







8.5 在线学习(Online learning)和随机优化(stochastic optimization)
传统机器学习都是线下的,也就意味着是有一批量的数据,然后优化一个下面形式的等式:
f ( θ ) = 1 N ∑ i = 1 N f ( θ , z i ) f(\theta)=\frac{1}{N}\sum^N_{i=1}f(\theta,z_i) f(θ)=N1∑i=1Nf(θ,zi)(8.74)
其中如果有 z i = ( x i , y i ) z_i=(x_i,y_i) zi=(xi,yi)是监督学习情况(supervised case),或者只有 x i x_i xi就对应着无监督学习的情况,而 f ( θ , z i ) f(\theta,z_i) f(θ,zi)这个函数是某种损失函数.比如可以使用下面这样的损失函数:
f ( θ , z i ) = L ( y i , h ( x i , θ ) ) f(\theta,z_i)=L(y_i,h(x_i,\theta)) f(θ,zi)=L(yi,h(xi,θ))(8.75)
其中的 h ( x i , θ ) h(x_i,\theta) h(xi,θ)是预测函数,而 L ( y , y ^ ) L(y,\hat y) L(y,y^)是某种其他的损失函数,比如可以使平方误差或者胡博损失函数(Huber loss).在频率论统计学方法中,平均损失函数也叫作风险(参考本书6.3),所以对应地就将这个方法整体叫做经验风险最小化(empirical risk minimization,缩写为ERM),参考本书6.5.
可是如果有一系列的流数据(streaming data)不停出现,就需要进行在线学习(online learning),也就是要随着每次有新数据来到而更新估计,而不是等到尽头,因为可能永无止境.另外有时候虽然数据是成批的一整个数据,也可能会因为太大没办法全部放进内存等原因也需要使用在线学习.接下来就要讲这类校本化的学习方法.
8.5.1 在线学习和遗憾最小化(regret minimization)
假如在每一步中,客观世界都提供了一个样本 z k z_k zk,而学习者必须使用一个参数估计 θ k \theta_k θk对此进行响应.在理论机器学习社区中,在线学习关注的目标是遗憾值(regret),定义为相对于使用单个固定参数值时候能得到的最好结果所得到的平均损失:
r e g r e t k = △ 1 k ∑ t = 1 k f ( θ t , z t ) − min θ ∗ ∈ Θ 1 k ∑ t = 1 k f ( θ ∗ , z t ) regret_k\overset{\triangle}{=} \frac{1}{k} \sum^k_{t=1} f(\theta_t,z_t)-\min_{\theta^*\in \Theta}\frac{1}{k} \sum^k_{t=1}f(\theta_*,z_t) regretk=△k1∑t=1kf(θt,zt)−minθ∗∈Θk1∑t=1kf(θ∗,zt)(8.77)
比如我们要调查股票市场.设 θ j \theta_j θj是我们在股票j上面投资的规模,而 z j z_j zj表示这个股票带来的回报.这样损失函数就是 f ( θ , z ) = − θ T z f(\theta,z)=-\theta^Tz f(θ,z)=−θTz.遗憾值(regret)就是我们通过每次交易而得到的效果,而不只是依据什么神秘预言来选择买那个股票然后购买和持有的策略.
在线学习的简单算法是在线梯度下降法(online gradient descent (Zinkevich 2003)),步骤如下:在每次第k步,使用下列表达式更新参数:
θ
k
+
1
=
p
r
o
j
Θ
(
θ
k
−
η
k
g
k
)
\theta_{k+1}=proj_{\Theta}(\theta_k-\eta_kg_k)
θk+1=projΘ(θk−ηkgk)(8.78)
其中的 p r o j v ( v ) = arg min w ∈ V ∣ ∣ w − v ∣ ∣ 2 proj_v(v)=\arg\min_{w\in V}||w-v||_2 projv(v)=argminw∈V∣∣w−v∣∣2是向量v在空间V上的投影, g k = ∇ f ( θ k , z k ) g_k=\nabla f(\theta_k ,z_k) gk=∇f(θk,zk)是梯度项,而 η k \eta_k ηk是补偿规模.(只有当参数必须要约束在某个 R D R^D RD的子集内的时候才需要使用投影这个步骤.更多细节参考本书13.4.3.)接下来要看看这个让遗憾最小化的方法和更传统的关注对象之间的关系,比如最大似然估计(MLE).
当然遗憾最小化也由很多其他方法,这就超出这本书的覆盖范围了,更多细节可以参考Cesa-Bianchi and Lugosi (2006).
8.5.2 随机优化和风险最小化
接下来我们要尝试的不是让过去步骤的遗憾最小化,而是希望未来损失最小化,这在很多(频率论)统计学习理论中更长久.也就是要最小化:
f ( θ = E [ f ( θ , z ) ] f(\theta=\mathrm{E}[f(\theta,z)] f(θ=E[f(θ,z)](8.79)
其中这个期望是对未来数据上取的.优化这种某些变量是随机变量的函数的过程就叫做随机优化(Stochastic optimization).
假如要从一个分不中得到一系列有限的抽样样本.一个方法就是优化8.79里面的期望值,在每一步应用等式8.78进行更新.这就叫做随机梯度下降法(stochastic gradient descent,缩写为SGD,出自Nemirovski and Yudin 1978).通常我们都想要一个简单的参数估计,可以用下面的进行平均:
θ ˉ k = 1 k ∑ t = 1 k θ t \bar\theta_k=\frac{1}{k}\sum^k_{t=1}\theta_t θˉk=k1∑t=1kθt(8.80)
这就叫Polyak-Ruppert 平均,可以递归使用,如下所示:
θ
ˉ
k
=
θ
ˉ
k
−
1
−
1
k
(
∇
θ
k
−
1
−
θ
k
)
\bar\theta_k=\bar\theta_{k-1}-\frac{1}{k}(\nabla \theta_{k-1}-\theta_k)
θˉk=θˉk−1−k1(∇θk−1−θk)(8.81)
更多细节参考(Spall 2003; Kushner and Yin 2003).
8.5.2.1 设定步长规模
接下来要讨论的是要保证随机梯度下降(SGD)收敛所需要的学习速率(learning rate)的充分条件(sufficient conditions).这也叫做Robbins-Monro条件:
∑ k = 1 ∞ η k = ∞ , ∑ k = 1 ∞ η k 2 = ∞ \sum^\infty_{k=1}\eta_k=\infty,\sum^\infty_{k=1}\eta^2_k=\infty ∑k=1∞ηk=∞,∑k=1∞ηk2=∞(8.82)
η
k
\eta_k
ηk在时间上的取值集合也叫作学习速率列表(learning rate schedule).可以用很多公式,比如
η
k
=
1
/
k
\eta_k=1/k
ηk=1/k,或者可以用下面这个(Bottou 1998; Bach and Moulines 2011):
η
k
=
(
τ
0
+
k
)
−
k
\eta_k=(\tau_0+k)^{-k}
ηk=(τ0+k)−k(8.83)
上面的 τ 0 ≥ 0 \tau_0 \ge 0 τ0≥0减慢了算法的早期迭代,而 k ∈ ( 0.5 , 1 ] k\in (0.5,1] k∈(0.5,1]控制了旧值被遗忘的速率.
