






目录
设计任务及要求
哈夫曼编码/译码系统(树应用)
[问题描述] 利用哈夫曼编码进行通信,可以压缩通信的数据量,提高传输效率,缩短信息的传输时间,还有一定的保密性。现在要求编写一程序模拟传输过程,实现在发送前将要发送的字符信息进行编码,然后进行发送,接收后将传来的数据进行译码,即将信息还原成发送前的字符信息。
[实现提示] 在本例中设置发送者和接受者两个功能,
发送者的功能包括:
①输入待传送的字符信息;
②统计字符信息中出现的字符种类数和各字符出现的次数(频率);
③根据字符的种类数和各自出现的次数建立哈夫曼树;
④利用以上哈夫曼树求出各字符的哈夫曼编码;
⑤将字符信息转换成对应的编码信息进行传送。
接受者的功能包括:
①接收发送者传送来的编码信息;
②利用上述哈夫曼树对编码信息进行翻译,即将编码信息还原成发送前的字符信息。
从以上分析可发现,在本例中的主要算法有三个:
(1)哈夫曼树的建立;
(2)哈夫曼编码的生成;
(3)对编码信息的翻译。
前言(绪论)
哈夫曼编码是一种用于数据压缩的编码方式,它可以根据字符出现的频率来赋予不同长度的编码,从而实现对数据进行有效压缩。哈夫曼编码最初由大卫·哈夫曼(David A. Huffman)于1952年提出,是一种被广泛应用于数据压缩、通信领域的编码方式。它的主要原理是将出现频率高的字符用较短的编码表示,而出现频率低的字符用较长的编码表示,从而实现对数据的高效压缩。
哈夫曼编码可以节省存储空间。哈夫曼编码可以统计分析来确定每个字符的编码,将出现频率高的字符用短编码表示,出现频率低的字符用长编码表示。由于常用字符出现频率较高,所以通过哈夫曼编码压缩后的文件大小会比原文件小很多,这就可以节省存储空间。哈夫曼编码的核心思想是基于字符的出现频率来构建一颗“最优二叉树”,也就是哈夫曼树,可以保证整体数据的压缩率最大化。
由于压缩后的文件大小较小,哈夫曼编码可以加快数据传输速度,缩短传输时间。
哈夫曼编码可以保护数据的隐私,特别是在网络传输和存储重要数据时。通过将数据进行压缩再进行哈夫曼编码,可以使得数据难以被窃取和破解。
哈夫曼编码还在图像压缩、音频压缩等领域有广泛应用。在图像处理领域,哈夫曼编码可以对图像数据进行压缩,减小图像文件的大小,提高存储和传输效率;在音频处理领域,哈夫曼编码可以对音频数据进行压缩,降低音频文件的大小,提高音频传输的速率。可以说,哈夫曼编码在现代通信、信息处理领域有着广泛而重要的应用。
通过对数据出现频率的统计分析和编码规划,哈夫曼编码可以实现对数据的高效压缩,从而提高存储效率、传输速率,降低成本,对于提升通信、信息处理的效率和质量有着重要意义。因此,哈夫曼编码的应用前景广阔,对于提高现代通信、信息处理的效率和质量有着重要的推动作用。
设计主体
需求分析
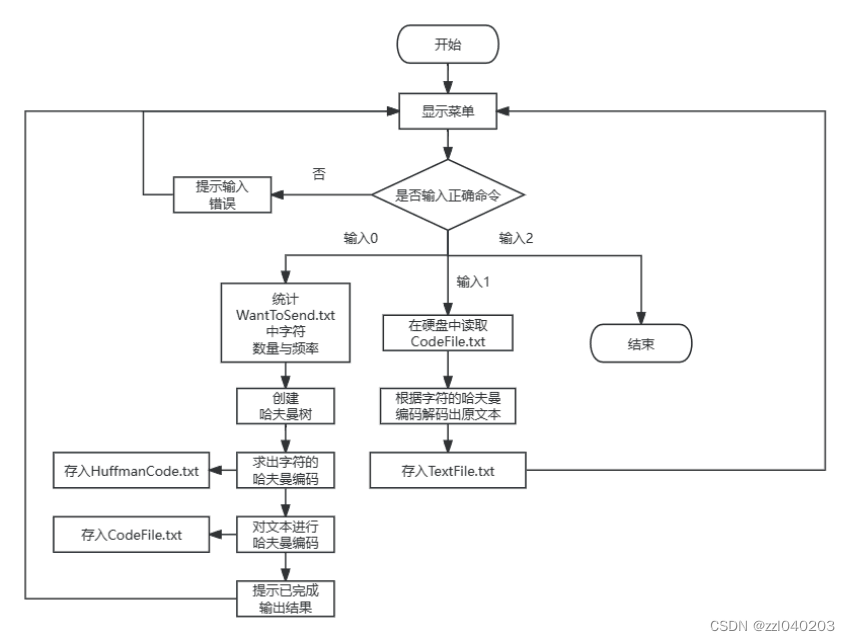
整个设计分为以下几个步骤。首先在文件中写好英文信息,在硬盘中文件读出要发送的信息。接着通过字符的频率建立哈夫曼树,生成对应字符的哈夫曼编码。利用哈夫曼编码将要发送的信息转换为文本的哈夫曼编码,存入文件,放在硬盘中。解码时,读出硬盘中的文件中存储的文本哈夫曼编码,根据对应字符的哈夫曼编码还原为文本文件,实现翻译。
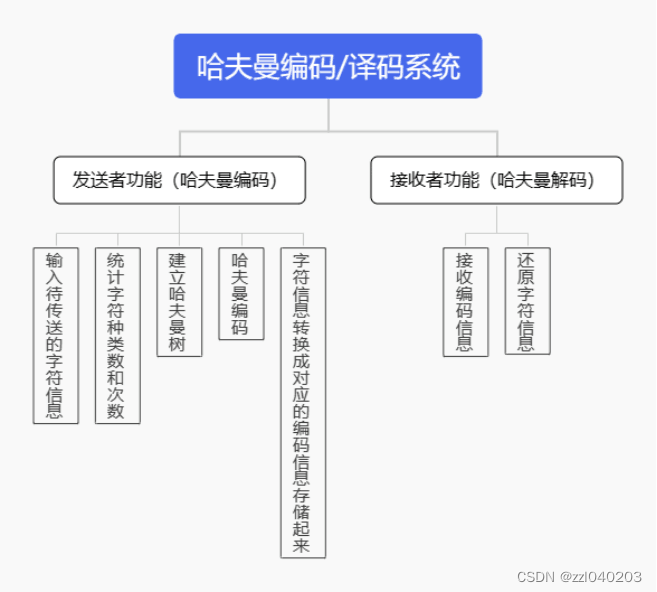
程序设计的任务是将设计分为两个部分,发送者和接受者,其中发送者和接收者都具有各自的功能。
发送者的功能需求包括:先在文本文件WantToSend.txt提前写入要传输的文本信息。然后通过文本文件输入待传送的英文字符信息,通过程序统计字符信息中出现的字符种类数和各字符出现的次数频率,根据字符的种类数和各自出现的次数建立哈夫曼树,利用以上哈夫曼树求出各字符的哈夫曼编码,将哈夫曼编码写入文本文件HuffmanCode.txt,存储字符权值,字符,编码。接下来将字符信息转换成对应的编码信息存入文本文件CodeFile.txt。
