps} & \text{FID ↓} \\ \hline DiT-S & 33 & 400K & 68.4 \\ SiT-S & 33 & 400K & \bf{57.6} \\ DiT-B & 130 & 400K & 43.5 \\ SiT-B & 130 & 400K & \bf{33.5} \\ DiT-L & 458 & 400K & 19.5 \\ SiT-L & 458 & 400K & \bf{17.2} \\ DiT-XL & 675 & 400K & 9.6 \\ SiT-XL & 675 & 400K & \bf{8.6} \\ DiT-XL_{(cfg=1.5)} & 675 & 7M & 2.27 \\ SiT-XL_{(cfg=1.5)} & 675 & 7M & \bf{2.06} \\ \hline \end{array}
ModelDiT−SSiT−SDiT−BSiT−BDiT−LSiT−LDiT−XLSiT−XLDiT−XL(cfg=1.5)SiT−XL(cfg=1.5)Params(M)3333130130458458675675675675Training Steps400K400K400K400K400K400K400K400K7M7MFID ↓68.457.643.533.519.517.29.68.62.272.06
为了研究这种性能改进,通过设计空间中的一系列正交步骤逐渐从 DiT 模型(一种典型的去噪扩散模型(
离散
\color{green}{离散}
离散、
去噪
\color{#F80}{去噪}
去噪、
方差保留
\color{purple}{方差保留}
方差保留和
S
D
E
\color{teal}{SDE}
SDE))过渡到 SiT 模型。随着进展,会仔细评估每个远离扩散模型的举措如何影响以下部分的性能
