






 本文介绍了如何使用Python和Keras进行深度学习,涵盖了数据预处理的重要步骤,包括离散类别值和连续值的编码。讨论了四种基本数据类型、标准化方法如Z-Score,以及如何处理分类数据,如虚拟变量编码和目标编码。此外,还提到了序号编码技术,适用于有序分类数据。内容涉及统计测量水平、数据清理、特征工程和防止过拟合的策略。
本文介绍了如何使用Python和Keras进行深度学习,涵盖了数据预处理的重要步骤,包括离散类别值和连续值的编码。讨论了四种基本数据类型、标准化方法如Z-Score,以及如何处理分类数据,如虚拟变量编码和目标编码。此外,还提到了序号编码技术,适用于有序分类数据。内容涉及统计测量水平、数据清理、特征工程和防止过拟合的策略。
Applications of Deep Neural Networks with Keras
基于Keras的深度神经网络应用
著:Jeff Heaton 译:人工智能学术前沿
目录
1.Python基础
2.机器学习Python
3.TensorFlow简介
4.表格类数据的训练
5.正则化和Dropout
6.用于计算机视觉的卷积神经网络
7.生成对抗网络
8.Kaggle数据集
9.迁移学习
10.Keras的时间序列
11.自然语言处理与语音识别
12.强化学习
13.Advanced/Other Topics
14.其他神经网络技术
2.2 离散类别值与连续值
Part 2.2: Categorical and Continuous Values
神经网络要求它们的输入是固定数量的列。这种输入格式非常类似于电子表格数据。这个输入必须是完全数字的。
用一种神经网络可以从中进行训练的方式来表示数据是至关重要的。在第6课中,我们将看到更多预处理数据的方法。现在,我们将看几个最基本的方法来转换神经网络的数据。
在我们讨论预处理数据的具体方法之前,重要的是考虑四种基本类型的数据,这是由[引用:stevens1946理论]定义的。统计学家通常称之为测量水平:
1.字符数据(字符串)
标称-个别离散的项目,没有顺序。例如,颜色,邮政编码,形状。
顺序-个别不同的项目有一个隐含的顺序。例如等级、头衔、星巴克咖啡大小(高杯、大杯、大杯)
2.数值型数据
间隔-数值值,没有定义开始。例如,温度。你永远不会说:“昨天比今天热两倍。”
比率-数值,明确定义开始。例如,速度。你会说“第一辆车的速度是第二辆车的两倍。”
连续值的编码
Encoding Continuous Values
一种常见的转换是对输入进行规范化。有时,将数字输入规范化以标准形式放置是很有价值的,以便程序可以轻松地比较这两个值。想想如果一个朋友告诉你他得到了10美元的折扣。这划算吗?也许吧。但是成本并不是标准化的。如果你的朋友买了一辆车,那么折扣就不是那么好了。如果你的朋友买了晚餐,这是一个极好的折扣!
百分比是一种普遍的标准化形式。如果你的朋友告诉你他们打了九折,我们知道这比打五折要划算。不管购买价格是多少。一种广泛使用的机器学习标准化是Z-Score:

下面的Python代码用z-score替换mpg。汽车的平均MPG将接近于零,高于零是高于平均,低于零是低于平均。z分数高于/低于-3/3的情况非常罕见,这些都是异常值。
import os
import pandas as pd
from scipy.stats import zscore
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA','?'])
pd.set_option('display.max_columns', 7)
pd.set_option('display.max_rows', 5)
df['mpg'] = zscore(df['mpg'])
display(df)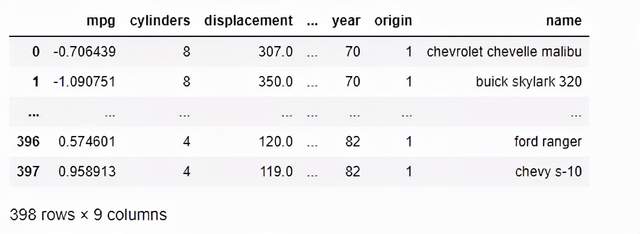
对类别变量进行编码
Encoding Categorical Values as Dummies
传统的分类值编码方法是将分类值设为虚拟变量。这种技术也称为一次热编码。考虑以下数据集。
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/jh-simple-dataset.csv",
na_values=['NA','?'])
