







🌞欢迎来到机器学习的世界
🌈博客主页:卿云阁
💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2021年5月9日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

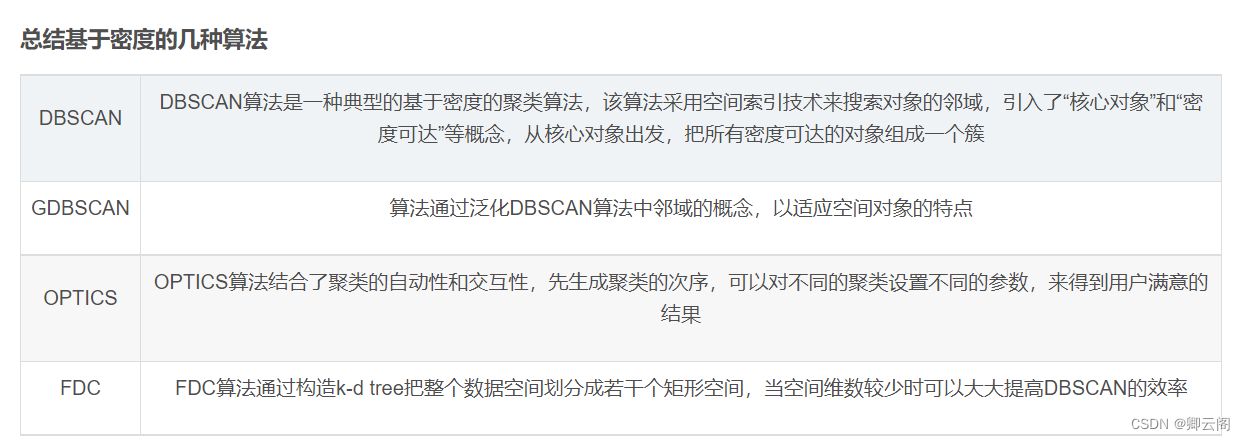
🍈 一、聚类的基本概念
定义
1.
m=3
2.
k=2
3. x1——>1
x2——>2
x3——>1 (1,2指的是簇的标签)
更简单的说聚类把相似的数据汇总为簇的方法叫作 聚类 。k - means 算法 是一种聚类算法,该算法非常简单,所以被广泛应用于数据分析。性能度量(簇内相似度高,簇间相似度低)公式




 (1)簇内样本间的平均距离
(1)簇内样本间的平均距离

 (2)簇内样本间的最远距离
(2)簇内样本间的最远距离

 (3)簇间样本间的最近的样本的距离
(3)簇间样本间的最近的样本的距离

 (4)簇间样本中心点间的距离
(4)簇间样本中心点间的距离



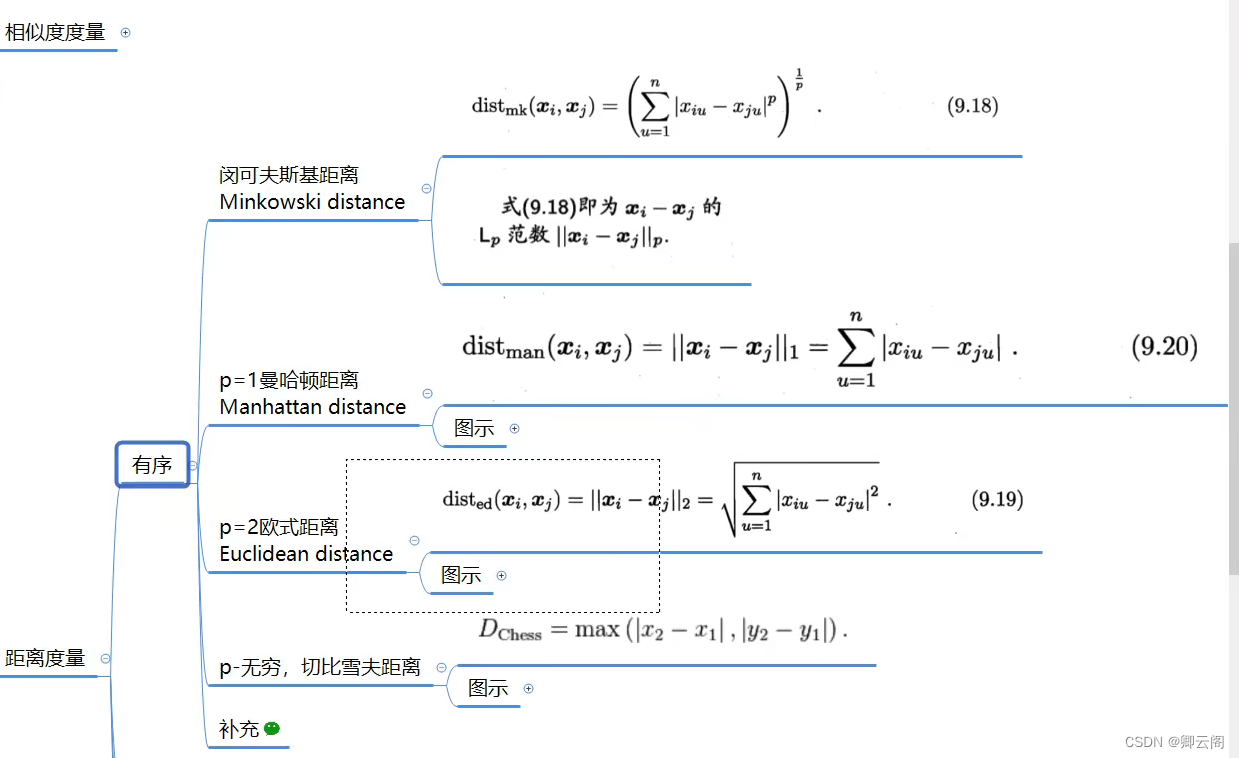
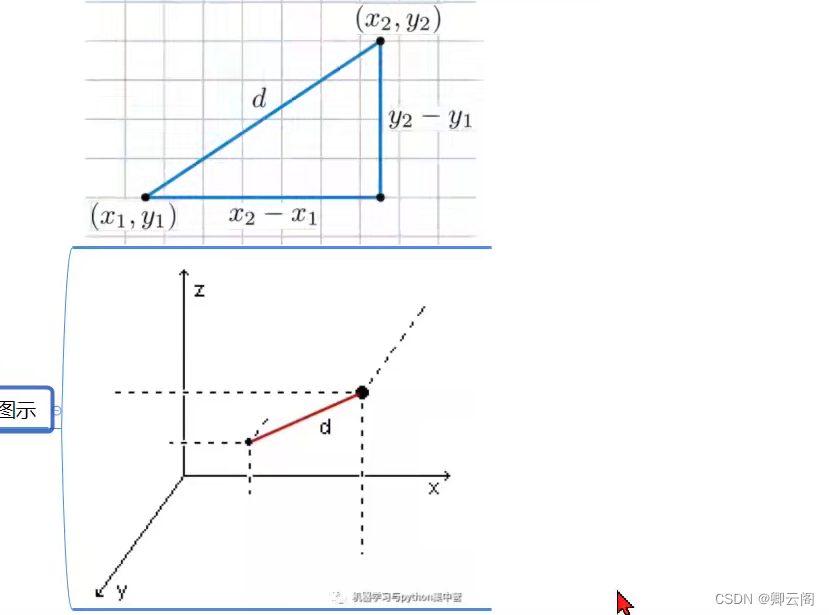