为了进行此研究,使用相同的 DiT-B 主干架构和所有模型的训练超参数;还保持所有模型的参数数量、GFLOP 和训练计划(40 万步)相同。表中提供的所有数字都是针对 ImageNet 256 训练集评估的 FID-50K 分数,并由 250 步 Heun ODE 求解器生成,除非另有说明。为了求解 SDE,使用了 Euler-Maruyama 积分器
T i m e s p a c e \color{green}{\bf{Timespace}} Timespace
第一个举措已经经过充分研究:从离散时间去噪模型切换到连续时间评分模型。观察到边际性能改善:
Objective
FID ↓
D
D
P
M
L
s
†
44.2
S
B
D
M
L
s
43.6
†
表示
D
D
P
M
使用离散目标
\begin{array}{lcc} \hline & \text{Objective} & \text{FID ↓} \\ \hline DDPM & L_s^{\dag} & 44.2 \\ SBDM & L_s & \bf{43.6} \\ \hline \end{array} \\ \begin{array}{c} \dag 表示DDPM使用离散目标 \end{array}
DDPMSBDMObjectiveLs†LsFID ↓44.243.6†表示DDPM使用离散目标
M o d e l P r e d i c t i o n \color{#F80}{\bf{Model\,Prediction}} ModelPrediction
称
v
e
l
o
c
i
t
y
velocity
velocity 模型通过时间相关的加权函数与
s
c
o
r
e
score
score 模型相关。具体来说:
v
(
x
t
,
t
)
=
α
˙
t
α
t
x
t
−
λ
t
σ
t
s
(
x
t
,
t
)
v(x_t,t) = \frac{\dot{\alpha}_t}{\alpha_t}x_t - \lambda_t\sigma_ts(x_t,t)