随机优化的一个主要缺陷就是需要去调整这些个参数.一个简单的启发式办法(Bottou 2007)如下所示:存储数据的一个初始子集,然后对这个自己适用一系列不同的 η \eta η值;然后选择能使得目标对象降低最快的,再将其用于其他的全部数据上.要注意这可能会导致不收敛,不过当算法的性能提升达到某个设定好的位置(hold-out set plateaus)的时候可以终止(这也叫早期停止,early stopping)
8.5.2.2 分参数步长规模(Per-parameter step sizes)
随机梯度下降法(SGD)的一个问题就是对于不同的参数都用同样的补偿规模.接下来要简单介绍一种新方法,自适应梯度下降法(adaptive gradient),缩写为adagrad,出自(Duchi et al. 2010),这个方法的思路类似使用对角海森矩阵近似(diagonal Hessian approximation).(类似方法也可以参考Schaul et al. 2012).具体来说就是如果 θ i ( k ) \theta_i(k) θi(k)是第k次的参数i,而 g i ( k ) g_i(k) gi(k)是对应的梯度,就可以用下面的方式进行更新:
θ i ( k + 1 ) = θ i ( k ) − η g i ( k ) τ o + s i ( k ) \theta_i(k+1)=\theta_i(k)-\eta\frac{g_i(k)}{\tau_o+\sqrt{s_i(k)}} θi(k+1)=θi(k)−ητo+si(k)gi(k)(8.84)
其中对角步长规模向量(diagonal step size vector)是梯度向量的平方(gradient vector squared),加上整个时间上的所有补偿.这也可以使用下面的形式来递归更新:
s i ( k ) = s i ( k − 1 ) + g i ( k ) 2 s_i(k)=s_i(k-1)+g_i(k)^2 si(k)=si(k−1)+gi(k)2(8.85)
这个结果就是一个分参数步长规模,可以适应损失函数的曲率(curvature).这个方法最开始推导出来是为了遗憾最小化的情形,不过还可以有很多其他用途.
8.5.2.3 随机梯度下降(SGD)和批量学习(batch learning)的对比
如果没有一个无限的数据流,可以去模拟一个,只要随机从训练集中取样数据点就可以了.本质上是将等式8.74作为对经验分布的期望来优化。
算法8.3 随机梯度下降法
- 初始化 θ , η \theta,\eta θ,η;
- 重复下面步骤直至收敛:
- 随机交流数据(permute data)
- for i = 1 : N i=1:N i=1:N 重复下面操作:
- g = ∇ f ( θ , z i ) g=\nabla f(\theta,z_i) g=∇f(θ,zi)
- θ ← p r o j Θ ( θ − η g ) \theta \leftarrow proj_\Theta (\theta-\eta g) θ←projΘ(θ−ηg)
- 更新 η \eta η
理论上应该有替代取样,不过实际上通常都是无替代随机交流数据和样本效果更好,然后后面都重复这样操作.每次对全部数据集进行一次抽样就叫做一代(epoch).伪代码参考本书算法8.
在线下学习的情况下,更好的方法是以B份数据来进行小批量(mini-batch)梯度计算.如果B=1,这就是标准的随机梯度下降发,如果B=N,这就成了标准的最陡下降(Steepest descent).一般都设置 B ∼ 100 B\sim 100 B∼100.
虽然随机梯度下降法(SGD)是很简单的一阶方法(first-order method),但用于一些问题的时候效果出奇地好,尤其是数据规模很大的情况(Bottou 2007).直观理解起来,原因可能是只要看过几个样本之后就能对梯度进行很好的估计了.而使用很大规模的数据来仔细计算精准的梯度就很可能是浪费时间了,因为算法反正也要在下一步重新计算梯度.为了充分利用计算时间,最好是使用一个有噪音的估计,然后沿着参数空间快速移动.一个极端的例子,比如要对每个样本都重复一份来复制整个训练样本集.这样批量方法就要花费两倍时间,而在线学习方法就几乎不会被影响,因为梯度方向其实没有变化(双倍数据规模知识改变了梯度烈度(magnitude),但并不相关,因为梯度反正也要被步长规模所缩放).
除了能加速之外,随机梯度下降法(SGD)还不太容易在浅局部最小值部位卡住,因为通常增加了一定规模的噪音.因此这种方法在机器学习社区中很流行于拟合有非凸函数对象的模型,比如神经网络(neural networks,本书16.5)和深层信念网络(deep belief networks本书28.1)等等.
8.5.3 最小均方算法(LMS algorithm)
举个随机梯度下降法(SGD)的例子,假设要考虑去计算在线学习中线性回归的最大似然估计(MLE).在等式7.14中已经推导出了批量梯度(batch gradient).在第k次迭代的在线梯度为:
g k = x i ( θ k T x i − y i ) g_k =x_i(\theta^T_kx_i-y_i) gk=xi(θkTxi−yi)(8.86)
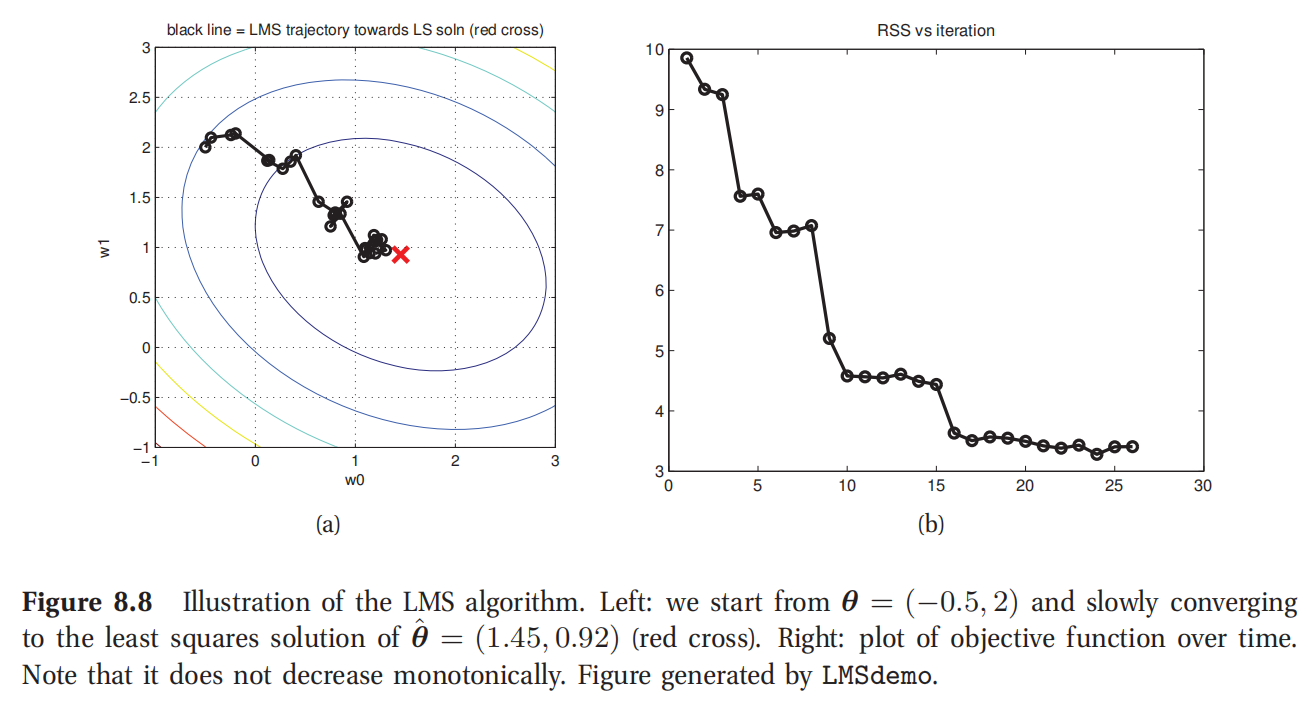
此处查看原书图8.8
其中的 i = i ( k ) i=i(k) i=i(k)是第k次迭代时候使用的训练样本.如果数据集是流式的,就用 i ( k ) = k i(k)=k i(k)=k;为了表达简单,以后就这么用了.等式8.86很好理解:特征向量 x k x_k xk乘以预测 y ^ k = θ k T x k \hat y_k =\theta^T_k x_k y^k=θkTxk和真实的响应变量 y k y_k yk的差距作为权重.;因此梯度函数就像可以当做是一个误差信号了.