接受者的功能需求包括:通过读取硬盘中的文本文件CodeFile.txt接收发送者传送来的编码信息,利用文本文件HuffmanCode.txt中的哈夫曼树对编码信息进行解码翻译,将编码信息还原成发送前的字符信息,并存入文本文件TextFile.txt。
功能模块图
本系统在文本文件WantToSend.txt提前写入要传输的文本信息,只限于英文和一些标点符号,包括换行和空格。测试时,根据输入提示,用户只可以输入0,1,2,选择身份和功能,输入0则为发送者,根据编译时的WantToSend.txt中存储的文本,实现发送者的功能。输入1时则为接受者,根据编译时的CodeFile.txt中存储的文本,实现接受者的功能。输入2时退出系统,结束程序。输入其他数据时会提示输入错误退出系统。
流程图
函数之间的调用关系图
系统实现
算法实现:
- 统计字符频率;
- 创建Huffman树;
- 求每个字符的Huffman码;
- 对文件进行Huffman编码;
- 根据每个字符的Huffman码翻译文件的Huffman编码;
在程序调试过程中,我发现多种问题,有对概念的不清晰,也有对代码有疑问。如英文字符在txt文件里怎么存储的?经过查找资料得知在文本文件(txt文件)中,英文字符是以ASCII编码的形式存储的。在文本编辑器中,每个字符都被表示为一个字节,这个字节对应于ASCII编码表中的一个数字。
例如,字母"A"在ASCII编码中对应的数字是65,"a"对应的数字是97,"0"对应的数字是48,"!"对应的数字是33,依此类推。在文本文件中写入一个英文字符时,该字符会被转换为其对应的ASCII编码,并存储在文件中。打开文本文件并读取其中的内容时,文本编辑器会将每个字节转换回相应的字符。例如,如果文件包含字节65(对应于"A"),文本编辑器将显示该字符。
例如binafile.get();这段代码的工作原理是什么?经过查找资料得知binafile.get()是一个函数调用,用于从文件中读取一个字符。在二进制模式下,这会返回文件的下一个字节。如果文件不能打开或读取时发生错误,binafile.get()会返回特殊值EOF(通常是-1),表示文件结束或发生错误。这段代码只是读取了文件的第一个字节。如果想读取整个文件或文件的更多部分,需要使用循环或其他方法。
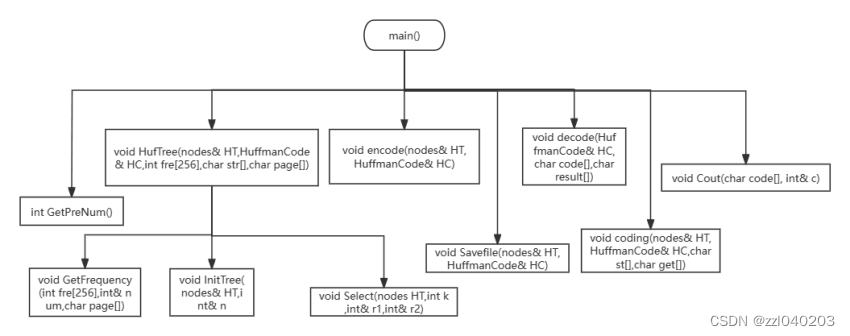
设计时我提前想好了大体的框架,分为main()函数,Sender.cpp,Receiver().cpp,这是需求决定的,当然可以只在一个文件里面写,但是考虑到这是一个工程,多文件的方式,多耦合少内聚对代码的可读性,维护性会更好。函数采取声明调用的方式,相对独立,确实在编写时有很大好处,不至于牵一发而动全身。
算法的时间复杂度会取决于要发送文件中存储的文本的字符种类多少和文本的长度以及字符出现的频率,如文件一中有100个“a”,文件二中有50个各种频率不同的字符,哈夫曼树的构建上文件一就要简单很多,文本的哈夫曼编码只需要100个0即可,远远小于文件二哈夫曼树和哈夫曼编码的时间复杂度和空间复杂度。
改进方面:
由于Windows系统特性,中文和一些非可打印字符的编码方式与字符不同,无法使用Huffman算法进行编码,压缩,译码。
没有为程序编写GUI界面,系统在美观性上有所不足。
用户手册
发送者:
- 在WantToSend.txt中写好要发送的文本;
- 打开DataStructCourseDesign.cbp文件编译运行;
- 在用户界面中输入0,选择发送者身份;
- 确认后,系统会完成哈夫曼编码;
接收者:
- 在用户界面中输入1,选择接收者身份;
- 确认后,系统会完成哈夫曼编码的解码翻译;
- 打开TextFile.txt可以查看翻译出的文本信息