v(xt,t)=αtα˙txt−λtσts(xt,t)
其中
λ
t
=
σ
˙
t
−
α
˙
t
σ
t
α
t
\lambda_t=\dot{\sigma}_t-\frac{\dot{\alpha}_t\sigma_t}{\alpha_t}
λt=σ˙t−αtα˙tσt。将这个线性关系代入
L
v
L_v
Lv,获得
L
v
(
θ
)
=
∫
0
T
λ
t
2
E
[
∣
∣
σ
t
s
θ
(
x
t
,
t
)
+
ϵ
∣
∣
2
]
d
t
=
L
s
λ
(
θ
)
\begin{array}{rl} L_v(\theta) = & \int_0^T \lambda_t^2\mathbb{E}[||\sigma_ts_{\theta}(x_t,t)+\epsilon||^2]dt \\ = & L_{s\lambda}(\theta) \\ \end{array}
Lv(θ)==∫0Tλt2E[∣∣σtsθ(xt,t)+ϵ∣∣2]dtLsλ(θ)
对应于由不同时间相关函数加权的普通去噪目标的扩散模型的不同模型预测,训练了所有三个模型并给出了下面的结果
I
n
t
e
r
p
o
l
a
n
t
Objective
FID ↓
S
B
D
M
−
V
P
L
s
43.6
S
B
D
M
−
V
P
L
s
λ
39.1
S
B
D
M
−
V
P
L
v
39.8
\begin{array}{lcc} \hline Interpolant & \text{Objective} & \text{FID ↓} \\ \hline SBDM-VP & L_s & 43.6 \\ SBDM-VP & L_{s\lambda} & \bf{39.1} \\ SBDM-VP & L_v & 39.8 \\ \hline \end{array} \\
InterpolantSBDM−VPSBDM−VPSBDM−VPObjectiveLsLsλLvFID ↓43.639.139.8