在计算了梯度之后,可以沿着梯度进行下一步长,如下所示:
θ
k
+
1
=
θ
k
−
η
k
(
y
^
k
−
y
k
)
x
k
\theta_{k+1}=\theta_k-\eta_k(\hat y_k-y_k)x_k
θk+1=θk−ηk(y^k−yk)xk(8.87)
(这里就没必要进行投影的步骤了,因为这是一个非约束的优化问题,unconstrained optimization problem.)这个算法也叫作最小均方算法(least mean squares,缩写为LMS),也被称作 δ \delta δ规则(delta rule),或者也叫做Widrow-Hoff 规则(Widrow-Hoff rule).
图8.8所示就是对图7.2当中的数据应用这个算法的结果.启动点为 θ = ( − 0.5 , 2 ) \theta=(-0.5,2) θ=(−0.5,2),经过大约26次迭代而收敛(这里的收敛指的是 ∣ ∣ θ k − θ k − 1 ∣ ∣ 2 2 ||\theta_k-\theta_{k-1}||^2_2 ∣∣θk−θk−1∣∣22小于阈值 1 0 − 2 10^{-2} 10−2).
要注意最小均方算法(LMS)可能需要很多次遍历整个数据才能找到最优解.对比之下,使用递归最小均方算法,基于卡尔曼过滤器(Kalman filter)使用二阶信息(second-order information),只要单次遍历数据就能找到最优解了(参考本书18.2.3).也可以参考练习7.7.
8.5.4 感知器算法(perceptron algorithm)
接下来考虑如何对在线情况下的二值化逻辑回归模型(binary logistic regression model)进行拟合.批量梯度(batch gradient)如等式8.5所示.在线情况下呢,加权重的更新的形式简单如下:
θ
k
=
θ
k
−
1
−
η
k
g
i
=
θ
k
−
1
−
η
k
(
μ
i
−
y
i
)
x
i
\theta_k=\theta_{k-1}-\eta_kg_i =\theta_{k-1} -\eta_k(\mu_i-y_i)x_i
θk=θk−1−ηkgi=θk−1−ηk(μi−yi)xi(8.88)
其中 μ i = p ( y i = 1 ∣ x i , θ k ) = E [ y i ∣ x i , θ k ] \mu_i=p(y_i=1|x_i,\theta_k)=\mathrm{E}[y_i|x_i,\theta_k] μi=p(yi=1∣xi,θk)=E[yi∣xi,θk].可见这和最小均方算法(LMS)形式一模一样.实际上这个性质对于多有的通用线性模型都成立(参考本书9.3).
然后对这个算法进行近似.设:
y
^
i
=
arg
max
y
∈
{
0
,
1
}
p
(
y
∣
x
i
,
θ
)
\hat y_i =\arg\max_{y\in\{0,1\}} p(y|x_i,\theta)
y^i=argmaxy∈{0,1}p(y∣xi,θ)(8.89)
代表了最大概率类标签.然后替代 μ i = p ( y = 1 ∣ x i , θ ) = s i g m ( θ T x i ) \mu_i =p(y=1|x_i,\theta)=sigm(\theta^Tx_i) μi=p(y=1∣xi,θ)=sigm(θTxi)中的剃度表达式为 y ^ i \hat y_i y^i.这样就得到了近似的梯度:
g i ≈ ( y ^ i − y i ) x i g_i\approx (\hat y_i -y_i)x_i gi≈(y^i−yi)xi(8.90)
如果我们假设
y
∈
{
−
1
,
+
1
}
y\in \{-1,+1\}
y∈{−1,+1},而不是
y
∈
{
0
,
1
}
y\in \{0,1\}
y∈{0,1},那么在代数计算上就能更简单了.这时候我们的预测就成了:
y
^
i
=
s
i
g
n
(
θ
T
x
i
)
\hat y_i =sign(\theta^Tx_i)
y^i=sign(θTxi)(8.91)
然后如果 y ^ i y i = − 1 \hat y_i y_i =-1 y^iyi=−1,就分类错误了,而如果 y ^ i y i = + 1 \hat y_i y_i =+1 y^iyi=+1则表示猜对了分类标签.
在每一步,都要通过加上梯度来更新权重向量.关键的观察项目在于,如果预测正确,那么 y ^ i = y i \hat y_i=y_i y^i=yi,所以(近似)梯度就是零了,也就不用去更改权重向量了.可是如果 x i x_i xi是误分类的(misclassified),就要按照下面的步骤更新权重向量了:如果 y ^ i = 1 \hat y_i =1 y^i=1而 y i = − 1 y_i = -1 yi=−1,那么负梯度就是 − ( y ^ i − y i ) x i = − 2 x i -(\hat y_i-y_i)x_i=-2x_i −(y^i−yi)xi=−2xi;如果反过来 y ^ i = − 1 \hat y_i =-1 y^i=−1而 y i = 1 y_i = 1 yi=1,那么负梯度就是 − ( y ^ i − y i ) x i = 2 x i -(\hat y_i-y_i)x_i= 2x_i −(y^i−yi)xi=2xi.上面这个因数2可以吸收进学习速率(learning rate) η \eta η里面,之写成更新的形式,在误分类的情况下为:
θ k = θ k − 1 + η k y i x i \theta_k =\theta_{k-1}+\eta_k y_i x_i θk=θk−1+ηkyixi(8.92)
由于只有权重的符号是重要的,而大小并不重要,所以就可以设
η
k
=
1
\eta_k=1
ηk=1.伪代码参考本书的算法11.
上面这个算法也就叫做感知器算法(perceptron algorithm),出自(Rosenblatt 1958),在给的数据是线性可分(linearly separable)的情况下就会收敛,即存在参数
θ
\theta
θ使得在训练集上的预测
s
i
g
n
(
θ
T
x
)
sign(\theta^Tx)
sign(θTx)会达到零误差(0 error).不过如果暑假不是线性可分的,这个算法就不收敛了,甚至可能虽然收敛也要花费很长时间才行.训练逻辑回归模型有很多更好的方法,比如使用适当的随机梯度下降(SGD)而不使用梯度近似,或者迭代重加权最小二乘法(IRLS,参考本书8.3.4).不过感知器算法还是有很重要历史地位的:这可以算是有史以来被推导出的第一个机器学习算法(Frank Rosenblatt 1957),甚至还被用模拟硬件进行了实现.另外,这个算法也可以用于计算边缘分布
p
(
y
i
∣
x
,
θ
)
p(y_i|x, \theta)
p(yi∣x,θ)比计算最大后验分布输出(MAP output)
arg
max
y
p
(
y
∣
x
,
θ
)
\arg\max _y p(y|x,\theta)
argmaxyp(y∣x,θ)在运算上更昂贵的模型拟合;这还引出了一些结构输出(structured-output)分类问题.具体细节参考本书19.7.