测试
在WantToSend.txt中写入要发送的文本
打开DataStructCourseDesign.cbp文件编译运行
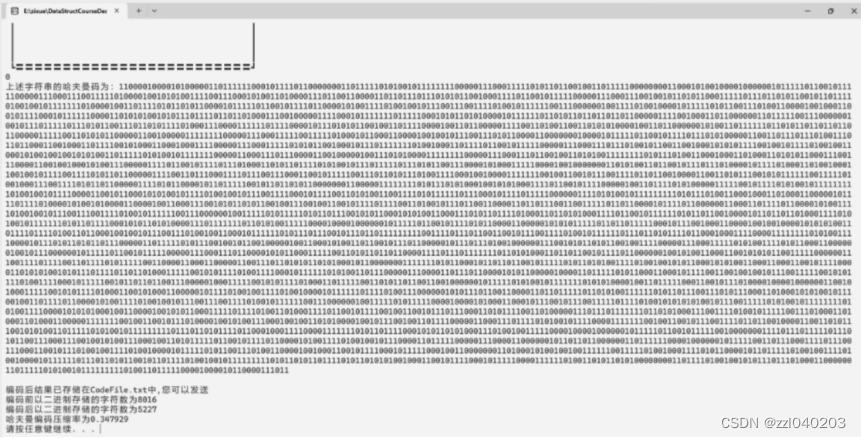
发送者功能效果

CodeFile.txt
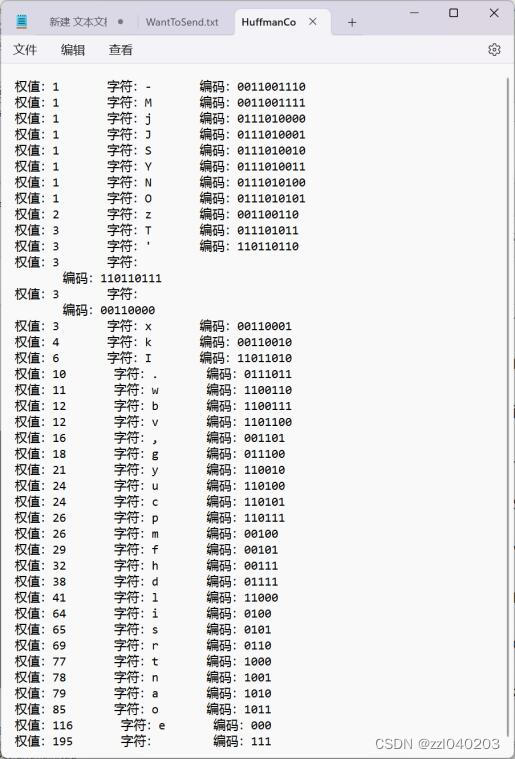
HuffmanCode.txt
CodeFile.txt

选择接收者功能

接收功能实现后TextFile.txt
退出
代码
Main.cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<fstream>
#include<algorithm>
#include<string>
#include<math.h>
#include"Sender.h"
#include"Receiver.h"
#include<cstring>
using namespace std;
void Show()
{
cout<<" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ "<<endl;
cout<<" ┃ 哈夫曼编码系统 ┃ "<<endl;
cout<<" ┏〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓┓"<<endl;
cout<<" ┃ 欢迎使用哈夫曼编码系统! ┃"<<endl;
cout<<" ┃ 请选择你的身份:输入0或者1 ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ 0.发送者 ┃"<<endl;
cout<<" ┃ 1.接收者 ┃"<<endl;
cout<<" ┃ 2.退出 ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┃ ┃"<<endl;
cout<<" ┗〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓┛"<<endl;
}
int main()
{
n = 0;//字符种类个数n
prenum = 0;
char str[256] = {};
// 出现的字符种类,
//二进制以8位(1字节)为单位存储
//0~255能够恰好对应ASCII码对照表中的所有256个字符
char st[20000] = {};//输入编码字符
char result[20000] = {};//译码结果
int d[256] = {};//存放字符权值,下标为字符的ASCII码
nodes HT;
//1.初始化
HuffmanCode HC;
HufTree(HT,HC,d,str,st);
str[n] = '\0';
encode(HT,HC);
Savefile(HT,HC);
while(true)
{
system("cls");
Show();
int select = -1;
cin>>select;
if(select == 0)//发送者
{
//2.编码
char get[20000];
get[0] = '\0';//字符串get的开头添加一个终止符,初始化
coding(HT,HC,st,get);//输入编码字符串的哈夫曼编码
cout<<"上述字符串的哈夫曼码为:"<<get<<endl<<endl;
cout<<"编码后结果已存储在CodeFile.txt中,您可以发送"<<endl;
cout<<"编码前以二进制存储的字符数为"<<GetPreNum()<<endl;
cout<<"编码后以二进制存储的字符数为"<<strlen(get)<<endl;