在方差保留设置下当
t
→
0
,
σ
t
˙
→
−
∞
t \to 0,\,\dot{\sigma_t} \to -\infty
t→0,σt˙→−∞,使
λ
t
2
\lambda_t^2
λt2 随之暴增到无穷大。在实践中,遵循 SBDM 的设置,将训练和采样剪辑到区间
[
ϵ
,
1
]
[\epsilon,1]
[ϵ,1] 以避免数值稳定性。因此,较大的
λ
ϵ
\lambda_{\epsilon}
λϵ 能够补偿
L
s
L_s
Ls的梯度消失,但反过来又使
L
v
L_v
Lv 更难优化

I n t e r p o l a n t \color{purple}{\bf{Interpolant}} Interpolant
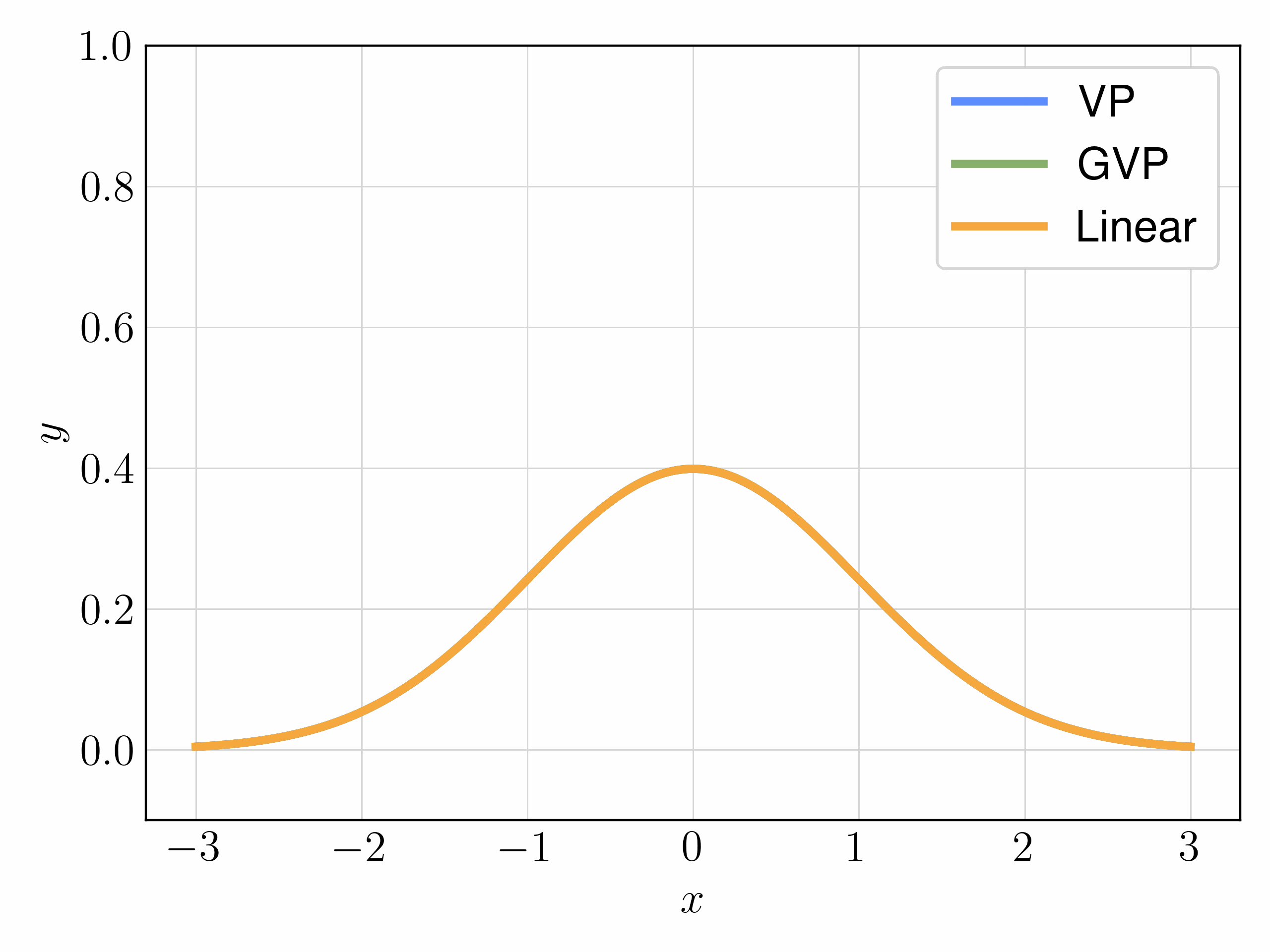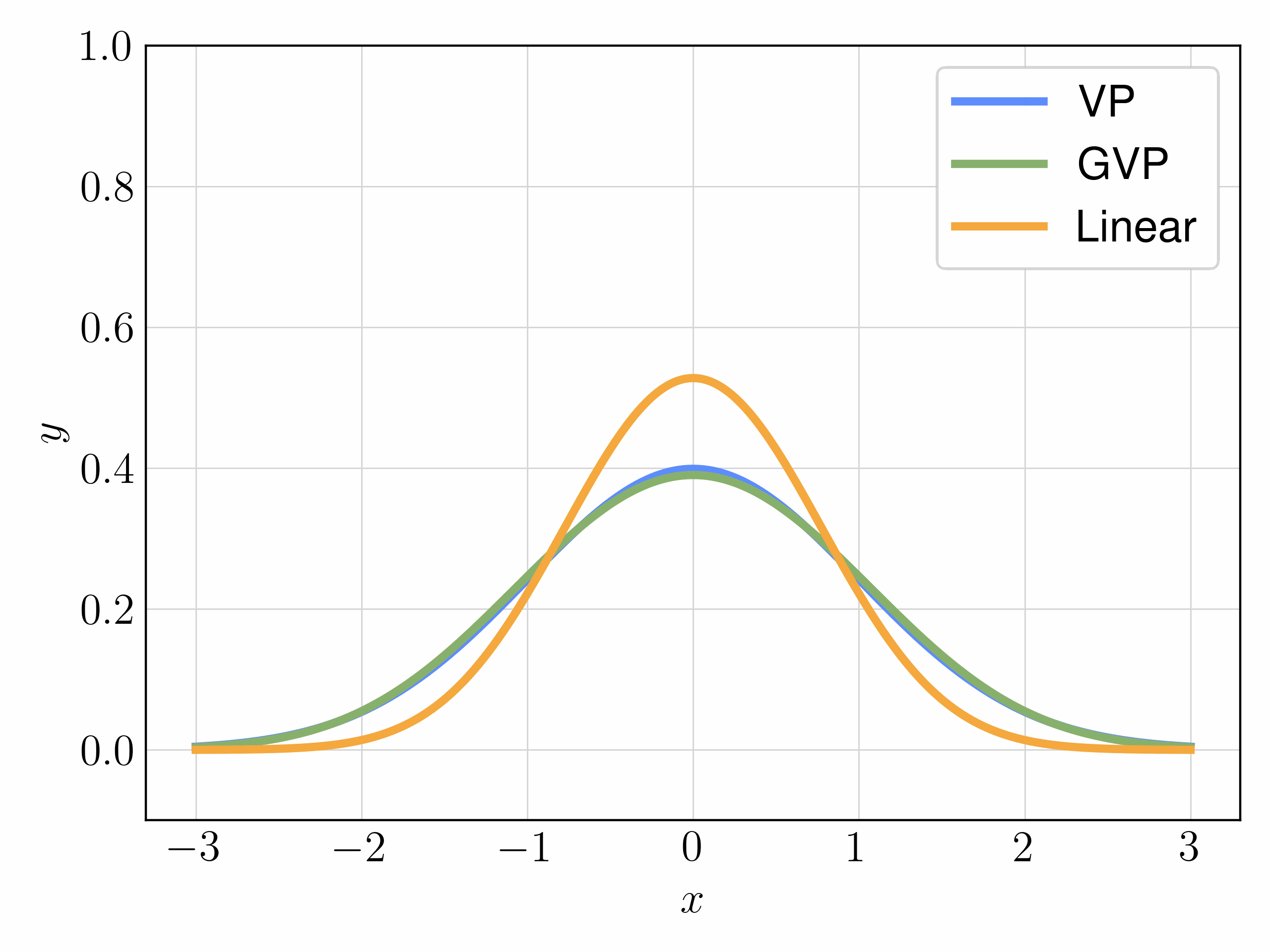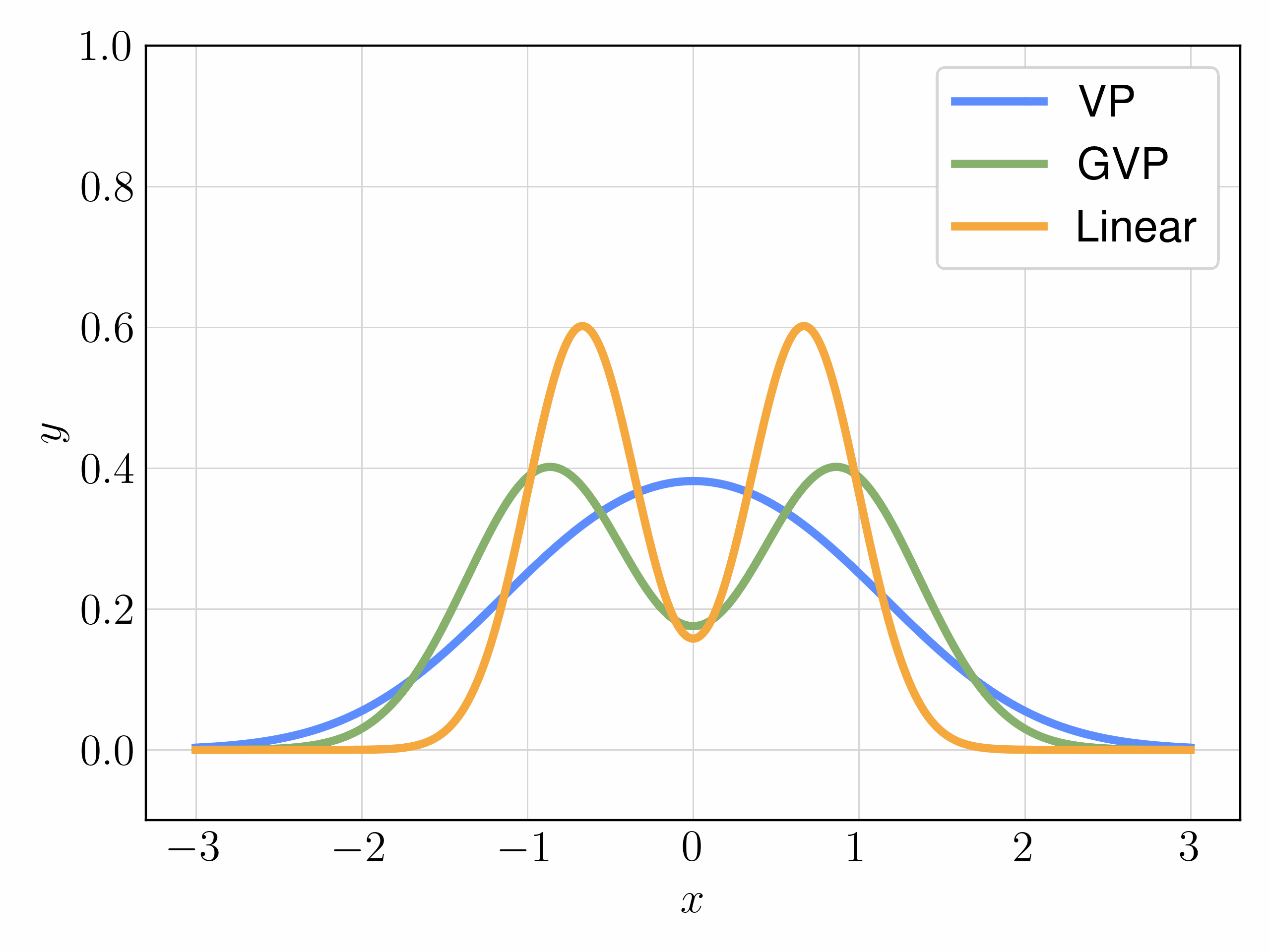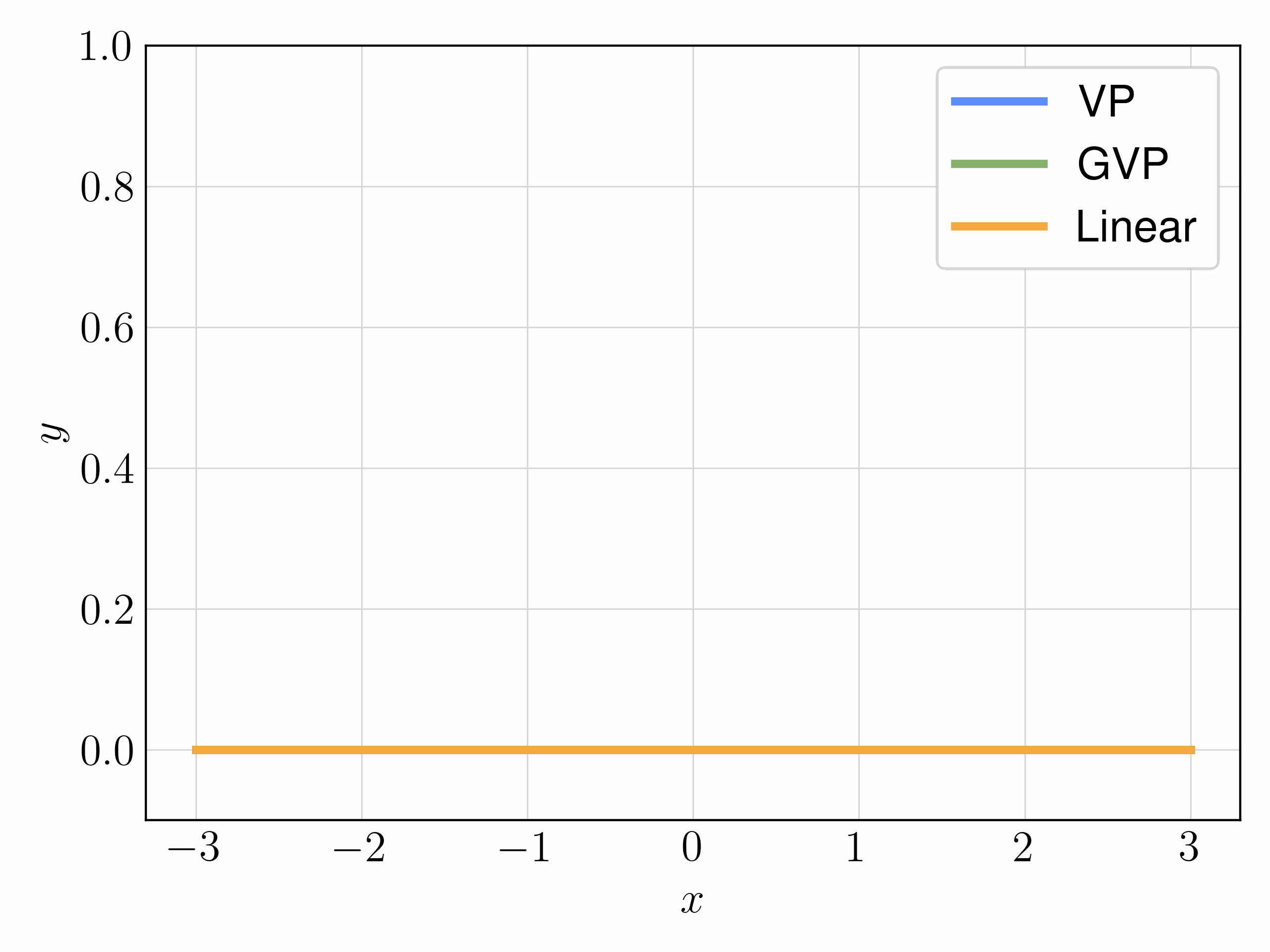
主要尝试三种插值器的选择:
- V P : α t = e − 1 2 ∫ 0 t β s d s , σ t = 1 − e − ∫ 0 t β s d s \bf{VP}:\alpha_t=e^{-\frac{1}{2} \int_0^t\beta_sds},\,\sigma_t=\sqrt{1-e^{- \int_0^t\beta_sds}} VP:αt=e−21∫0tβsds,σt=1−e−∫0tβsds
- G V P : α t = cos ( 1 2 π t ) , σ t = sin ( 1 2 π t ) \bf{GVP}:\alpha_t=\cos{(\frac{1}{2}\pi t)},\,\sigma_t=\sin{(\frac{1}{2}\pi t)} GVP:αt=cos(21πt),σt=sin(21πt)