算法8.4 感知器算法
- 输入:线性可分数据集 x i ∈ R D , y i ∈ { − 1. + 1 } , f o r i = 1 : N x_i \in R^D,y_i \in \{ -1.+1\}, for i =1:N xi∈RD,yi∈{−1.+1},fori=1:N
- 初始化 θ 0 \theta_0 θ0;
- k ← 0 k\leftarrow 0 k←0
- 重复下面步骤直至收敛:
- k ← k + 1 k\leftarrow k+1 k←k+1
- i ← k m o d N i \leftarrow k mod N i←kmodN
- 如果 y ^ i ≠ y i \hat y_i\ne y_i y^i=yi:
- θ k + 1 ← θ k + y i x i \theta_{k+1}\leftarrow \theta_k+y_ix_i θk+1←θk+yixi
- 否则:
- 无操作
8.5.5 贝叶斯视角
在线学习的另外一个方法就是从贝叶斯视角实现的.这个概念特别简单:就是递归应用贝叶斯规则:
p
(
θ
∣
D
1
:
k
)
∝
p
(
D
k
∣
θ
)
p
(
θ
∣
d
1
:
k
−
1
)
p(\theta|D_{1:k})\propto p(D_k|\theta)p(\theta|d_{1:k-1})
p(θ∣D1:k)∝p(Dk∣θ)p(θ∣d1:k−1)(8.93)
这有个很明显的优势,因为返回的是一个后验,而不是一个点估计.这也允许超参数(hyper-parameters)的在线自适应(online adaptation),这是非常重要的,因为在线学习没办法使用交叉验证.最后的一个不那么明显的优点就是速度可以比随机梯度下降法(SGD)更快.具体原因在于,通过对每个参数加上其均值的后验方差建模,可以有效对每个参数赋予不同的学习速率(de Freitas et al. 2000),这是对空间曲率(curvature)建模的一种简单方法.这些房差通过概率论的常见规则就可以实现自适应(adapted).对比之下,使用二阶(second-order)优化方法来解决在线学习的问题可能就要麻烦多了(更多细节参考Schraudolph et al.2007; Sunehag et al. 2009; Bordes et al. 2009, 2010).
本书18.2.3是一个简单的样例,展示了如何使用卡尔曼过滤器(Kalman filter)来在线拟合一个线性回归模型.和最小均方算法(LMS)不同,这个方法遍历数据一次就可以收敛到最优解(离线).Ting et al.2010 讲了一种扩展方法,以在线的形式来学习一个健壮的非线性回归模型(robust non-linear regression model).对于通用线性模型(GLM)的情况,可以使用一个假设密度过滤器(assumed density filter,参考本书18.5.3),其中使用一个对角协方差的高斯分布来对后验近似;方差项目就可以用作分参数步长规模(per-parameter step-size).更多细节参考本书18.5.3.2.另外一种方法是使用粒子过滤器(particle filtering,本书23.5),这个方法被(Andrieu et al. 2000)用于核化的(kernelized)线性/逻辑回归模型的序列学习(sequentially learning).
8.6 生成分类器和判别分类器(Generative vs discriminative classifiers)
在本书4.2.2,已经降到了类标签的后验分布使用高斯判别分析(Gaussian discriminative analysis,缩写为GDA)之后形式和逻辑回归一模一样,都是 p ( y = 1 ∣ x ) = s i g m ( w T x ) p(y=1|x)=sigm(w^Tx) p(y=1∣x)=sigm(wTx).因此这个决策边界在两种情况下都是x的线性函数.不过要注意很多生成模型可能会给出一个逻辑回归后验,比如,每个类条件密度都是泊松分布(Poisson) p ( x ∣ y = c ) = P o i ( x ∣ λ c ) p(x|y=c)=Poi(x|\lambda _c) p(x∣y=c)=Poi(x∣λc).所以使用GDA所做的假设要比使用逻辑回归的假设更强.
这些模型更进一步的区别就是训练方式.当你和一个判别模型的时候,一般是最大化条件对数似然函数 ∑ i = 1 N log p ( y i ∣ x i , θ ) \sum^N_{i=1}\log p(y_i|x_i,\theta) ∑i=1Nlogp(yi∣xi,θ),而当拟合一个生成模型的时候,通常要最大化联合对数似然函数 ∑ i = 1 N log p ( y i , x i ∣ θ ) \sum^N_{i=1}\log p(y_i,x_i|\theta) ∑i=1Nlogp(yi,xi∣θ).很明显,这就能导致不同结果(参考练习4.20).
当使用GDA做出的高斯假设正确无误的时候,生成模型需要的训练样本数据集要比逻辑回归更少,就能达到确定水平的性能,可是如果高斯假设不正确,逻辑回归效果就更好了(Ng and Jordan 2002).这是因为判别模型不需要对特征分布进行建模.这也如图8.10所示.可见其中类条件密度还是相当复杂的;具体来说就是 p ( x ∣ y = 1 ) p(x|y=1) p(x∣y=1)是一个多项分布,就可能很难估计.不过类后验 p ( y = c ∣ x ) p(y=c|x) p(y=c∣x)是一个简单的s形函数,中间部位就是阈值0.55.这就说明一般来说判别模型可能更精准,因为他们的工作某种程度上来说更简单.不过精确度并不是我们挑选方法时候的唯一重要因素.接下来就要说一下两种方法的优点和不足.
8.6.1 不同方法的各自优劣
- 容易拟合?我们已经看到了,拟合生成分类器通常都很简单.比如本书3.5.1.1和4.2.4,分别对朴素贝叶斯模型和线性判别分析模型(LDA)进行了拟合,只需要简单的计数和取平均.相比之下,逻辑回归就需要解一个凸优化问题了(具体细节比如本书8.3.4),这就要慢多了.
- 分开拟合各类?在生成分类器中,我们队每个类条件密度分开估计其参数,所以不需要再增加更多类的时候重新训练模型.对比之下在判别模型中,所有参数都参与互动,所以添加新类的时候必须要重新训练.(如果我们训练一个生成模型来最大化一个判别对象也是这样的情况,参考Salojarvi et al. 2005.)
- 处理缺失数据更容易?有时候一些输入(x的成分)可能并没有观察到.也就是缺失了.在生成分类器里面,有一种简单方法来应对这种情况,稍后本书8.6.2就会讲到.不过在判别分类器里面,原则上这种问题就无解了,因为模型假设x是永远可用的要能用来做条件的(当然其实也有一些启发式方法来应对,参考Marlin 2008).
- 能处理无标签训练数据?半监督学习(semi-supervised learning)是很有意思的,其中使用了一些未标签数据来解决一个监督任务.这对于生成模型来说很容易(参考(Lasserre et al. 2006; Liang et al. 2007)),但对于判别模型就难多了.
- 输入输出是否对称?对于生成模型,可以反着用,然后通过给定的输出来推测可能的输入,只要计算 p ( x ∣ y ) p(x|y) p(x∣y)就可以了.这对于判别模型来说就是不可能了.因为生成模型定义了一个在x和y上的联合分布,因此输入输出就是对称的.
- 能否特征预处理?判别方法的一个大优势就是允许我们事先以任何方式来对数据进行预处理,比如可以把x替换成 ϕ ( x ) \phi(x) ϕ(x),可以是某种基函数扩展,比如图8.9所示.不过要是相对这种预处理数据定义生成模型就可能很难了,因为新的特征就会以复杂方式相互关联.
- 能否有校正良好的概率?有点生成模型,比如朴素贝叶斯,有很强的独立假设,而这些假设很可能是无效的.这就可能导致非常极端的后验类概率,比如很靠近0或者1.判别模型比如逻辑回归等等,就通常在概率估计上有更好的校正.
上面就是对于两种模型的比较对比.这两种模型最好都掌握一些,放进你的工具箱.表格8.1所示是本书讲的分类和回归技术的总结.