cout<<"哈夫曼编码压缩率为"<<(1-((double)(strlen(get))/((double)GetPreNum())))<<endl;
system("pause");
}
else if(select == 1)//接收者
{
//3.译码
char code[20000] = {};//读出来的码
int c = 0;
Cout(code,c);//读CodeFile.txt里面的字符
code[c-1] = '\0';
decode(HC,code,result);
cout<<endl<<"译码结果为:";
for (int i = 0;i<c;i++)
{
cout<<result[i];
}
cout<<"解码后结果已存储在TextFile.txt"<<endl;
system("pause");
}
else if(select == 2)
{
break;
}
else
{
cout<<"输入错误,请重新输入";
system("pause");
}
}
return 0;
}Receiver.h
#ifndef RECEIVER_H_INCLUDED
#define RECEIVER_H_INCLUDED
#include<iostream>
#include"Sender.h"
using namespace std;
void decode(HuffmanCode& HC, char code[],char result[]);//译码
void Cout(char code[], int& c);//读取需译码的文件并统计文件码字数
#endif // RECEIVER_H_INCLUDEDReceiver.cpp
#include"Receiver.h"
#include<iostream>
#include<string.h>
#include<fstream>
#include<algorithm>
using namespace std;
void decode(HuffmanCode& HC,char code[],char result[])//译码函数
{
char cd[20];//用于存储解码的字符序列
int i,j,k = 0,p = 0,flag;
while(code[p] != '\0')
{
flag = 0;//表示当前字符是否找到匹配的Huffman编码
for(i = 0;(i<n)&&(flag == 0);i++)
{
cd[i] = ' ';//码字不相等时跳出循环,读取码字长度加1位
cd[i+1] = '\0';
cd[i] = code[p];
p++;
for(j = 0;j <= n;j++)//遍历Huffman编码尝试找到与读出的字符匹配的编码
{
if(strcmp(HC[j].bits,cd) == 0)//字符的码和读出来的码是否相等,0相等
{
result[k] = HC[j].ch;
k++;
flag = 1;
break;
}
}
}
}
result[k] = '\0';//字符串的结束
ofstream savefile3;//输出文件流对象
savefile3.open("TextFile.txt");
if(!savefile3)
{
cerr<<"TextFile.txt文件打开失败"<<endl;
exit(1);
}
savefile3<<result;
savefile3.close();
}
void Cout(char code[], int& c)//读取需译码的文件并统计文件码字数
{
ifstream fin;
fin.open("CodeFile.txt", ios::binary);
if (!fin.is_open())
{
cerr<<"没有此文件或读取错误"<<endl;
cerr<<"CodeFile.txt打开失败"<<endl;
}