pd.set_option('display.max_columns', 7)
pd.set_option('display.max_rows', 5)
display(df)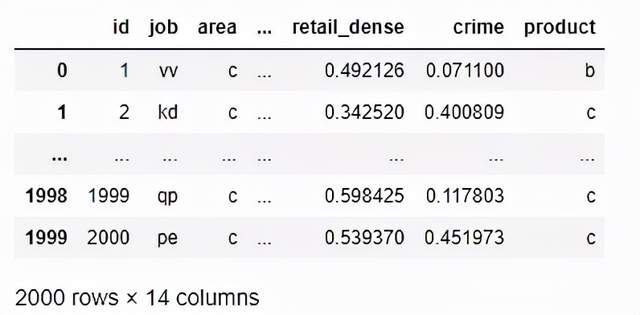
areas = list(df['area'].unique())
print(f'Number of areas: {len(areas)}')
print(f'Areas: {areas}')输出
Number of areas: 4
Areas: ['c', 'd', 'a', 'b']
在区域列中有四个独特的值。为了将这些编码为虚拟变量,我们将使用四列,每列代表一个区域。对于每一行,有一列的值为1,其余为0。由于这个原因,这种类型的编码有时被称为一次性编码。下面的代码展示了如何对值“a”到“d”进行编码。值A变成[1,0,0,0],值B变成[0,1,0,0]。
dummies = pd.get_dummies(['a','b','c','d'],prefix='area')
print(dummies)
dummies = pd.get_dummies(df['area'],prefix='area')
print(dummies[0:10]) # Just show the first 10
df = pd.concat([df,dummies],axis=1)要对“area”列进行编码,我们使用以下方法。注意,有必要将这些假人合并回数据帧中。
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df[['id','job','area','income','area_a',
'area_b','area_c','area_d']])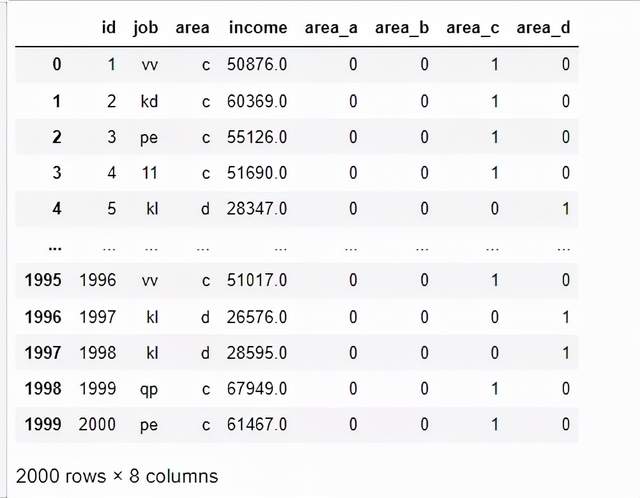
通常,您将删除原始列(“area”),因为它的目标是使神经网络的数据帧完全是数字的。
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 5)
df.drop('area', axis=1, inplace=True)
display(df[['id','job','income','area_a',
'area_b','area_c','area_d']])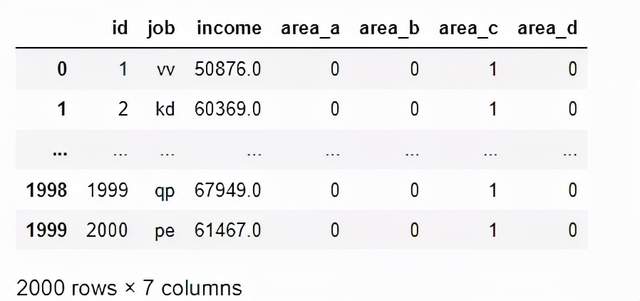
类别目标编码
Target Encoding for Categoricals
目标编码有时可以提高机器学习模型的预测能力。然而,它也极大地增加了过拟合的风险。由于这种风险,您必须小心使用这种方法。目标编码是Kaggle比赛中常用的一种技术。
一般情况下,目标编码只能在机器学习模型输出为数值(回归)时用于分类特征。
目标编码的概念很简单。对于每个类别,我们计算该类别的平均目标值。然后,为了进行编码,我们替换与类别值所包含类别对应的百分比。与虚拟变量不同的是,使用目标编码,每个类别都有一列,程序只需要一列。这样,目标编码比虚拟变量更有效
# Create a small sample dataset
import pandas as pd
import numpy as np
np.random.seed(43)
df = pd.DataFrame({
'cont_9': np.random.rand(10)*100,
'cat_0': ['dog'] * 5 + ['cat'] * 5,
'cat_1': ['wolf'] * 9 + ['tiger'] * 1,
'y': [1, 0, 1, 1, 1, 1, 0, 0, 0, 0]
})
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 0)
display(df)