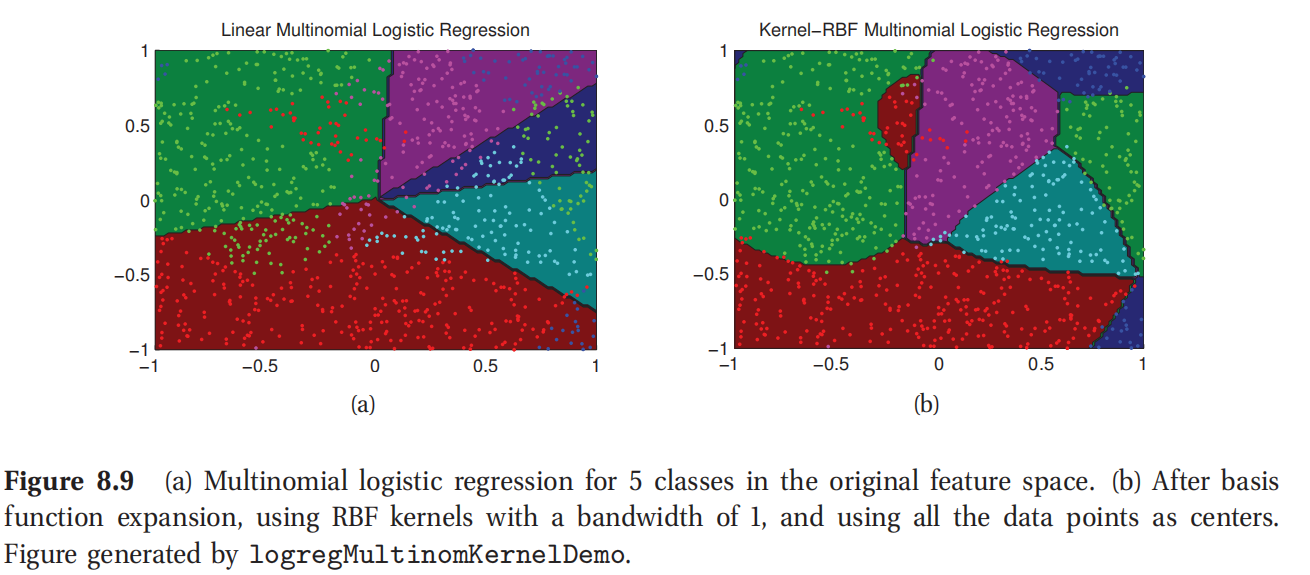
此处参考原书图8.9
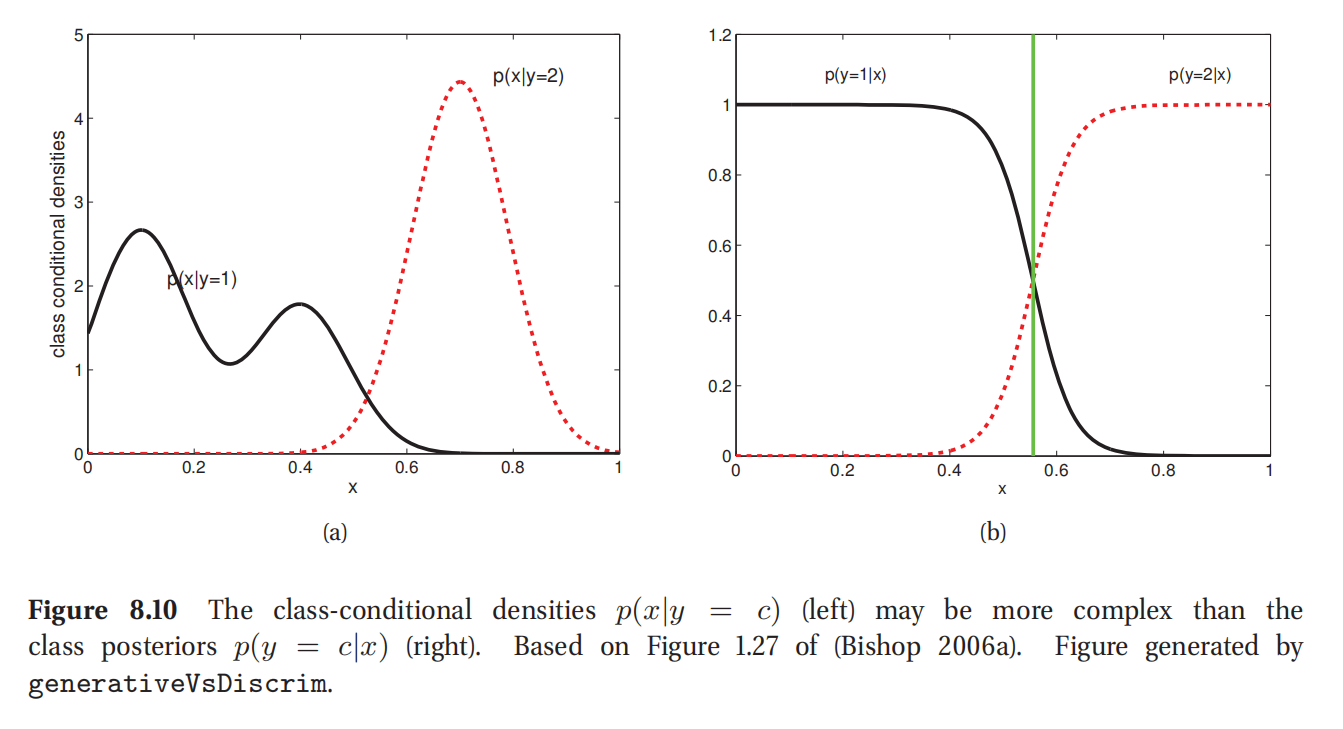 此处参考原书图8.10
此处参考原书图8.10
| 模型名称 | 分类/回归 | 生成/判别 | 参数化/非参数化 | 章节 |
|---|---|---|---|---|
| 判别分析 Discriminant analysis | 分类 | 生成 | 参数化 | 4.2.2,4.2.4 |
| 朴素贝叶斯分类器Naive Bayes classifier | 分类 | 生成 | 参数化 | 3.5,3.5.1.2 |
| 树增广朴素贝叶斯分类器Tree-augmented Naive Bayes classifier | 分类 | 生成 | 参数 | 10.2.1 |
| 线性回归 Linear regression | 回归 | 判别 | 参数化 | 1.4.5,7.3,7.6 |
| 逻辑回归 Logistic regression | 分类 | 判别 | 参数化 | 1.4.6,8.3.4,8.4.3,21.8.1.1 |
| 稀疏线性/逻辑回归 Sparse linear/ logistic regression | 结合 | 判别 | 参数化 | 13 |
| 专家混合 Mixture of experts | 结合 | 判别 | 参数化 | 11.2.4 |
| 多层感知器/神经网络 Multilayer perceptron (MLP)/ Neural network | 结合 | 判别 | 参数化 | 16 |
| 条件随机域 Conditional random field (CRF) | 分类 | 判别 | 参数化 | 19.6 |
| K最近邻分类器 K nearest neighbor classifier | 分类 | 生成 | 非参数化 | 1.4.2,14.7.3 |
| 无穷混合判别分析 (Infinite) Mixture Discriminant analysis | 分类 | 生成 | 非参数化 | 14.7.3 |
| 分类和回归树 Classification and regression trees (CART) | 结合 | 判别 | 非参数化 | 16.2 |
| 增强模型 Boosted model | 结合 | 判别 | 非参数化 | 16.4 |
| 稀疏核化线性/逻辑回归 Sparse kernelized lin/logreg (SKLR) | 结合 | 判别 | 非参数化 | 14.3.2 |
| 相关向量机 Relevance vector machine (RVM) | 结合 | 判别 | 非参数化 | 14.3.2 |
| 支持向量机 Support vector machine (SVM) | 结合 | 判别 | 非参数化 | 14.5 |
| 高斯过程 Gaussian processes (GP) | 结合 | 判别 | 非参数化 | 15 |
| 平滑样条 Smoothing splines | 回归 | 判别 | 非参数化 | 15.4.6 |
| 表 8.1 本书所讲到的分类/回归模型的列表.此表格也可以从[这个链接](http://pmtk3.googlecode.com/svn/trunk/docs/tutorial/html/tu | ||||
| tSupervised.html)查看对应的PMTK代码.任何的生成概率模型(比如隐形马尔科夫链HMM,玻尔兹曼机器Boltzmann machines,贝叶斯网络 Bayesian networks等等)都可以转化成用作类条件密度(class | ||||
| conditional density)的分类器. |
8.6.2 处理缺失数据
有时候输入值(x的成分)可能没观测到;这可能是创安器故障导致的,也可能是记录时候没弄完整等等.这就叫做数据缺失问题 (missing data problem,Little. and Rubin 1987).对于生成模型来说,能在原则上有办法处理这种缺失数据是最大的优势了.