- L i n e a r : α t = 1 − t , σ t = t \bf{Linear}:\alpha_t=1-t,\,\sigma_t=t Linear:αt=1−t,σt=t
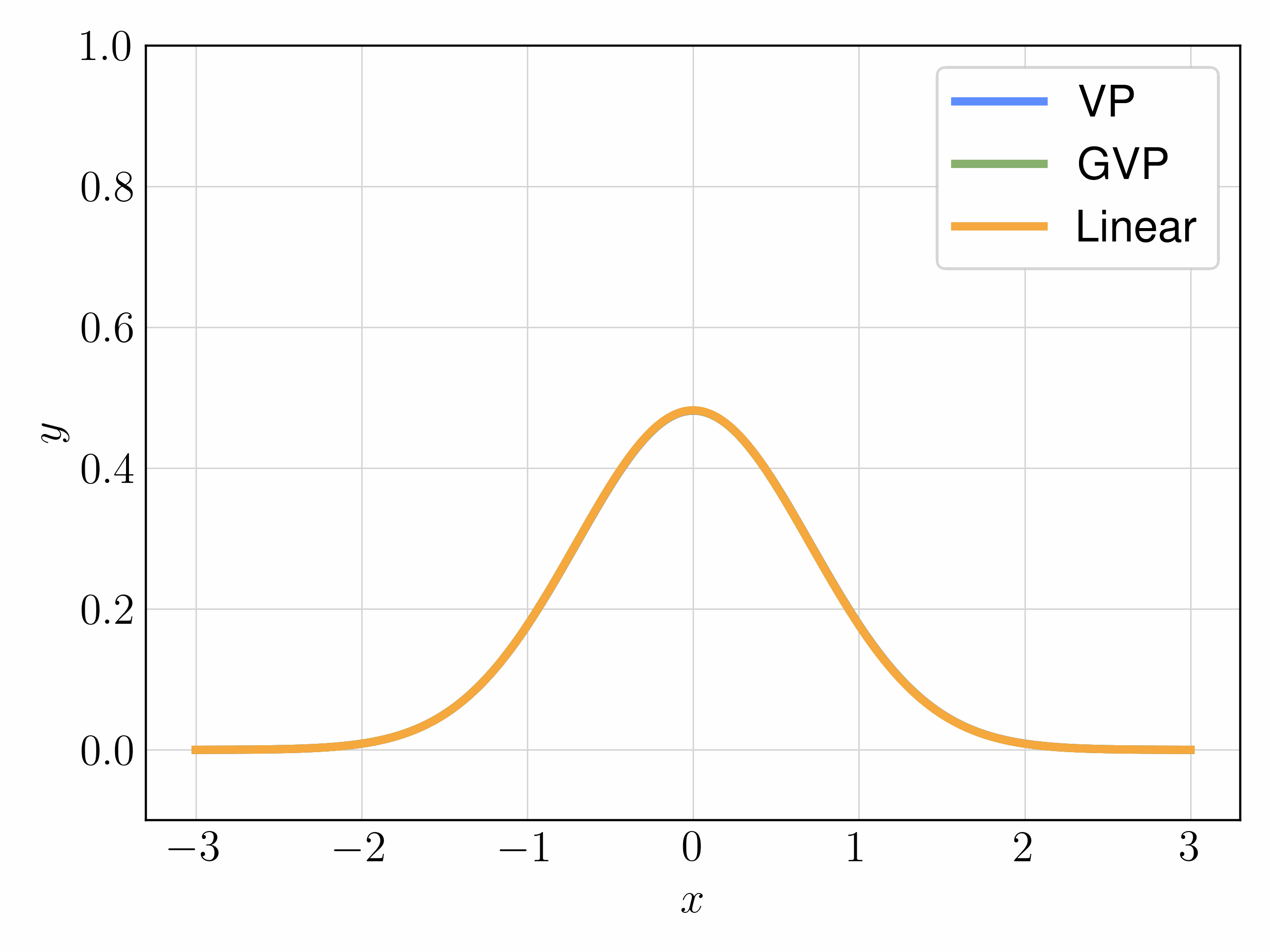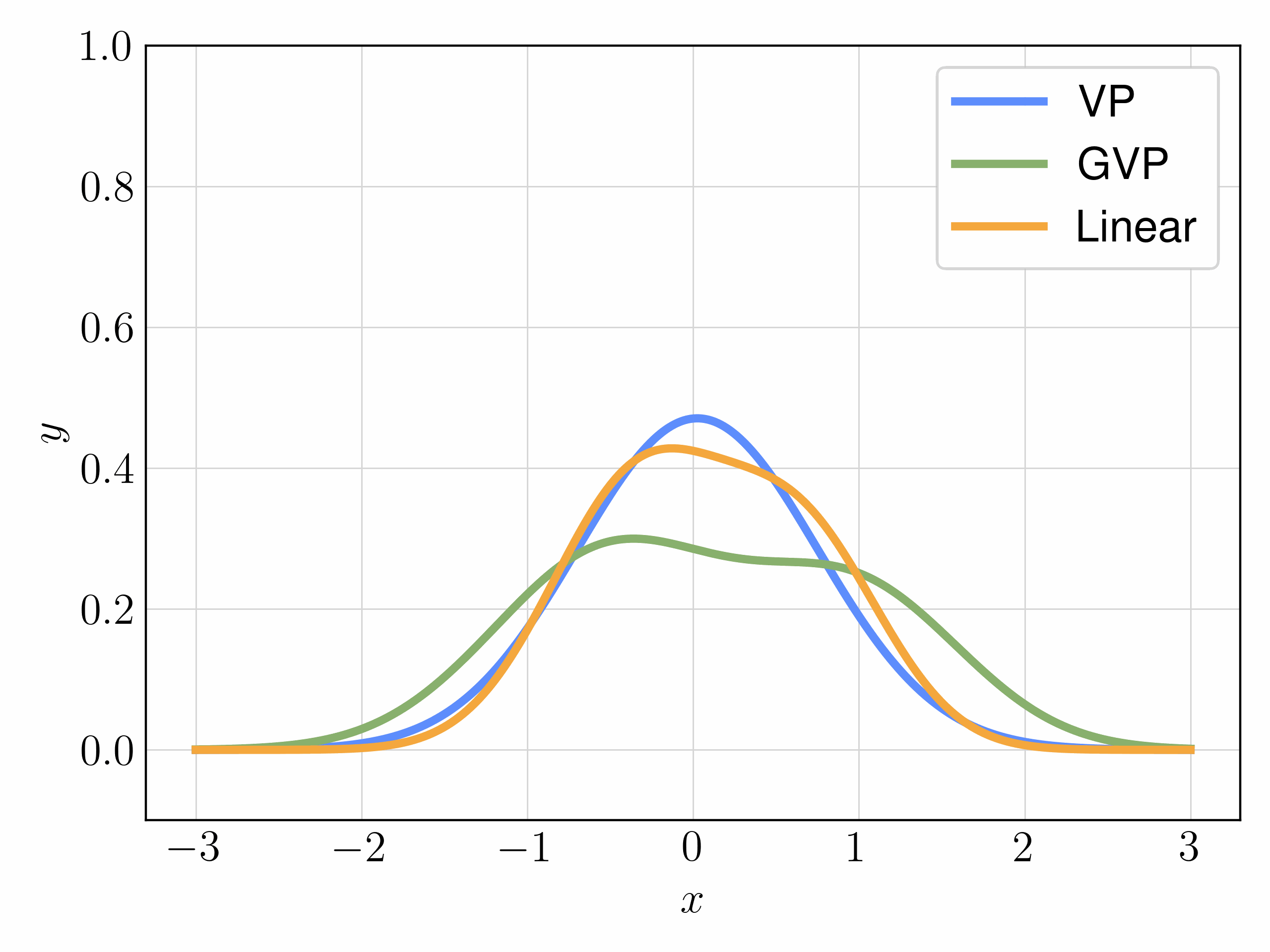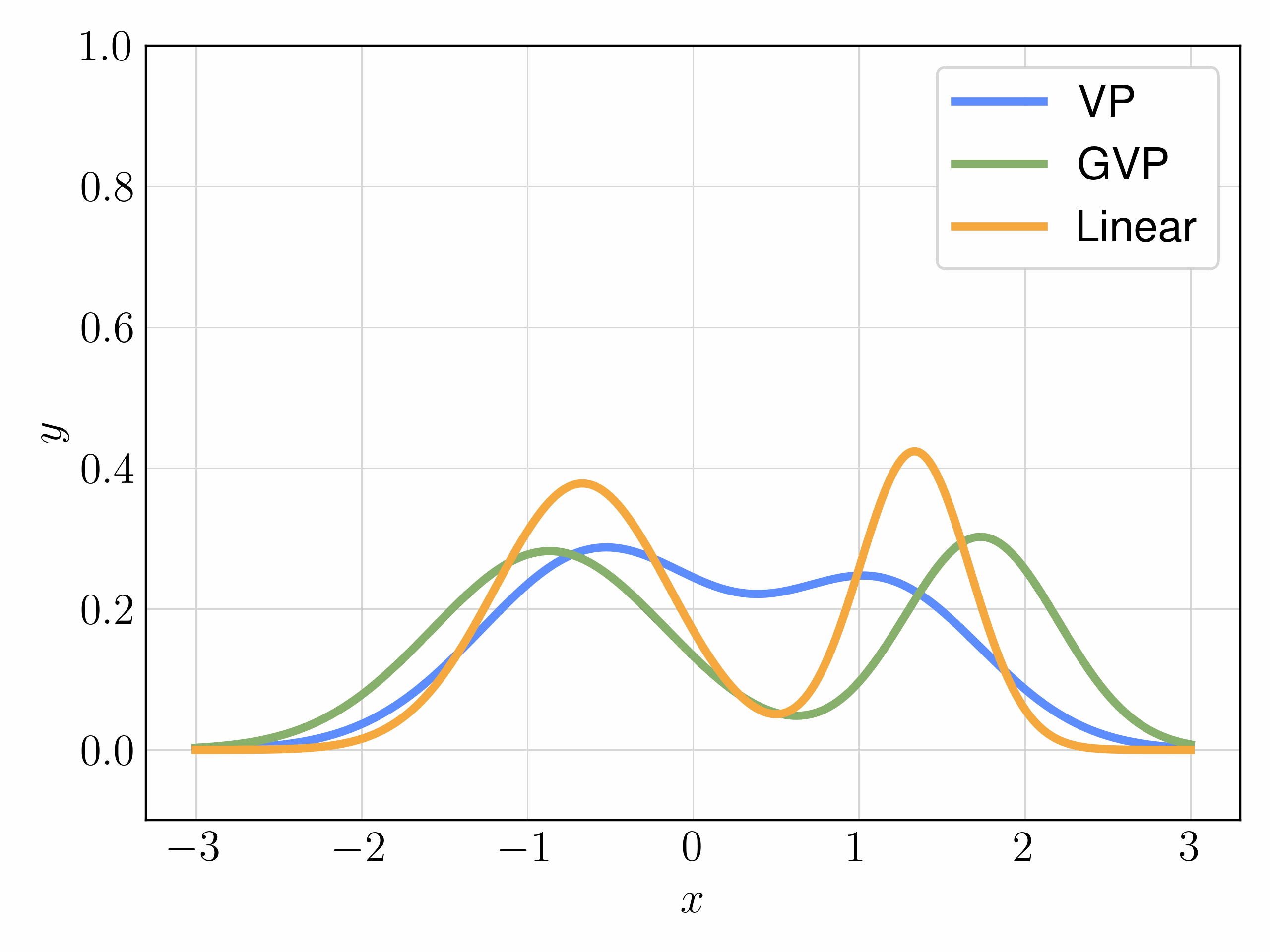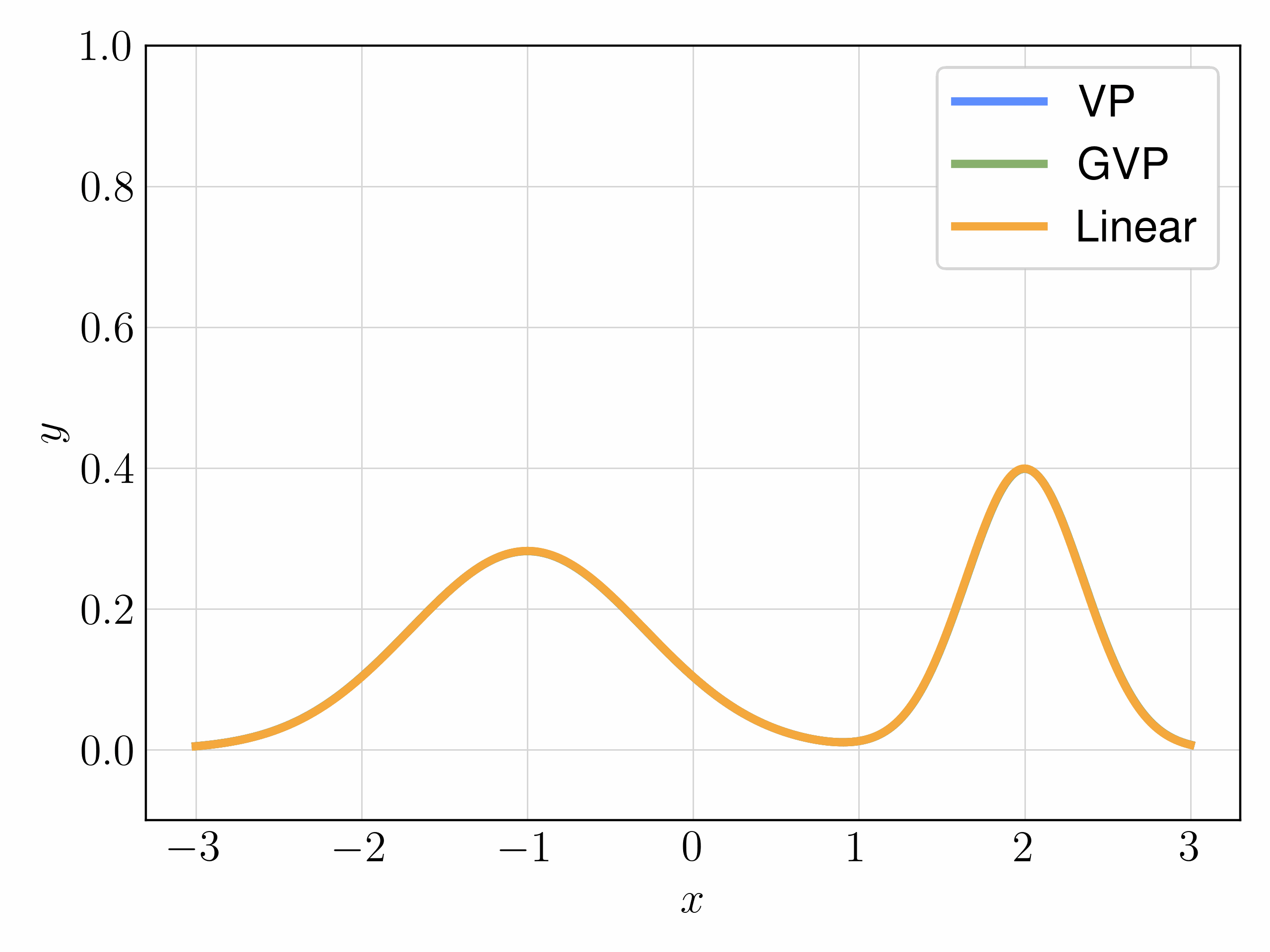
以下动图链接是一些示例,表明上述插值方式在简单一维分布上的影响。在从标准高斯分布开始的对齐时间间隔上,注意到 VP 插值在两种情况下变化最为剧烈,而 GVP 和线性插值则更加平滑。直观上,VP插值的这种突变增加了速度场的Lipschitz常数,使其学习更加困难
https://scalable-interpolant.github.io/images/intpl.gif
https://scalable-interpolant.github.io/images/intpl_2.gif
下图给出了对此观察结果的一种可能解释,其中看到从 SBDM-VP 更改为 GVP 或线性时,路径长度(传输成本)减少了。在数值上,还注意到,GVP 和线性插值不会出现
t
=
0
t=0
t=0 时
σ
˙
t
\dot{\sigma}_t
σ˙t的奇异性问题,使模型更容易在数据分布附近学习

S a m p l e r \color{teal}{\bf{Sampler}} Sampler
本节介绍对
v
e
l
o
c
i
t
y
velocity
velocity 模型进行采样的更多灵活性。首先,在SBDM设置下,
v
e
l
o
c
i
t
y
velocity
velocity的逆时SDE可以通过以下方式构造:
d