while (!fin.eof())//遍历文件
{
unsigned int t = fin.get();
code[c] = t;//读取到的字符储到code数组
c++;
}
fin.close();
}Sender.h
#ifndef SENDER_H_INCLUDED
#define SENDER_H_INCLUDED
#include<iostream>
using namespace std;
extern int n; // 声明,不是定义
extern int prenum;
typedef struct
{
char ch;//出现的各字符种类
char bits[15];//各字母的码字
int len;
}CodeNode;
typedef CodeNode HuffmanCode[256];
typedef struct
{
//数据成员
int weight;//权数据域
int parent, lchild, rchild;//双亲,左右孩子域
char key;
}HufNode ;
typedef HufNode nodes[256];//用结构体数组表示编码部分数据
void Getfrequen(int d[256], int& n,char page[]);//字符统计函数
void InitTree(nodes& HT,int& n);//哈夫曼树初始化
void select(nodes HT,int k, int& r1, int& r2);//挑选最小的和次小的二叉树
void Savefile(nodes& HT, HuffmanCode& HC);//保存文件
void HufTree(nodes& HT, HuffmanCode& HC, int d[256], char str[],char page[]);//哈夫曼树建立
void encode(nodes& HT, HuffmanCode& HC);//对各字符进行哈夫曼编码
void coding(nodes& HT, HuffmanCode& HC, char st[], char get[]);//对文本正文进行编码
int GetPreNum();//求未编码前的文本存储花费的空间
#endif // SENDER_H_INCLUDEDSender.cpp
#include"Sender.h"
#include<iostream>
#include<string.h>
#include<fstream>
#include<algorithm>
using namespace std;
int n;//字符种类个数
int prenum;//未编码前的文本中用二进制01表示的字符数
//函数GetFrequency,参数为:
//一个大小为256的整数数组fre,用于存储每个字节值的频率
//一个引用整数num,用于计数文件中字节值的总数
//以及一个字符数组page,用于存储每个字节值
int GetPreNum()//求未编码前的文本存储花费的空间
{
ifstream binafile2("WantToSend.txt",ios::binary);
int presum = 0;
char ch;
binafile2>>ch;
while(binafile2.good())//未读到EOF时可以循环
{
presum++;//读一个字符记录加1
binafile2>>ch;
}
return presum*8;//1个字符8个字节,即8个01符号
}
void GetFrequency(int fre[256],int& num,char page[])//字符统计函数
{
int p = 0;//定义一个整数p并初始化为0,记录page数组的当前位置
ifstream binafile("WantToSend.txt",ios::binary);//表示以二进制模式打开文件并从文件中读取数据