规范化表达一下,使用一个二值化响应变量 r i ∈ { 0 , 1 } r_i\in \{0,1\} ri∈{0,1},用来判断 x i x_i xi是否被观测到.联合模型形式就是 p ( x i , r i ∣ θ , ϕ ) = p ( r i ∣ x i , ϕ ) p ( x i ∣ θ ) p(x_i,r_i|\theta,\phi)=p(r_i|x_i,\phi)p(x_i|\theta) p(xi,ri∣θ,ϕ)=p(ri∣xi,ϕ)p(xi∣θ),其中的 ϕ \phi ϕ是控制该项目是否被检测到的参数.如果假设 p ( r i ∣ x i , ϕ ) = p ( r i ∣ ϕ ) p(r_i|x_i,\phi)=p(r_i|\phi) p(ri∣xi,ϕ)=p(ri∣ϕ),就说数据是随机缺失的(missing completely at random,缩写为MCAR).如果这这两个假设都不成立,就说数据是非随机缺失(not missing completely at random,缩写为NMCAR).这种情况下,就必须对数据缺失机制进行建模了,因为确实的模式中包含了关于缺失数据和对应参数的信息.这在协作过滤(most collaborative filtering)问题中最常见.更多内容参考(Marlin 2008).接下来先假设数据是随机丢失的.
处理缺失数据的时候,最好要区分出来数据缺失发生在测试的时候(而训练数据是完整的)还是发生在训练的时候,训练时候有缺失就更麻烦一些.接下来会分别讨论两种情况.要注意在测试的时候分类标签总是缺失的,这就是测试的定义决定的;如果在训练的时候分类标签有时候也缺失,这样问题就是半监督学习(semi-supervised learning)了.
8.6.2.1 测试时候的数据丢失
在生成分类其中,随机缺失数据的特征可以通过边缘化而去掉(marginalizing them out).例如,如果缺失 x 1 x_1 x1的值,可以计算:
p ( y = c ∣ x 2 : D , θ ) ∝ p ( y = c ∣ θ ) p ( x 2 : D ∣ y = c , θ ) (8.94) = p ( y = c ∣ θ ) ∑ x 1 p ( x 1 , x 2 : D ∣ y = c , θ ) (8.95) \begin{aligned} p(y=c|x_{2:D},\theta)&\propto p(y=c |\theta)p(x_{2:D}|y=c,\theta) &\text{(8.94)}\\ &= p(y=c|\theta)\sum_{x_1}p(x_1,x_{2:D}|y=c,\theta) &\text{(8.95)}\\ \end{aligned} p(y=c∣x2:D,θ)∝p(y=c∣θ)p(x2:D∣y=c,θ)=p(y=c∣θ)x1∑p(x1,x2:D∣y=c,θ)(8.94)(8.95)
如果使用朴素贝叶斯加设,这个边缘化(maginalization)过程可以如下进行:
∑
x
1
p
(
x
1
,
x
2
:
D
∣
y
=
c
,
θ
)
=
[
∑
x
1
p
(
x
1
∣
θ
1
c
)
]
∏
j
=
2
D
p
(
x
j
∣
θ
j
c
)
=
∏
j
=
2
D
p
(
x
j
∣
θ
j
c
)
\sum_{x_1}p(x_1,x_{2:D}|y=c,\theta)=[\sum_{x_1}p(x_1|\theta_{1c})]\prod^D_{j=2}p(x_j|\theta_{jc})=\prod^D_{j=2}p(x_j|\theta_{jc})
∑x1p(x1,x2:D∣y=c,θ)=[∑x1p(x1∣θ1c)]∏j=2Dp(xj∣θjc)=∏j=2Dp(xj∣θjc)(8.96)
其中利用了 ∑ x 1 p ( x 1 ∣ y = c , θ ) = 1 \sum_{x_1} p(x_1|y=c,\theta)=1 ∑x1p(x1∣y=c,θ)=1.因此在一个朴素贝叶斯分类器里面,只要在测试的时候忽略掉确实特征就可以了.类似的在判别分析里面,不论估计参数的时候使用了什么样的规范化方法(regularization method),都可以解析地将确实变量边缘化来去掉(参考本书4.3):
p ( x 2 : D ∣ y = c , θ ) = N ( x 2 : D ∣ μ c , 2 : D , Σ c , 2 : d , 2 : D ) p(x_{2:D}|y=c,\theta)=N(x_{2:D}|\mu_{c,2:D},\Sigma_{c,2:d,2:D}) p(x2:D∣y=c,θ)=N(x2:D∣μc,2:D,Σc,2:d,2:D)(8.97)
8.6.2.2 训练时候的数据丢失
训练时候数据丢失就不那么好处理了.尤其是这时候计算最大似然估计(MLE)或者最大后验分布(MAP)就都不再是简单的优化问题了,具体原因在本书11.3.2中会讲到.不过也不要紧,因为很快就会学到很多更复杂的算法(比如本书11.4要讲的期望最大化算法(EM))来对这种情况下的最大似然估计(MLE)和最大后验分布(MAP)进行近似.
8.6.3 费舍尔线性判别分析(FLDA)*
判别分析(Discriminant analysis)是用来分类的一种生成方法(generative approach),需要对特征拟合一个多元正态分布(MVN).这在高维度的情况下可能就很困难.所以有一种办法就是降低特征 x ∈ R D x\in R^D x∈RD的维度,然后对得到的低维度特征 z ∈ R L z\in R^L z∈RL来拟合多元正态分布(MVN).最简单的方法就是使用线性投影矩阵 z = W x z=Wx z=Wx,这里的W就是一个 L × D L\times D L×D的矩阵.可以使用主成分分析(PCA)来找到矩阵W(参考本书12.2);得到的结果和正则化线性判别分析(RDA,参考本书4.2.6)类似,因为奇异值分解(SVD)和主成分分析(PCA)是本质上等价的.不过主成分分析(PCA)是无监督技术,不需要考虑类标签.所以得到的低维度特征就并不见得一定是对于分类来说的最优选择,如图8.11所示.度还有一种方法,就是找使用高斯类条件密度模型来尽可能降低维度数据分类最优的矩阵W.这里使用高斯分布是合理的,因为我们计算的是一系列特征的线性组合,虽然这些特征可能不见的是高斯分布的.这种方法就叫做费舍尔线性判别分析(Fisher’s linear discriminant analysis,缩写为FLDA).
