







WXG面试时有问过这个环节,还好复试的时候有准备过,留了一份库存,一般问到这个方面,说明你的基础基本过关,面试官会根据简历和自己感兴趣的东西问,有点了解的话会有很大的加分。
1. 逻辑回归
逻辑回归是一种分类算法,是用于处理因变量为分类变量的回归问题 。
sigmod函数,函数如下:
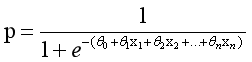
损失函数:
P(正确) = *
若想让预测出的结果全部正确的概率最大,根据最大似然估计,就是所有样本预测正确的概率相乘得到的P最大
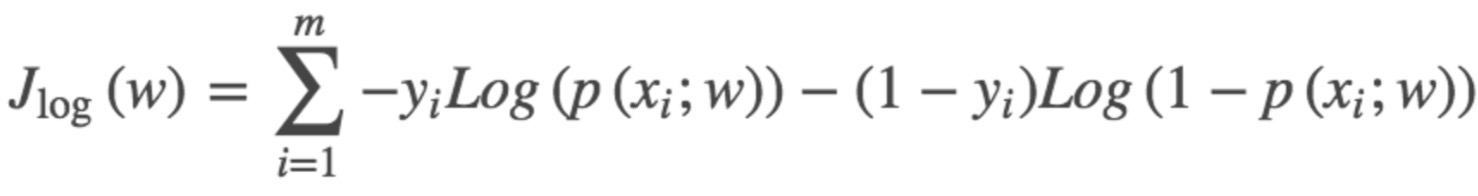
因为在函数最优化的时候习惯让一个函数越小越好,所以我们在这个函数前面加一个负号,就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数
2. KNN算法
1. 描述
假设有一群训练样本,每个样本有自己的标签类,对测试样本,计算与所有训练样本之间的欧式距离,选出距离最小的前K个训练样本,这些样本中哪个类出现的次数最多,测试样本就属于哪一个类
2. 优缺点
优点
- 精度高
- 可用于数值型数据和离散型数据;
- 训练时间复杂度为O(n);
- 对异常值不敏感。
缺点
- 计算复杂性高;空间复杂性高;
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
3. K-Means聚类算法
1. 描述
从数据集中随机选择k个样本作为初始的k个质心向量,分别计算所有样本数据到k个质心之间的距离,距离最小的质心即为样本所在的类;大致分类后,对每一类的数据集样本取均值得到新的质心,计算整个数据集到新的k个质心之间的距离,重复之前的操作,直到更新的质心稳定为止。
2. 优缺点
优点
- 收敛速度快
- 聚类效果较优
缺点
- 对于不是凸的数据集比较难收敛
- 对噪音和异常点比较的敏感。















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