num = 0;//num初始化为0表示文件中字节值的总数
while(!binafile.eof())//遍历文件读取文本文件内容存至数组,直到end of file
{
unsigned int temp = binafile.get();//binafile.get()从文件中读取一个字符并返回它的ASCII值(int4个字节)
//读一次就是1个字符存在temp变量里,8位,8个01
if(temp>128)break;//只处理ASCII码中的可打印字符,它们的值都在0-127之间
if(fre[temp] == 0)//计数为0这个字节值还未出现过
{
fre[temp] = 1;
num++;//增加该字节值的计数
}
else fre[temp]++;//此时字符种数不用+1
page[p] = temp;//将当前字节值存储在page数组中
p++;//增加p的值以跟踪数组的当前位置
}
binafile.close();//关闭文件
}
void InitTree(nodes& HT,int& n)//初始化哈夫曼树
{
for(int i = 0;i<2*n-1;i++)//n个叶子节点经过n-1次构造多出n-1个,总共2n-1
{
HT[i].lchild = -1;//-1表示没有左孩子
HT[i].rchild = -1;//-1表示没有右孩子
HT[i].parent = -1;//-1表示没有父节点
HT[i].weight = -1;//-1表示没有权重值
}
}
void Select(nodes HT,int k,int& r1,int& r2)//挑选最小的和次小的二叉树
{
r1 = r2 = -1;
for(int i = 0;i<k;i++)//查找前k个节点中的最小权值
{
if(HT[i].parent == -1)//检查当前节点是否是根节点,根节点代表完整的树
{
if (r1 == -1)
{
r1 = i;//r1没赋值将当前树的索引赋值r1当第一棵权值最小的树
}
else if(HT[i].weight<HT[r1].weight)//当前树权值小于第一棵最小权值树
{
r2 = r1;//更新r2为当前第二小的索引
r1 = i;//更新r1为当前树的索引
}
else if(r2 == -1||HT[i].weight<HT[r2].weight)
r2 = i;//小于第二棵树权值
}
}
}
void Savefile(nodes& HT,HuffmanCode& HC)//保存文件
{
ofstream savefile2;
savefile2.open("HuffmanCode.txt");
if (!savefile2)
{
cerr<<"HuffmanCode.txt文件打开失败"<<endl;
exit(1);
}
for(int h=0;h<n;h++)
{
savefile2<<"权值:"<<HT[h].weight<<" "
<<"字符:"<<HT[h].key<<" "
<<"编码:"<<HC[h].bits<<endl;
}
}
//建立哈夫曼树
void HufTree(nodes& HT,HuffmanCode& HC,int fre[256],char str[],char page[])
{
int w,num;//w存储当前最大频率,num记录当前剩余的字符数量
int i,s1,s2;
GetFrequency(fre,n,page);//获取字符的频率存储在数组fre
num = n;
InitTree(HT,n);
while(num>0)
{
ifstream binafile("WantToSend.txt",ios::binary);
while (!binafile.eof())//遍历文件,end of file