此处参考原书图8.11
费舍尔线性判别分析(FLDA)是对判别方法和生成方法的一种混合.这个方法的缺点就是限制在使用的 L ≤ C − 1 L\le C-1 L≤C−1小于类标签数目减一的维度,而不论D的维度是多少,具体原因后面会解释.这样在二分类情况下,就意味着要找一个单独向量w来对数据进行投影.下面就推到一些二分类情况优化w的过程.然后再泛化到多分类的情况下,最终对这个方法给一个概率论的解释.
8.6.3.1 一维最优投影的推导
接下来要对二分类情况下的最优方向w进行推导,这部分参考了(Bishop 2006b, Sec 4.1.4).定义类条件均值(class-conditional means)为:
μ 1 = 1 N 1 ∑ i : y i = 1 x i , μ 2 = 1 N 2 ∑ i : y i = 2 x i \mu_1=\frac{1}{N_1}\sum_{i:y_i =1} x_i,\mu_2=\frac{1}{N_2}\sum_{i:y_i =2} x_i μ1=N11∑i:yi=1xi,μ2=N21∑i:yi=2xi(8.98)
设
m
k
=
w
T
μ
k
m_k=w^T\mu_k
mk=wTμk为每个均值在线w上的投影.另外设
z
i
=
w
T
x
i
z_i=w^Tx_i
zi=wTxi为数据在线上的投影.这样投影点的方差就正比于(proportional to):
s
k
2
=
∑
i
:
y
i
=
k
(
z
i
−
m
k
)
2
s_k^2 = \sum_{i:y_i =k} (z_i-m_k)^2
sk2=∑i:yi=k(zi−mk)2(8.99)
咱们的目标就是找出能让均值距离 m 2 − m 1 m_2-m_1 m2−m1最大的w,同时也要保证投影的簇(cluster)是紧密的(tight):
J ( w ) = ( m 2 − M 1 ) 2 J(w)=\frac{(m_2-M_1)^2}{} J(w)=(m2−M1)2(8.100)
将等好友吧改写成关于w的形式如下所示:
J ( w ) = w T S B w w T S W w J(w)=\frac{w^TS_Bw}{w^TS_Ww} J(w)=wTSWwwTSBw(8.101)
其中的 S B S_B SB为类间散布矩阵(between-class scatter matrix):
S B = ( μ 2 − μ 1 ) ( μ 2 − μ 1 ) T S_B=(\mu_2-\mu_1)(\mu_2-\mu_1)^T SB=(μ2−μ1)(μ2−μ1)T(8.102)
S
W
S_W
SW为类内散布矩阵(within-class scatter matrix):
$S_W = \sum_{i:y_i=1} wT(x_i-\mu_1)(x_i-\mu_1)T + \sum_{i:y_i=2} wT(x_i-\mu_2)(x_i-\mu_2)T $(8.103)
然后两边分别乘以 w T w^T wT和 w w w:
w T S B w = w T ( μ 2 − μ 1 ) ( μ 2 − μ 1 ) T w = ( m 2 − m 1 ) ( m 2 − m 1 ) T w^TS_Bw=w^T(\mu_2-\mu_1)(\mu_2-\mu_1)^T w=(m_2-m_1)(m_2-m_1)^T wTSBw=wT(μ2−μ1)(μ2−μ1)Tw=(m2−m1)(m2−m1)T(8.104)
w T S W w = ∑ i : y i = 1 w T ( x i − μ 1 ) ( x i − μ 1 ) T w + ∑ i : y i = 2 w T ( x i − μ 2 ) ( x i − μ 2 ) T w (8.105) = ∑ i : y i = 1 ( z i − m 1 ) 2 + ∑ i : y i = 2 ( z i − m 2 ) 2 (8.106) \begin{aligned} w^TS_Ww &=\sum_{i:y_i=1} w^T(x_i-\mu_1)(x_i-\mu_1)^T w+ \sum_{i:y_i=2} w^T(x_i-\mu_2)(x_i-\mu_2)^T w &\text{(8.105)}\\ &= \sum_{i:y_i=1}(z_i-m_1)^2+\sum_{i:y_i=2}(z_i-m_2)^2 &\text{(8.106)}\\ \end{aligned} wTSWw=i:yi=1∑wT(xi−μ1)(xi−μ1)Tw+i:yi=2∑wT(xi−μ2)(xi−μ2)Tw=i:yi=1∑(zi−m1)2+i:yi=2∑(zi−m2)2(8.105)(8.106)
等式8.101就是两个标量的比;可以关于我求导数然后就等于零了.很明显(参考练习12.6) J ( w ) J(w) J(w)最大化的时候为:
S B w = λ S W w S_Bw=\lambda S_Ww SBw=λSWw(8.107)
其中的:
λ
=
w
T
S
B
w
w
T
S
W
w
\lambda =\frac{w^TS_Bw}{w^TS_Ww}
λ=wTSWwwTSBw(8.108)
等式107也叫广义特征值问题(generalized eigenvalue problem).如果
S
W
S_W
SW可逆,就可以转换成一个规范特征值问题:
S
W
−
1
S
B
w
=
λ
w
S_W^{-1}S_Bw =\lambda w
SW−1SBw=λw(8.109)
不过在二分类情况下,就有一个更简单的解了.由于
S B w = ( μ 2 − μ 1 ) ( μ 2 − μ 1 ) T w = ( μ 2 − μ 1 ) ( m 2 − m 1 ) S_Bw = (\mu_2-\mu_1)(\mu_2-\mu_1)^T w =(\mu_2-\mu_1)(m_2-m_1) SBw=(μ2−μ1)(μ2−μ1)Tw=(μ2−μ1)(m2−m1)(8.110)
所以通过等式8.109就有
λ
w
=
S
W
−
1
(
μ
2
−
μ
1
)
(
m
2
−
m
1
)
(8.111)
w
∝
S
W
−
1
(
μ
2
−
μ
1
)
(8.112)
\begin{aligned} \lambda w& = S_W^{-1}(\mu_2-\mu_1)(m_2-m_1) &\text{(8.111)}\\ w & \propto S_W^{-1}(\mu_2-\mu_1) &\text{(8.112)}\\ \end{aligned}
λww=SW−1(μ2−μ1)(m2−m1)∝SW−1(μ2−μ1)(8.111)(8.112)
由于我们只关心方向,缩放因数就无所谓了,所以可以直接写成:
w = S W − 1 ( μ 2 − μ 1 ) w = S_W^{-1}(\mu_2-\mu_1) w=SW−1(μ2−μ1)(8.113)
这就是二分类情况下的最优解了.如果$ S W ∝ I S_W\propto I SW∝I,就意味着汇总协方差矩阵(pooled covariance matrix)是各向同性的(isotropic),这样w就正比于联合类均值(joins class means)的向量.如图8.11所示,这是一个直觉上很合理的投影方向.