距离计算(目的是衡量两个东西的相似性)
距离度量-有序
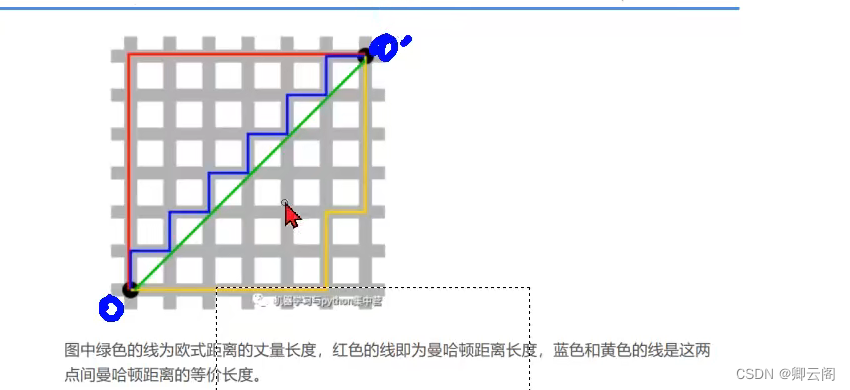
当p=1时,叫做曼哈顿距离
当p=2时,叫做欧式距离
距离度量-无序
如何衡量他们之间的距离呢?
假设分为3个簇
r b i=1 C1 7 10 i=2 C2 3 5 i=3 C3 1 2 11 17 混合和加权
🥝二、k-means 算法
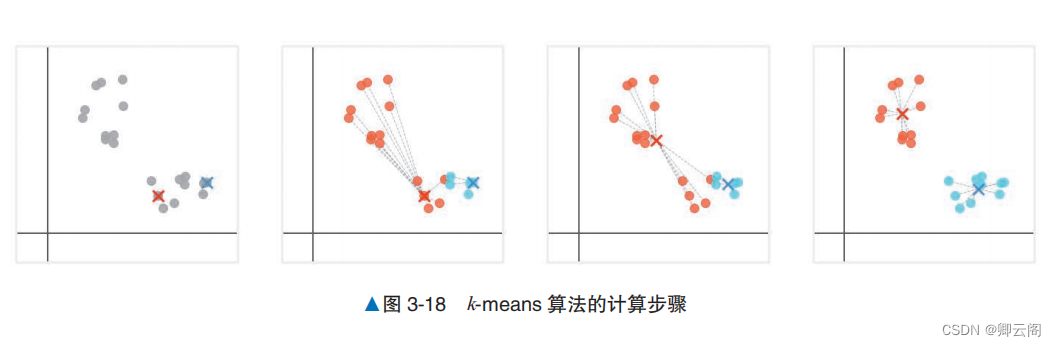
概述× 表示的点是各个簇的重心,是 k -means 算法中簇的代表点。 通过计算数据点与各重心的距离,找出离得最近的簇的重心,可以确定数据点所属的簇。求簇的重心是 k-means 算法中重要的计算。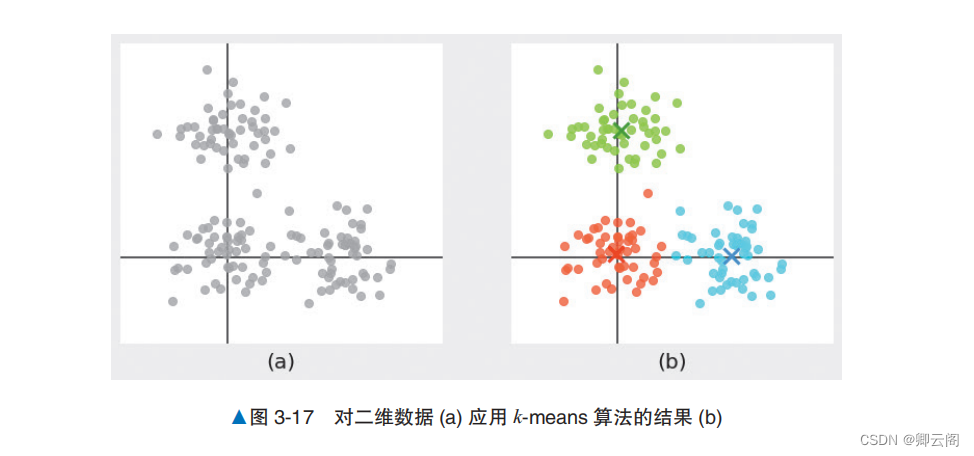
过程
1. 从数据点中随机选择数量与簇的数量相同的数据点,作为这些簇的重心。2. 计算数据点与各重心之间的距离,并将最近的重心所在的簇作为该数据点所属的簇。3. 计算每个簇的数据点的平均值,并将其作为新的重心。4. 重复步骤 2 和步骤 3,继续计算,直到所有数据点不改变所属的簇,或者达到最大计算步数。上面的方法可能会出现两个问题
1.如何确定簇的数量?
