






🌞欢迎来到数据结构的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
串的定义和基本操作
这里我们需要掌握几个概念,串,串名,串长,子串,主串,字符在主串中的位置,子串在主串中的位置(从1开始的),空串,空格串(每个空格字符占1B)。比如S1=”I am a student” S2=”student” 子串S2在S1中的位置是8。
普通的线性表存放的数据类型是不限制的,而串存放的一般是字符,比如中文字符,英文字符,串的操作对象一般是子串。比如搜索引擎中我们一般输入的是字符串。

a在字母表中的位置是小于o的,但是对于计算机来说,字符在计算机中的存储是二进制,这就涉及到字符集编码的问题。我们的计算机只能存储二进制,所以需要确定一个编码的规则,使得字符和二进制数一一对应,比如我们常见的ASCII,比如a(0110 0001),c(01100011),因为c的二进制编码大于a,所以a<c,空格实际上也是用二进制表示的。什么是字符集?,集可以理解成集合的意思,比如英文字符。不同的国家都会有自己的各自的字符(比如我们中文里面的一个汉字就是一个字符,显然8个比特位(256个状态)无法表示出那么多的中文字符(好几万个),所以就有了(Unicode字符集),对于同一个字符集可能存在着好多种编码方案(UTF-8,UTF-16),可以把字符集理解成定义域,编码方案相当于函数。
产生乱码问题的原因在于,软件的解码方式出现了问题,比如在存储我们文件的时候使用了一套编码规则,把字符映射成了对应的二进制数,但是我们用另一个软件打开这个文本文件时,软件就会以为我们使用的是另一个编码规则。
串的存储结构