{
unsigned int temp = binafile.get();
if (fre[temp] <= 0)continue;
w = *max_element(fre,fre+256);//找到当前最高频率
if(fre[temp] == w)//对结点的权值进行赋值
{
HT[num-1].weight = w;
HT[num-1].key = temp;
str[num-1] = temp;
fre[temp] = 0;//从频率数组中删除该字符
num--;//减少剩余字符数量
break;
}
}
binafile.close();
}
for(i = n ;i<(2*n-1);i++)
{
Select(HT,i,s1,s2);//选出最小的两个结点放在s1、s2
//往HT序列后一位i放置新生成的父亲结点
HT[s1].parent = i;//s1结点的父结点为i结点
HT[s2].parent = i;//s2结点的父结点为i结点
HT[i].lchild = s1;//父结点的左孩子结点为s1结点
HT[i].rchild = s2;//父结点的右孩子结点为s2结点
HT[i].weight = HT[s1].weight+HT[s2].weight;//计算父结点的权值
}
for (i = 0;i<n;i++)//初始化哈夫曼编码
{
HC[i].ch = str[i];
}
}
void encode(nodes& HT, HuffmanCode& HC)//对各字符进行哈夫曼编码
{
int c, p, i;
//c用于遍历节点
//p用于存储父节点
//i用于遍历字符
char cd[256] = {};//存储当前字符的Huffman编码
int start;//记录编码起始位置(结尾位置为n)
cd[n] = '\0';//设置编码结尾位置
for(i = 0;i<n;i++)
{
start = n-1;
c = i;//c为当前字符的索引
while((p = HT[c].parent) > 0)//父节点存在时,持续进行循环,倒序编码
{
start--;
cd[start] = ((HT[p].lchild == c)?'0':'1');
c = p;
}
strcpy(HC[i].bits, &cd[start]);
HC[i].len = n-start;
}
}
void coding(nodes& HT,HuffmanCode& HC,char st[],char get[])//对文本正文进行编码
{
int i,j = 0,length = 0;
while(st[j] != '\0')//根据文本的字符顺序用哈夫曼编码进行编码
{
for(i = 0;i<n;i++)
{
if(HC[i].ch == st[j])//检查当前字符节点是否与文本字符串中的当前字符相等
{
strcat(get, HC[i].bits);//将该节点的Huffman编码添加到结果字符串get中
length = HC[i].len+length;
break;
}
}
j++;//文本字符串索引
}
strcat(get,"\0");
ofstream savefile;
savefile.open("CodeFile.txt",ios::binary);//二进制模式写入
if (!savefile)//没打开就抛出异常
{
cerr<<"CodeFile.txt文件打开失败"<<endl;
exit(1);
}
savefile<<get;//将结果字符串get写入文件
savefile.close();
}














 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