Elbow 方法 (肘方法)等 技巧2.如何确定初始的重心?
可以利用 k -means + + 等方法,选择位置尽可能远离 的数据点作为重心的初始值,就可以解决这个问题。
🍊二、综合举例
聚类的分类
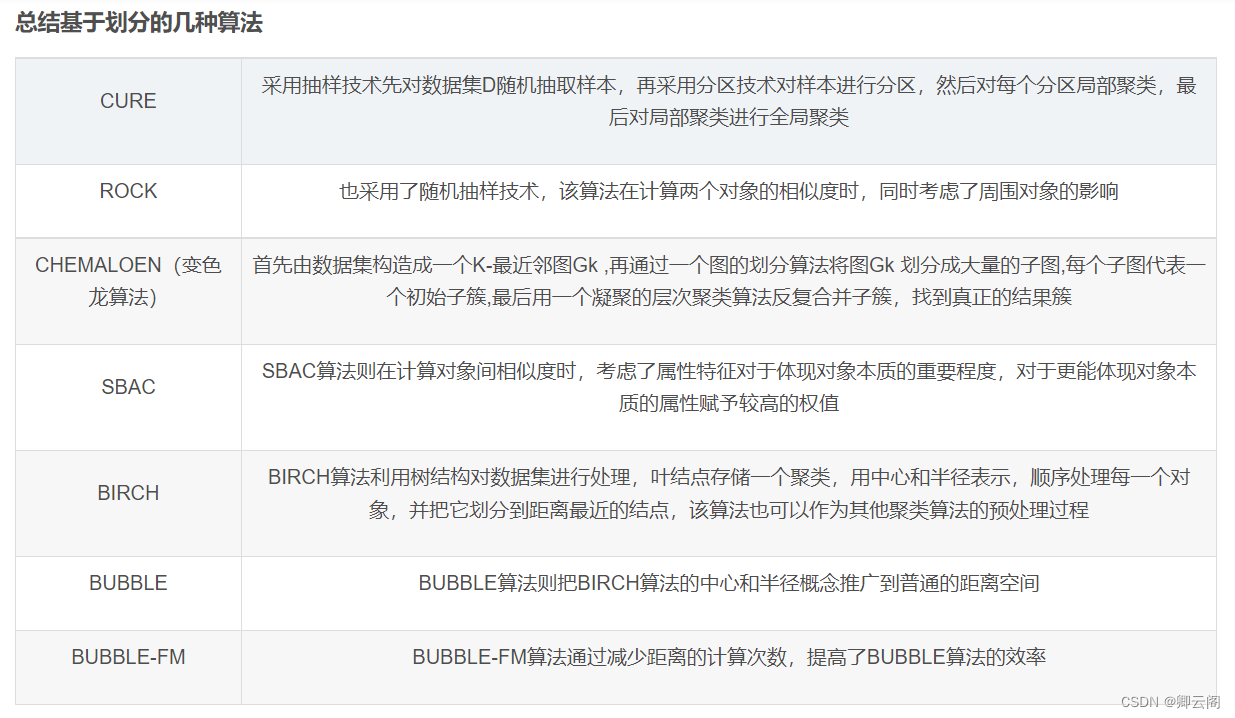
基于划分的聚类
基于层次的聚类
基于密度的聚类(DBSCAN算法、OPTICS算法、DENCLUE算法)
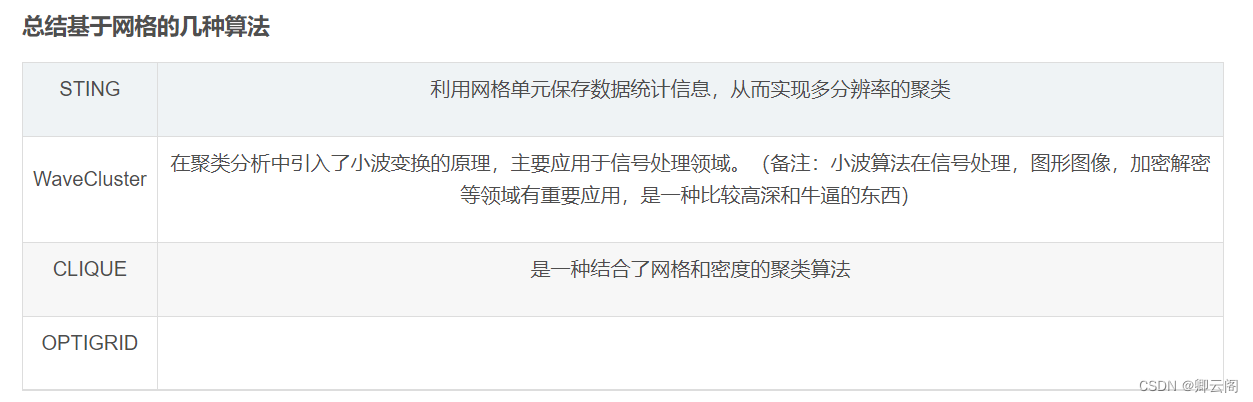
基于网格的聚类
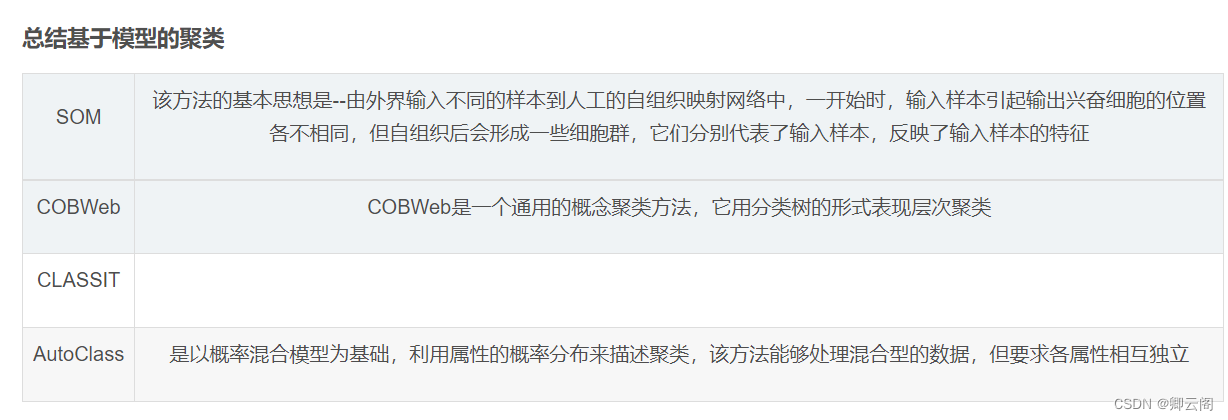
基于模型的聚类(模糊聚类、Kohonen神经网络聚类)
常见的内部指标
- 轮廓系数
- Calinski-Harabaz系数(CH指数)
- Davies-Bouldin系数(DBI指数)
1.应用常见的聚类算法实现对鸢尾花的聚类分析(下面将使用k-means)
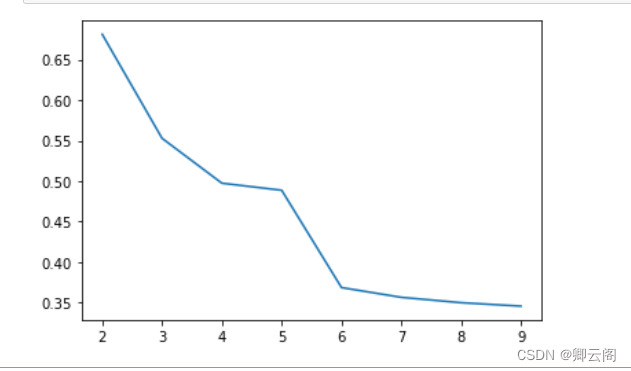
#导入所需要的库,读取数据 import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import KMeans #from sklearn import datasets准确率: 0.84375 from sklearn.datasets import load_iris #从sklearn库中导入鸢尾花数据集iris = load_iris() X = iris.data[:] label_true=iris.targetestimator = KMeans(n_clusters=3) #构造聚类器 estimator.fit(X) #聚类 label_pred = estimator.labels_ #获取聚类标签x0 = X[label_pred == 0] x1 = X[label_pred == 1] x2 = X[label_pred == 2] plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0') plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1') plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='label2') plt.xlabel('petal length') plt.ylabel('petal width') plt.legend(loc=2) plt.show()#评价轮廓系数-越大越好 from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score for k in range(2,10): estimator = KMeans(n_clusters=k) #构造聚类器 estimator.fit(X) #聚类 label_pred = estimator.labels_ #获取聚类标签 score = silhouette_score(X,label_pred) print(score )0.681046169211746 0.5528190123564091 0.49745518901737446 0.4939444414814319 0.3557536089245223 0.3566882476581684 0.3519340715227998 0.3434477079729074#评价轮廓系数画图-越大越好 from sklearn import metrics from sklearn.metrics import silhouette_score from sklearn.metrics import pairwise_distances from sklearn import datasets from sklearn.datasets import load_iris import numpy as np from sklearn.cluster import KMeans iris = load_iris() X = iris.data[:] score = [] for k in range(2,10): estimator = KMeans(n_clusters=k) #构造聚类器 estimator.fit(X) #聚类 label_pred = estimator.labels_ #获取聚类标签 score.append(silhouette_score(X,label_pred,metric='euclidean')) fig,ax = plt.subplots() ax.plot(np.arange(2,10),score) plt.show()
#DBI计算 from sklearn import datasets from sklearn.cluster import SpectralClustering from sklearn.metrics import davies_bouldin_score from sklearn.datasets import load_iris iris = load_iris() X = iris.data[:] score = [] for k in range(2,10): model = SpectralClustering(n_clusters=k) model.fit(X) labels = model.labels_ print(davies_bouldin_score(X,labels))0.3827528421006873 0.6538599267578274 0.6578898903340367 0.7328611326295954 0.8496699933501106 0.8877017815391061 0.9169052433119987 0.8705819422261372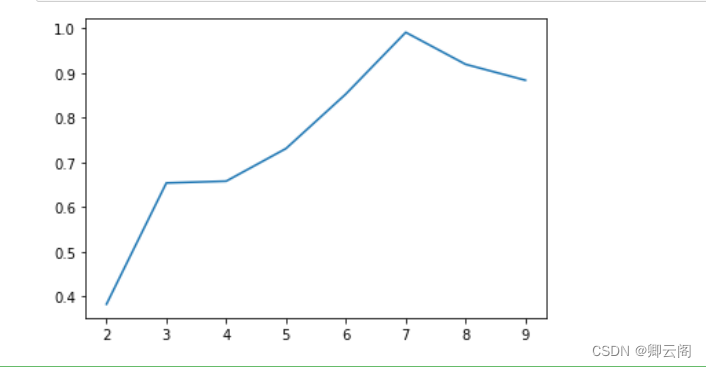