顺序存储查找很简单,但是插入和删除非常麻烦,不同的教材实现的方式可能会有区别,我们之前的代码是使用顺序表的方式,我们还可以采用方案二,用ch[0]来记录当前的长度,这样字符的位序和数组下标相等,方案三以字符’\0’表示结尾 (对应ASCII码的 0)缺点是长度需要遍历来获得,采用第二种方式时虽然可以节省1B的大小,但是length变量的类型是char,占(1B)(表示的范围0-255)。所以这种方式的缺点就是字符串的长度不能超过255,综上,我们一般使用的是方案4,舍弃一个位置,定义一个int 类型的变量,用来表示字符串的长度。

代码实现: #define MAXLEN 255 typedef struct{ char [MAXLEN]; int length; }SString;
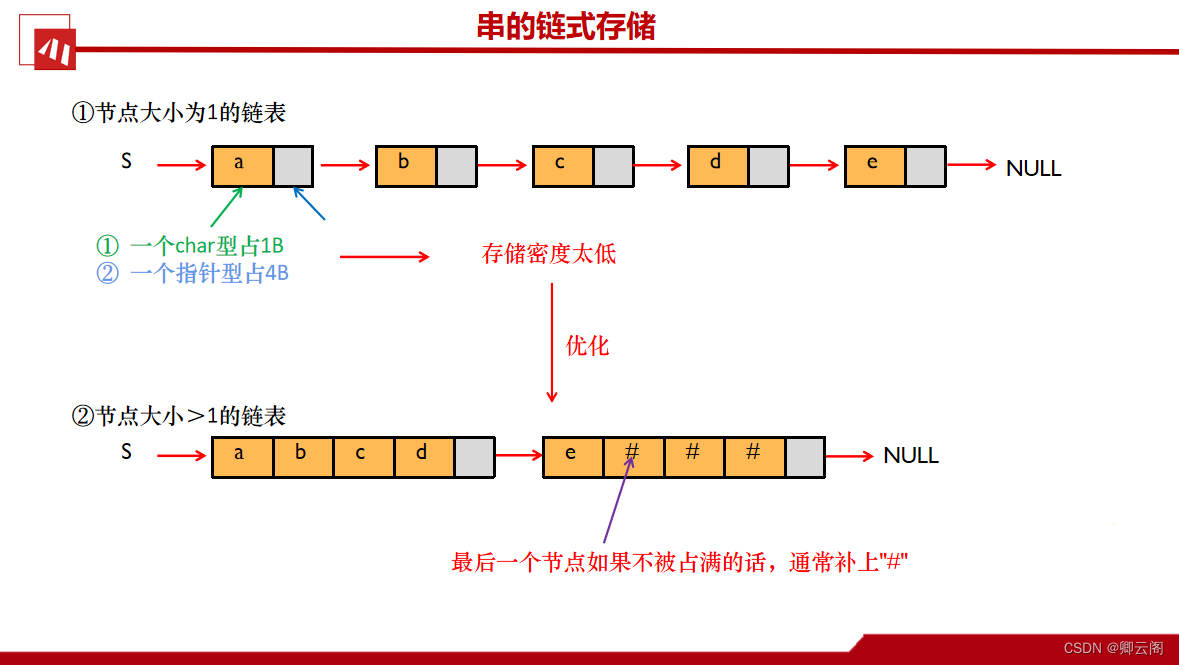
串的链式存储和基本实现
我们可以用(char ch)来存储一个字符(占1B),但是在32位的系统中(Struct SString *)这样的一个指针类型,一般占4B,这就存在一个问题,我们只需要1B来存放我们的字符信息,却需要用4B来存放辅助信息,这就存在存储密度低的问题,所以这里我们可以在一个节点里,存放多个字符,还有一个细节是如果最后一个节点,放不满,可以用一些特殊的字符代替(插入删除简单,不能随机读取)。
typedef struct StringNode() { char ch[4]; struct StringNode *next; }StringNode,*String;
串的基本操作
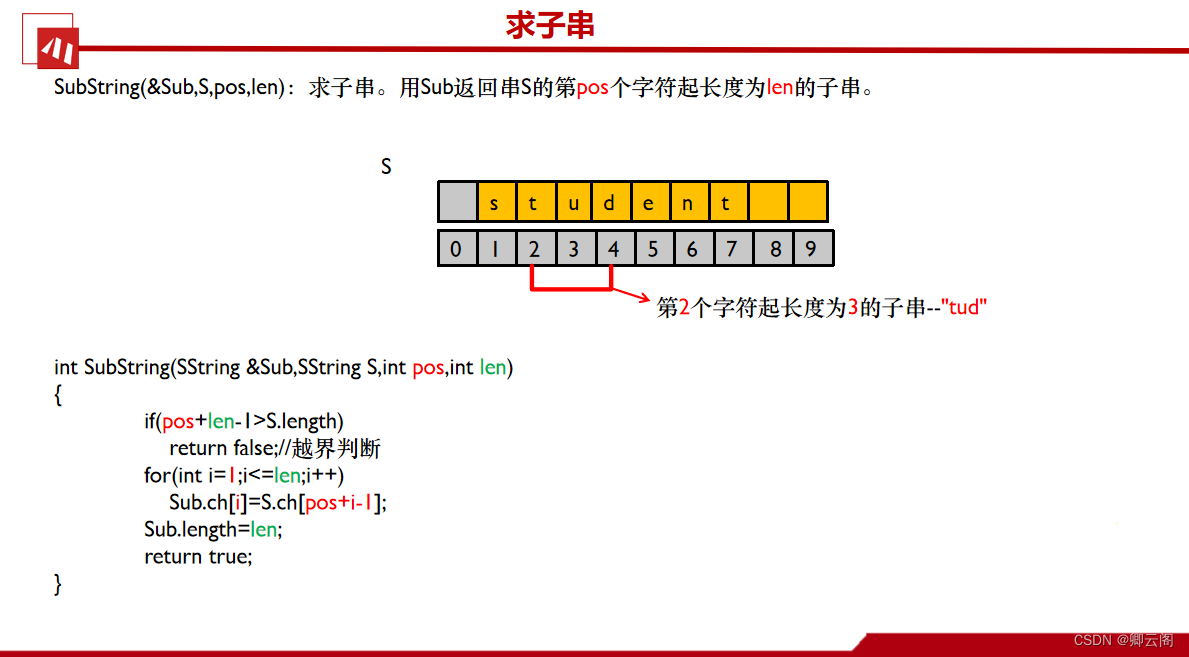
SubString函数是求子串的函数,用Sub返回主串S从第pos个字符开始,长度为len的子串。对应的S的数组下标,应该是pos-pos+len-1,,对应的Sub的数组下标,应该是1-len,现在需要找对应的关系。