X
t
=
[
v
(
X
t
,
t
)
−
1
2
g
2
(
t
)
s
(
X
t
,
t
)
]
d
t
+
g
(
t
)
d
W
ˉ
t
dX_t=[v(X_t,t)-\frac{1}{2}g^2(t)s(X_t,t)]dt+g(t)d\bar{W}_t
dXt=[v(Xt,t)−21g2(t)s(Xt,t)]dt+g(t)dWˉt
利用
v
e
l
o
c
i
t
y
velocity
velocity 和
s
c
o
r
e
score
score 之间的线性关系来构造漂移项,将
g
(
t
)
g(t)
g(t) 表示为 SBDM 扩散系数。按照前面的部分,还可以为 GVP 和线性插值构造这样的 SDE,给定关系
g
2
(
t
)
=
2
λ
t
σ
t
g^2(t)=2\lambda_t\sigma_t
g2(t)=2λtσt,结果如下
I
n
t
e
r
p
o
l
a
n
t
Objective
ODE
SDE
S
B
D
M
−
V
P
L
v
39.8
37.8
G
V
P
L
v
34.6
32.9
L
i
n
e
a
r
L
v
34.8
33.6
\begin{array}{cccc} \hline Interpolant & \text{Objective} & \text{ODE} & \text{SDE}\\ \hline SBDM-VP & L_v & 39.8 & 37.8 \\ GVP & L_v & 34.6 & \bf{32.9} \\ Linear & L_v & 34.8 & 33.6 \\ \hline \end{array} \\
InterpolantSBDM−VPGVPLinearObjectiveLvLvLvODE39.834.634.8SDE37.832.933.6
进一步提出,扩散系数
g
(
t
)
g(t)
g(t) 可以与学习过程分开调整。事实上,任何非负函数
w
(
t
)
w(t)