#CH计算 import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import load_iris from sklearn.metrics import calinski_harabasz_score iris = load_iris() X = iris.data[:] label_true=iris.target score = [] for i in range(2,10): model = KMeans(n_clusters=i,random_state=1).fit(X) labels = model.labels_ score.append(calinski_harabasz_score(X,labels)) fig,ax = plt.subplots() ax.plot(np.arange(2,10),score) plt.show()
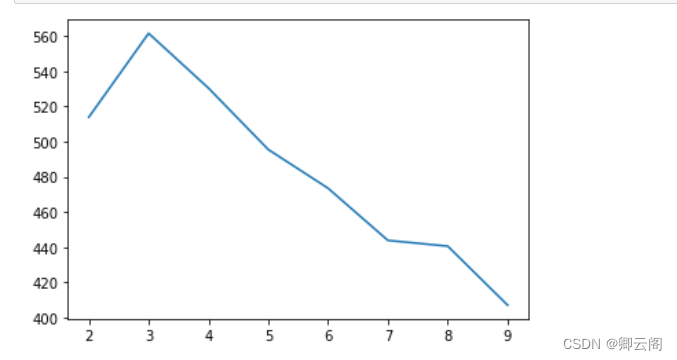
#CH计算-越大越好 import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import load_iris from sklearn.metrics import calinski_harabasz_score iris = load_iris() X = iris.data[:] score = [] for i in range(2,10): model = KMeans(n_clusters=i,random_state=1).fit(X) labels = model.labels_ print(calinski_harabasz_score(X,labels))513.9245459802768 561.62775662962 530.4871420421675 495.54148767768777 473.5154538824768 443.84523107907245 440.59767319067873 407.04684002651132应用聚类算法实现对广告的聚类分析
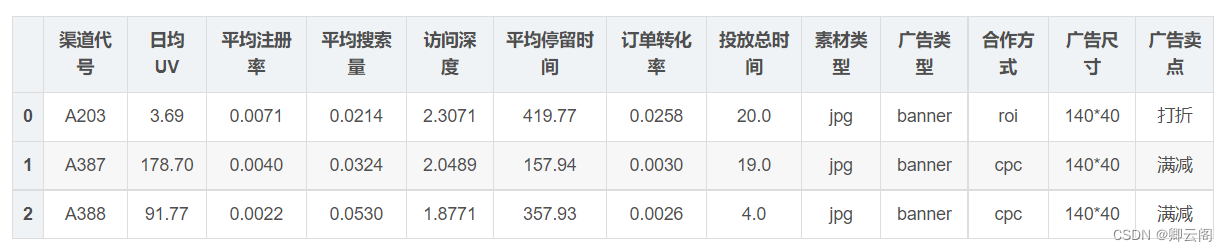
本案例,通过各类广告渠道90天内额日均UV,平均注册率、平均搜索率、访问深度、平均停留时长、订单转化率、投放时间、素材类型、广告类型、合作方式、广告尺寸和广告卖点等特征,将渠道分类,找出每类渠道的重点特征,为业务讨论和数据分析提供支持。
数据13个维度介绍
- 渠道代号: 渠道唯一标识
- 日均UV: 每天的独立访问量
- 平均注册率: 日均注册用户数/平均每日访问量
- 平均搜索量: 每个访问的搜索量
- 访问深度: 总页面浏览量/平均每天的访问量
- 平均停留时长:总停留时长/平均每天的访问量
- 订单转化率: 总订单数量/平均每天的访客量
- 投放时间 : 每个广告在外投放的天数
- 素材类型: ‘jpg’ ‘swf’ ‘gif’ ‘sp’
- 广告类型: banner. tips. 不确定. 横幅. 暂停