8.6.3.2 扩展到高维度和多分类情况
把上面的思路扩展到多分类情况,以及高维度子控件,只需要找到一个投影矩阵W,从D到L进行映射,最大化
J
(
W
)
=
W
Σ
B
W
T
W
Σ
W
W
T
J(W)=\frac{W\Sigma_BW^T}{W\Sigma_WW^T}
J(W)=WΣWWTWΣBWT(8.114)
其中
Σ
B
=
△
∑
c
N
c
N
(
μ
c
−
μ
)
(
μ
c
−
μ
)
T
(8.115)
Σ
W
=
△
∑
c
N
c
N
Σ
c
(8.116)
Σ
c
=
△
1
N
c
∑
i
:
y
i
=
c
(
x
i
−
μ
c
)
(
x
i
−
μ
c
)
T
(8.117)
\begin{aligned} \Sigma_B & \overset{\triangle}{=} \sum_c \frac{N_c}{N}(\mu_c-\mu)(\mu_c-\mu)^T &\text{(8.115)}\\ \Sigma_W & \overset{\triangle}{=} \sum_c \frac{N_c}{N}\Sigma_c &\text{(8.116)}\\ \Sigma_c & \overset{\triangle}{=} \frac{1}{N_c}\sum_{i:y_i=c} (x_i-\mu_c) (x_i-\mu_c)^T &\text{(8.117)}\\ \end{aligned}
ΣBΣWΣc=△c∑NNc(μc−μ)(μc−μ)T=△c∑NNcΣc=△Nc1i:yi=c∑(xi−μc)(xi−μc)T(8.115)(8.116)(8.117)
解就是:
W
=
Σ
W
−
1
2
U
W=\Sigma_W^{-\frac{1}{2}} U
W=ΣW−21U(8.118)
其中的U是 Σ W − 1 2 Σ B Σ W − 1 2 \Sigma_W^{-\frac{1}{2}} \Sigma_B\Sigma_W^{-\frac{1}{2}} ΣW−21ΣBΣW−21的L主特征向量(L leading eigenvectors),假设 Σ W \Sigma_W ΣW是非奇异的.(如果是奇异的,可以先对全部数据进行主成分分析(PCA).)
此处参考原书图8.12
图8.12所示为将这个方法应用到 D = 10 D=10 D=10维度的运输局,其中有 C = 11 C=11 C=11个不同的原因声音(vowel sounds).图中可见很明显FLDA得到的分类比PCA效果好.
要注意FLDA是限制在最多 L ≤ C − 1 L\le C-1 L≤C−1维度的线性子空间的,不管D有多大,这是因为类间协方差矩阵 Σ B \Sigma_B ΣB的秩(rank)就是 C − 1 C-1 C−1.(这里的-1是因为 μ \mu μ项是 μ c \mu_c μc的线性函数.)这限制了FLDA的使用.
8.6.3.3 FLDA的概率论解释*
对FLDA方法的概率论解释参考了(Kumar and Andreo 1998; Zhou et al. 2009).他们提出了一个模型,叫做异方差线性判别分析(heteroscedastic LDA,缩写为HLDA),过程如下所示.设W是一个 D × D D\times D D×D的可逆矩阵,设 z i = W x z_i=Wx zi=Wx是对数据的转换.然后对转换后的数据的每一类都拟合完整协方差高斯分布(full covariance Gaussians),但仅限于前面L个成分为分类拟合(class-specific);剩下的 H = D − L H=D-L H=D−L个成分在类间共享,因此也就不做区分(not be discriminative).也就是使用:
p ( z i ∣ θ , y i = c ) = N ( z i ∣ μ c , Σ c ) (8.119) μ c = △ ( m c ; m 0 ) (8.120) Σ c = △ ( S c 0 0 S 0 ) (8.121) \begin{aligned} p(z_i|\theta,y_i=c) &= N(z_i|\mu_c,\Sigma_c) &\text{(8.119)}\\ \mu_c & \overset{\triangle}{=} (m_c;m_0) &\text{(8.120)}\\ \Sigma_c & \overset{\triangle}{=} \begin{pmatrix} S_c & 0\\ 0 & S_0 \end{pmatrix} &\text{(8.121)}\\ \end{aligned} p(zi∣θ,yi=c)μcΣc=N(zi∣μc,Σc)=△(mc;m0)=△(Sc00S0)(8.119)(8.120)(8.121)
其中的 m 0 m_0 m0是共享的H维度均值,而 S 0 S_0 S0是共享的 H × H H\times H H×H协方差.原始数据(未变换过)的概率密度函数(pdf)为:
p ( x i ∣ y i = c , W , θ ) = ∣ W ∣ N ( W x i ∣ μ c , Σ c ) (8.122) = ∣ W ∣ N ( W L x i ∣ m c , S c ) N ( W H x i ∣ m 0 , S 0 ) (8.123) \begin{aligned} p(x_i|y_i=c,W,\theta)&= |W|N(Wx_i|\mu_c,\Sigma_c) &\text{(8.122)}\\ &=|W|N(W_L x_i|m_c,S_c) N(W_H x_i|m_0,S_0) &\text{(8.123)}\\ \end{aligned} p(xi∣yi=c,W,θ)=∣W∣N(Wxi∣μc,Σc)=∣W∣N(WLxi∣mc,Sc)N(WHxi∣m0,S0)(8.122)(8.123)
其中 w = ( W L W H ) w=\begin{pmatrix} W_L\\ W_H\end{pmatrix} w=(WLWH).对于固定的W,很不容易推导出 θ \theta θ的最大似然估计(MLE).然后可以使用梯度方法优化W.
在 Σ c \Sigma_c Σc为对角阵的特殊情况下,有一个W的闭合形式的解(Gales 1999).当所有 Σ c \Sigma_c Σc都一样的情况下,就会到了经典的线性判别分析(classical LDA, Zhou et al. 2009).
总的来看,如果雷协方差在可判别子空间内不相等(比如 Σ c \Sigma_c Σc独立于c是个错误假设),那么HLDA就会优于LDA.用合成数据(synthetic dat)就很容易演示出这种情况,另外更有挑战性的一些任务比如语音识别等等当中也是如此(Kumar and Andreo 1998).另外我们还可以通过让每个类都有自己的投影矩阵来进一步扩展这个模型,这样就成了多重线性判别分析(multiple LDA,Gales 2002).
练习略
KaTeX parse error: Expected 'EOF', got '&' at position 24: …0)}\\ \Sigma_c &̲ \overset{\tria…
其中的 m 0 m_0 m0是共享的H维度均值,而 S 0 S_0 S0是共享的 H × H H\times H H×H协方差.原始数据(未变换过)的概率密度函数(pdf)为:
p ( x i ∣ y i = c , W , θ ) = ∣ W ∣ N ( W x i ∣ μ c , Σ c ) (8.122) = ∣ W ∣ N ( W L x i ∣ m c , S c ) N ( W H x i ∣ m 0 , S 0 ) (8.123) \begin{aligned} p(x_i|y_i=c,W,\theta)&= |W|N(Wx_i|\mu_c,\Sigma_c) &\text{(8.122)}\\ &=|W|N(W_L x_i|m_c,S_c) N(W_H x_i|m_0,S_0) &\text{(8.123)}\\ \end{aligned} p(xi∣yi=c,W,θ)=∣W∣N(Wxi∣μc,Σc)=∣W∣N(WLxi∣mc,Sc)N(WHxi∣m0,S0)(8.122)(8.123)
其中 w = ( W L W H ) w=\begin{pmatrix} W_L\\ W_H\end{pmatrix} w=(WLWH).对于固定的W,很不容易推导出 θ \theta θ的最大似然估计(MLE).然后可以使用梯度方法优化W.
在 Σ c \Sigma_c Σc为对角阵的特殊情况下,有一个W的闭合形式的解(Gales 1999).当所有 Σ c \Sigma_c Σc都一样的情况下,就会到了经典的线性判别分析(classical LDA, Zhou et al. 2009).
总的来看,如果雷协方差在可判别子空间内不相等(比如 Σ c \Sigma_c Σc独立于c是个错误假设),那么HLDA就会优于LDA.用合成数据(synthetic dat)就很容易演示出这种情况,另外更有挑战性的一些任务比如语音识别等等当中也是如此(Kumar and Andreo 1998).另外我们还可以通过让每个类都有自己的投影矩阵来进一步扩展这个模型,这样就成了多重线性判别分析(multiple LDA,Gales 2002).
练习略


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