w(t)(不一定单调)都可以用作扩散系数,因此逆时 SDE 可以推广为
d
X
t
=
[
v
(
X
t
,
t
)
−
1
2
w
(
t
)
s
(
X
t
,
t
)
]
d
t
+
w
(
t
)
d
W
ˉ
t
dX_t=[v(X_t,t)-\frac{1}{2}w(t)s(X_t,t)]dt+\sqrt{w(t)}d\bar{W}_t
dXt=[v(Xt,t)−21w(t)s(Xt,t)]dt+w(t)dWˉt
除了SBDM系数之外,还尝试了
w
(
t
)
=
σ
t
w(t)=σ_t
w(t)=σt(以消除数据分布附近分数的奇异性)和
w
(
t
)
=
s
i
n
2
(
π
t
)
w(t)=sin^2(πt)
w(t)=sin2(πt),以及它们对速度或分数模型的影响

注意到,扩散系数的最佳选择取决于插值和目标,并且在实验中,也很大程度上取决于模型大小。根据经验,观察到 SiT-XL 的最佳选择是采用 线性 \color{purple}{线性} 线性 插值的连续时间 v e l o c i t y \color{#F80}{velocity} velocity 模型,并使用具有 w ( t ) = σ t w(t)=σ_t w(t)=σt 系数的 S D E \color{teal}{SDE} SDE 进行采样。
最后,注意到 ODE 和 SDE 积分器的性能在不同的计算预算下可能会有所不同。如下所示,ODE 在函数评估数量较少的情况下收敛速度更快,而 SDE 在给定较大的计算预算时能够达到低得多的最终 FID 分数

C l a s s i f i e r − f r e e G u i d a n c e \bf{Classifier-free\,Guidance} Classifier−freeGuidance
本节给出了在速度模型上采用它的简明理由,然后凭经验证明 DiT 情况下性能的巨大提升也适用于 SiT。
速度场的指导:
- 速度模型 v θ ( x t , t , y ) v_θ(x_t,t,y) vθ(xt,t,y) 在训练期间采用类标签 y y y,其中 y y y 偶尔会被空标记 ∅ ∅ ∅掩盖
- 采样期间,使用的速度为
v
θ
ζ
(
x
t
,
t
,
y
)
=
ζ
v
θ
(
x
t
,
t
,
y
)
+
(
1
−
ζ
)
v
θ
(
x
t
,
t
,
∅
)
v_θ^{\zeta}(x_t,t,y)=\zeta v_θ(x_t,t,y)+(1−\zeta)v_θ(x_t,t,∅)
vθζ(xt,t,y)=ζvθ(xt,t,y)+(1−ζ)vθ(xt,t,∅),固定
ζ
>
0
\zeta>0
ζ>0
鉴于这一观察结果,可以利用基于分数的模型的无分类器指导的常见论点。对于 ζ = 1.5 \zeta=1.5 ζ=1.5 级的 CFG,DiT-XL 的 FID 从 9.6(非 CFG)下降到 2.27(CFG)。在相同的计算预算和 CFG 规模下,观察到最大的 SiT-XL 模型的类似性能改进。使用 ODE 采样,FID-50K 分数从 9.4 改善到 2.15;使用 SDE,FID 从 8.6 改善到 2.06。这表明 SiT 受益于之前探索的相同训练和采样选择,并且可以超越 DiT 在每个训练设置中的性能,不仅在模型大小方面,而且在采样选择方面。

Conclusion
这项工作提出了Scalable Interpolant Transformers,是一个用于图像生成任务的简单而强大的框架。 在该框架内,探索了许多关键设计选择之间的权衡:连续或离散时间模型的选择、插值的选择、模型预测的选择以及采样器的选择。 工作强调了每种选择的优点和缺点,并展示了谨慎的决策如何能够带来显着的性能改进

















 4334
4334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}