- 合作方式: ‘roi’ ‘cpc’ ‘cpm’ ‘cpd’
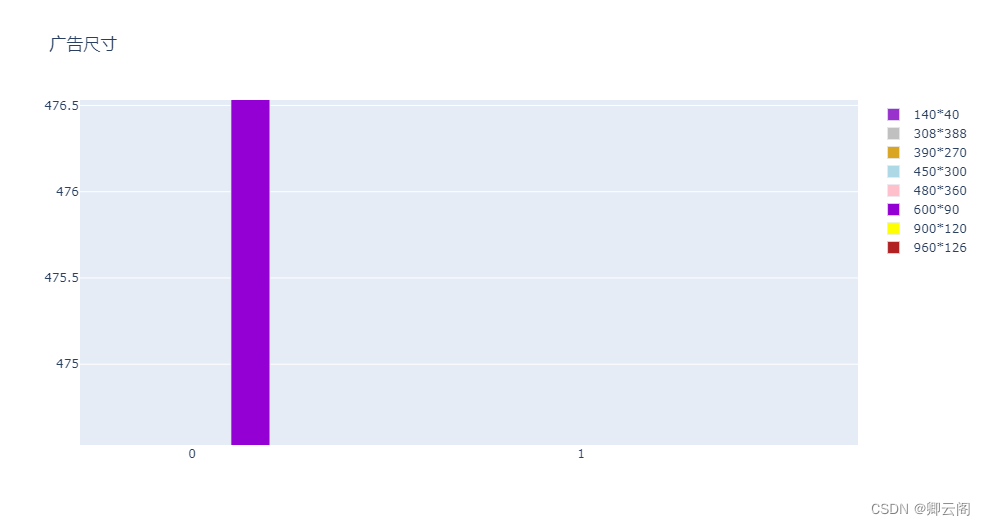
- 广告尺寸: ‘14040’ ‘308388’ ‘450300’ ‘60090’ ‘480360’ ‘960126’ ‘900120’‘390270’
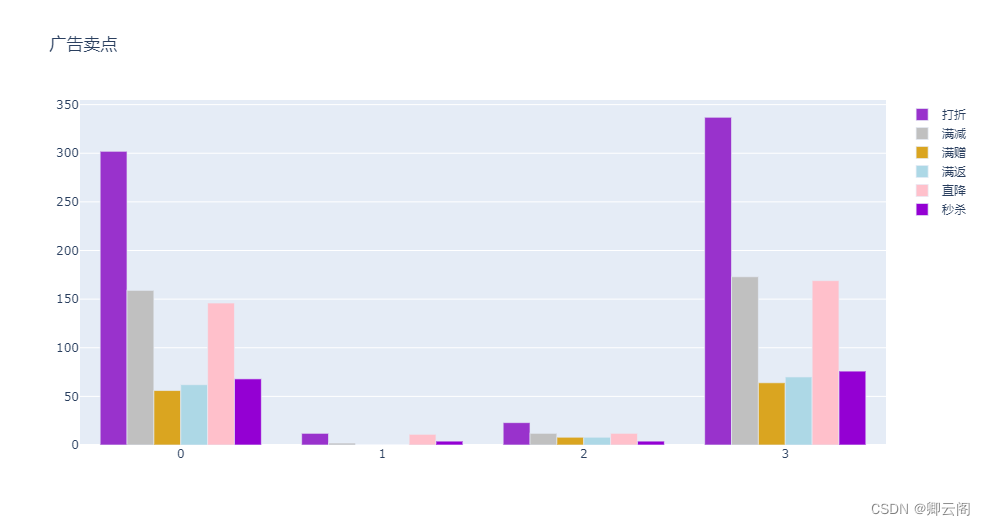
- 广告卖点: 打折. 满减. 满赠. 秒杀. 直降. 满返
目标:
- 完成缺失值处理
- 完成相关性分析
- 完成数据编码与标准化
- 完成建立KMeans聚类模型
- 对模型结果进行分析总结
- 聚类分析可视化展示(选做)
下面开始我的表演
导入库,加载数据
import pandas as pd import numpy as np import scipy import seaborn as sns from sklearn.cluster import KMeans #from sklearn.cluster import SpectralClustering from sklearn.preprocessing import MinMaxScaler,OrdinalEncoder from sklearn import metrics data = pd.read_csv('D:/ad_performance.txt',delimiter='\t')处理缺失值及无用的列
data['平均停留时间'] = data['平均停留时间'].fillna(data['平均停留时间'].mean()) data = data.drop('渠道代号',axis=1)标准化数据,该步骤可以有效削减异常值得影响及加快模型运行速度。
num_cols = [f for f in data.columns if data[f].dtypes != 'object'] num_cols.remove('投放总时间') num_colsnum_data = data[num_cols] num_data = MinMaxScaler().fit_transform(num_data) num_data = pd.DataFrame(num_data) num_data.columns = num_cols建立模型,对模型效果打分,选出最合适的聚类簇数。
scores = [] for i in range(2,8): model_kmeans = KMeans(n_clusters=i,random_state=0) model_kmeans = model_kmeans.fit(num_data) cluster_labels_kmeans = model_kmeans.labels_ score_s = metrics.silhouette_score(num_data,cluster_labels_kmeans) score_c = metrics.calinski_harabasz_score(num_data,cluster_labels_kmeans) scores.append([score_s,score_c]) scores[[0.7773548485913526, 408.67744816391775], [0.6707795187925366, 378.25539589983714], [0.69059456208538, 370.8303938282315], [0.6983863707618452, 359.38501676131534], [0.5776403351620265, 393.0848761624726], [0.5615591749860291, 416.84530609595384]]选出最合适的簇数后再次建模
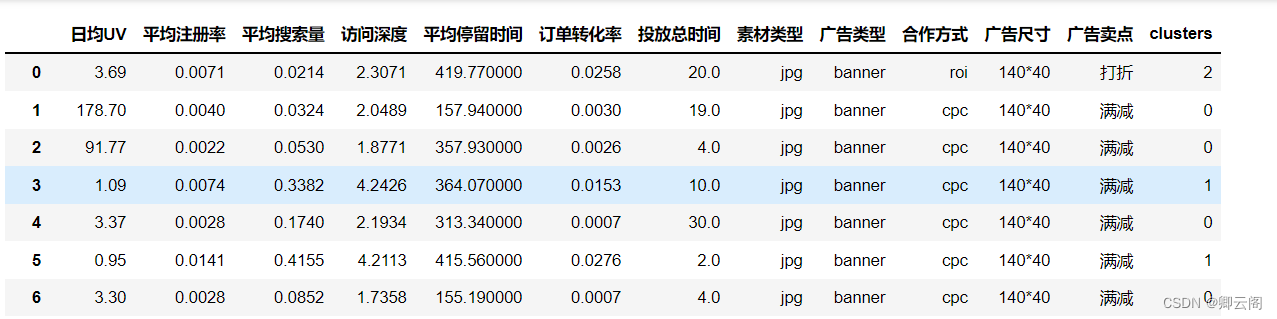
model_kmeans = KMeans(n_clusters=3) model_kmeans = model_kmeans.fit(num_data) cluster_labels_kmeans = model_kmeans.labels_ score_s = metrics.silhouette_score(num_data,cluster_labels_kmeans) score_c = metrics.calinski_harabasz_score(num_data,cluster_labels_kmeans) print(score_s,score_c)0.6707795187925366 378.25539589983714将聚类后的标签与原数据合并
all_data = pd.concat([data,pd.DataFrame(cluster_labels_kmeans)],axis=1) all_data.rename({0:'clusters'},axis=1,inplace=True) all_data
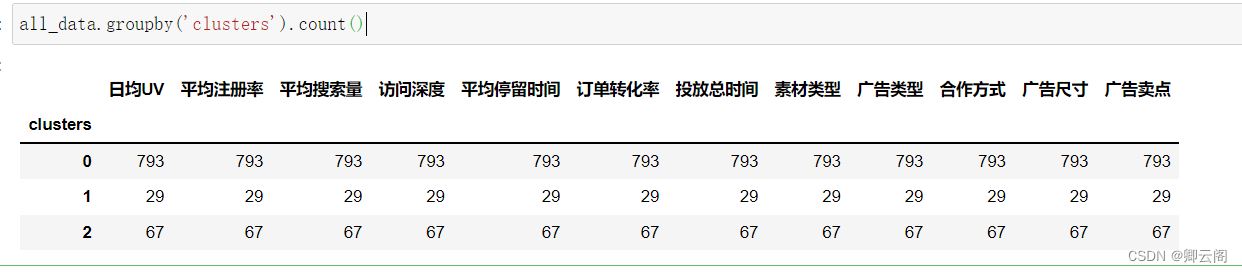
查看每个簇有多少样本,与其中的众数
all_data.groupby('clusters').count()
all_data.groupby('clusters').agg(lambda x: x.value_counts().index[0]).reset_index()
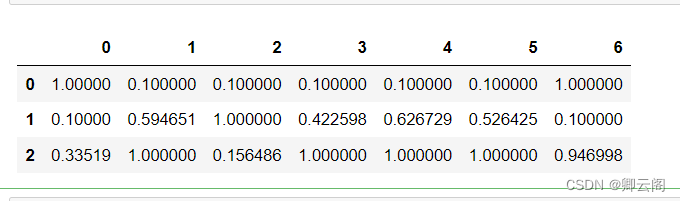
求出各个簇的平均值
a = all_data.groupby('clusters').mean() a = pd.DataFrame(MinMaxScaler(feature_range=(0.1,1)).fit_transform(a)) a
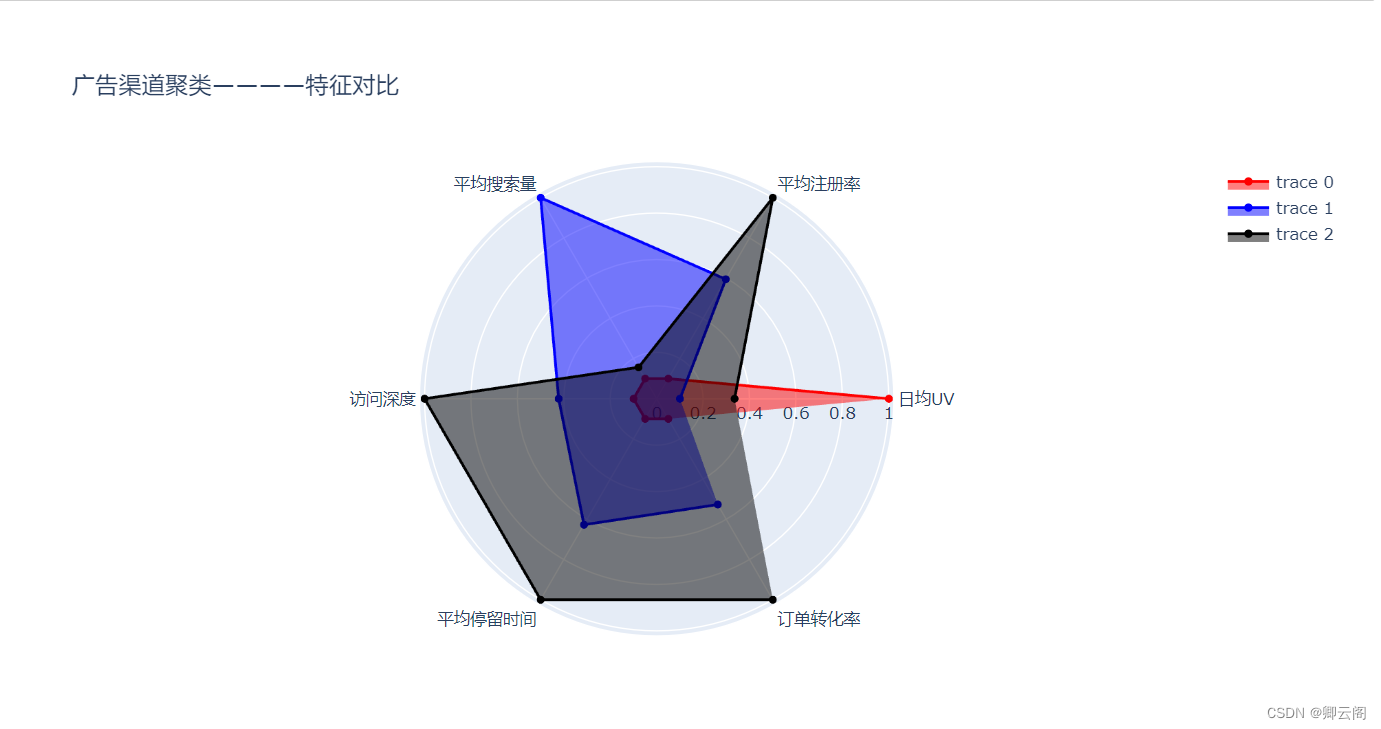