与其为“dog”和“cat”创建虚拟变量,我们更愿意将其更改为一个数字。我们可以用0表示猫,1表示狗。然而,我们可以编码更多的信息。简单的0或1也只适用于一种动物。考虑猫和狗的平均目标值是多少。
means0 = df.groupby('cat_0')['y'].mean().to_dict()
means0输出
{'cat': 0.2, 'dog': 0.8}
危险在于我们现在使用目标值进行训练。这种技术可能会导致过度拟合。如果某一特定类别的数量很少,则过拟合的可能性更大。为了防止这种情况发生,我们使用了一个加权因子。权重越强,具有少量值的多个类别将趋向于y的总体平均值。
df['y'].mean()输出
0.5
您可以按照如下方式实现目标编码。有关目标编码的更多信息,请参阅文章“以正确的方式完成目标编码”,我正是基于这篇代码编写的。
def calc_smooth_mean(df1, df2, cat_name, target, weight):
# Compute the global mean
mean = df[target].mean()
# Compute the number of values and the mean of each group
agg = df.groupby(cat_name)[target].agg(['count', 'mean'])
counts = agg['count']
means = agg['mean']
# Compute the "smoothed" means
smooth = (counts * means + weight * mean) / (counts + weight)
# Replace each value by the according smoothed mean
if df2 is None:
return df1[cat_name].map(smooth)
else:
return df1[cat_name].map(smooth),df2[cat_name].map(smooth.to_dict())下面的代码对这两个类别进行编码。
WEIGHT = 5
df['cat_0_enc'] = calc_smooth_mean(df1=df, df2=None,
cat_name='cat_0', target='y', weight=WEIGHT)
df['cat_1_enc'] = calc_smooth_mean(df1=df, df2=None,
cat_name='cat_1', target='y', weight=WEIGHT)
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 0)
display(df)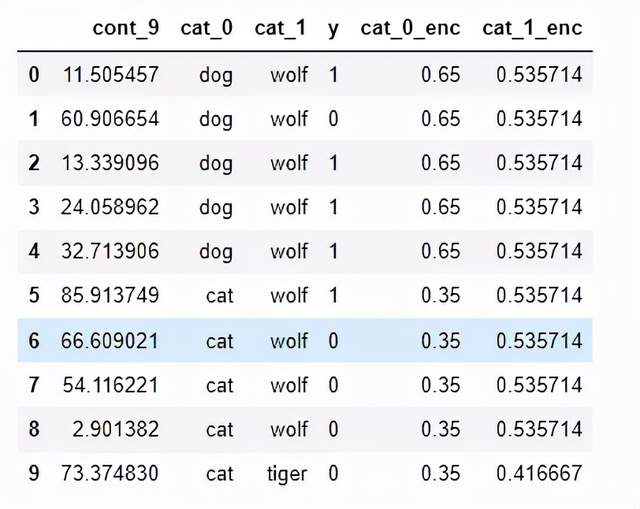
将分类值编码为序号
Encoding Categorical Values as Ordinal
典型的分类将被编码为虚拟变量。但是,可能还有其他技术可以将分类转换为数字。只要分类有顺序,就应该使用一个数字。考虑一下你是否有一个描述个人当前教育水平的分类。
幼儿园(0)
一年级(1)
二年级(2)
三年级(3)
四年级(4)
五年级(5)
六年级(6)
七年级(7)
八年级(8)
高中新生(9)
高中二年级(10)
初中(11)
高中(12)
大学新生(13)
大学二年级(14)
大学专科(15)
大学高级(16)
研究生(17)
博士生(18)
博士学位(19)
博士后(20)
上面的列表有21个等级。这需要21个虚拟变量。但是,简单地将其编码到项目中会丢失订单信息。也许最简单的方法是简单地为它们编号,并为类别分配一个与上面括号中的值相等的数字。然而,我们也许能做得更好。研究生可能超过一年,所以你可能增加不止一个值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