这里我是用的是plotly画图。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plotlyimport plotly.express as px import plotly.graph_objects as go colors = ['red','blue','black','green','white','pink','darkviolet','yellow','firebrick'] theta = ['日均UV','平均注册率','平均搜索量','访问深度','平均停留时间','订单转化率'] fig = go.Figure() for i in a.index: fig.add_trace(go.Scatterpolargl(mode='lines+markers', r = a.iloc[i,:6], theta = theta, line_color = colors[i], fill = 'toself' )) fig.update_layout(title='广告渠道聚类————特征对比') fig.show()
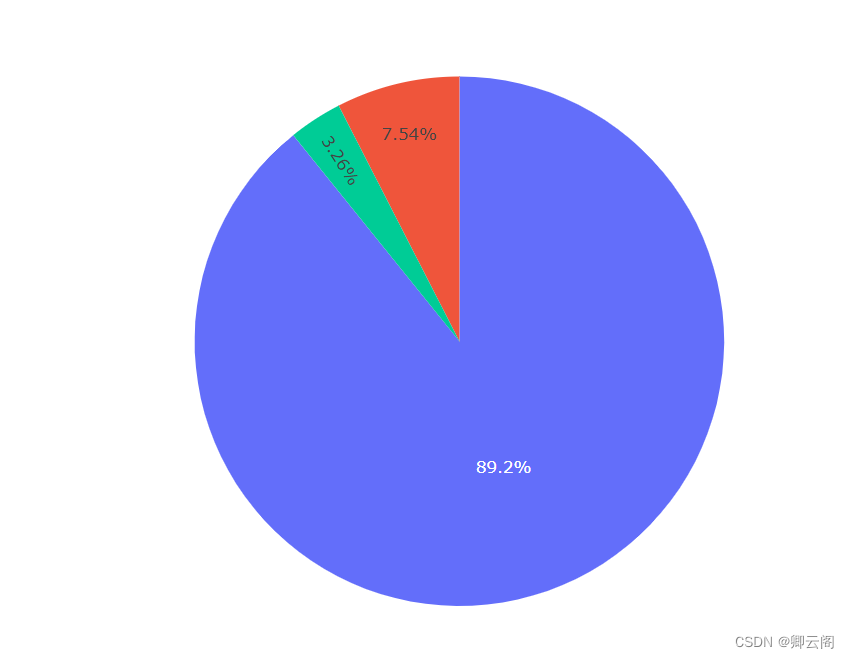
fig = px.pie(all_data.groupby('clusters').count(),values='日均UV') fig.show()
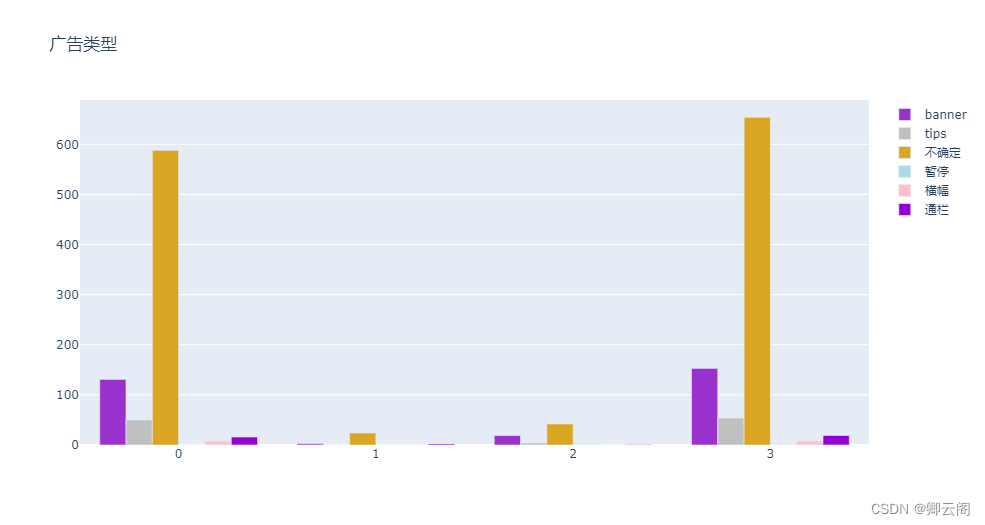
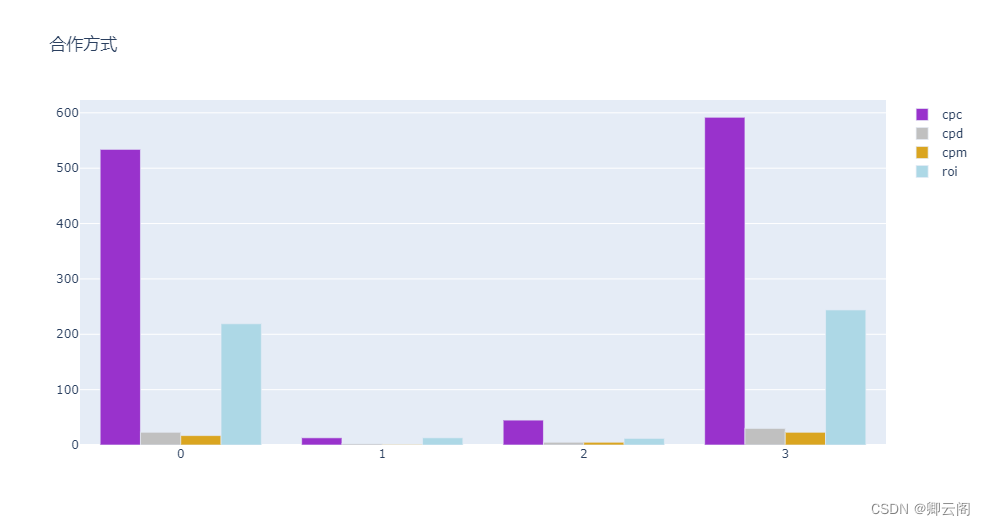
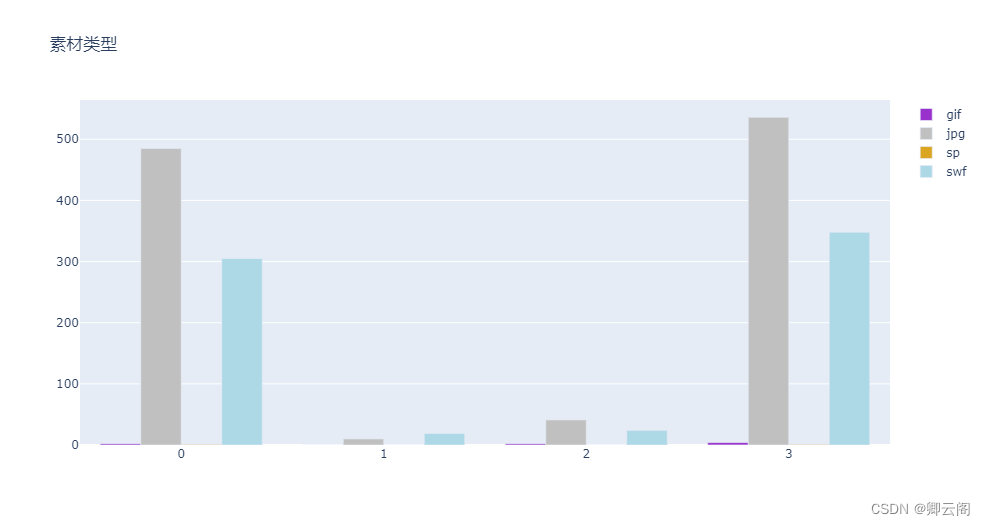
clusters = ['0','1','2','3','4'] for o in range(7,12): fig = go.Figure() cross_tab = pd.crosstab(all_data.iloc[:,-1],all_data.iloc[:,o]) l = pd.DataFrame(cross_tab.sum()).T cross_tab=cross_tab.append(l) cross_tab.index = [0,1,2,3] colors = ['darkorchid','silver','goldenrod','lightblue','pink','darkviolet','yellow','firebrick'] for i in range(len(cross_tab.T)): fig.add_trace(go.Bar( x=clusters, y=cross_tab.iloc[:,i], name=cross_tab.columns[i], marker_color=colors[i], )) # Here we modify the tickangle of the xaxis, resulting in rotated labels. fig.update_layout(title=all_data.columns[o]) fig.show()




















 3396
3396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