Sub[1]=S[pos]
Sub[2]=S[pos+1]
Sub[i]=S[pos+i-1]
当然还需要考虑,越界的情况:pos+len-1代表能满足子串的最短的主串长度。
StrCompare(S,T)比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。遍历从1开始到两个串的最小的长度结束,以此比较两个串相同位置的元素,如果循环结束,说明扫描过的所有字符相同,长度大的串大。
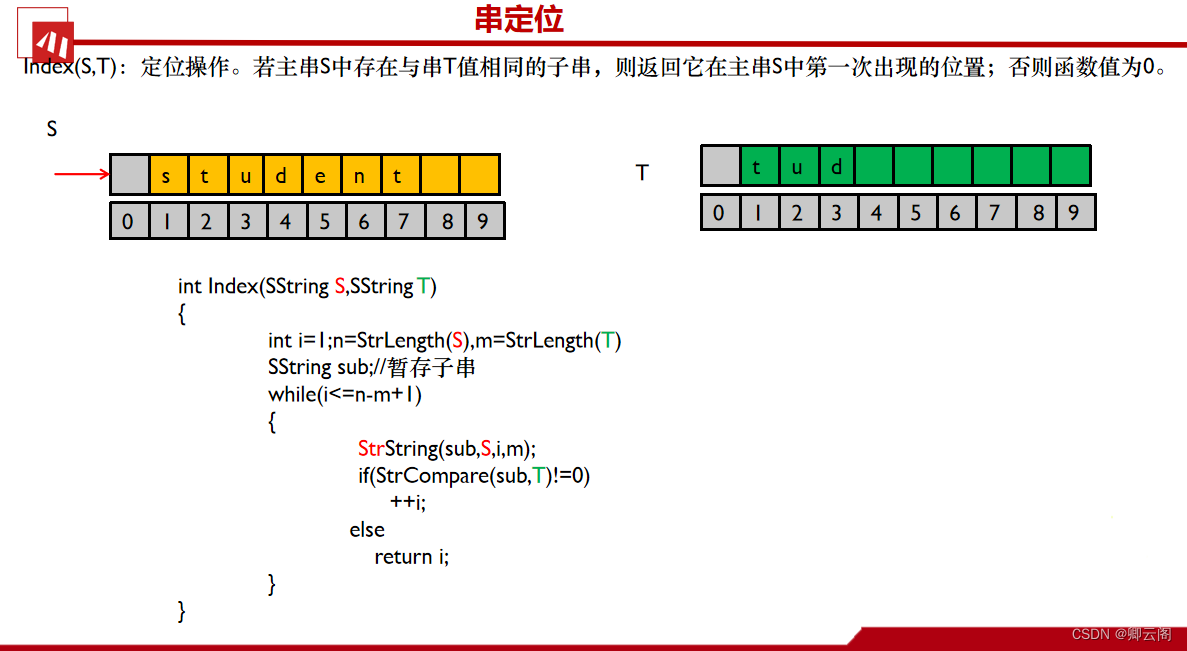
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。求串S的长度为n,串T的长度为m,依次求从第1到n-m+1位置开始,串S的子串。然后与T进行比较如果不相等,继续循环遍历,如果相等,结束并返回位置。
朴素模式匹配算法
串的模式匹配:在主串中找到与模式串相同的子串,并返回其所在位置。子串是主串的一部分,一定存在,模式串不一定在主串中找到,注意子串、主串、模式串。
如果主串的长度为n,模式串的长度为m,将主串中所有长度为m的子串依次与模式串对比,直到找到一个完全匹配的子串(返回其位置),或者所有的子串都不匹配为止。
在长度为n的主串中,长度为m的子串最多有n-m+1个。我们可以发现朴素模式匹配算法和上面的串的定位操作(Index一样)。上面我们的实现是通过SubString和StrCompare操作实现的,下面我们使用数组下标来实现。
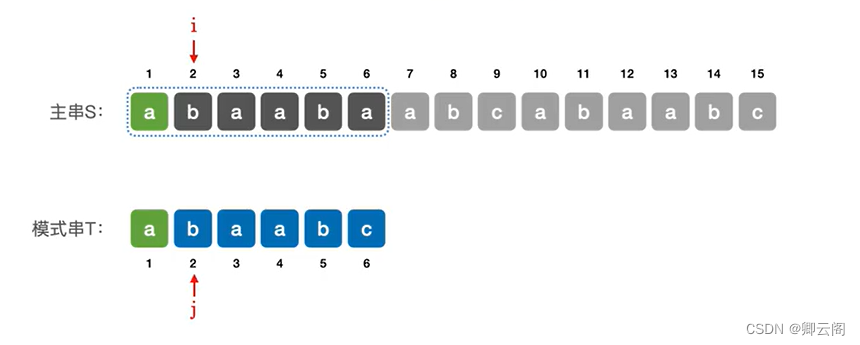
设置两个扫描指针i和j这两个指针指到哪里,就对比到哪里。
所以一开始时要对比主串的第1个字符和模式串的第1个字符,如果这两个字符相等就让i和j分别后移。
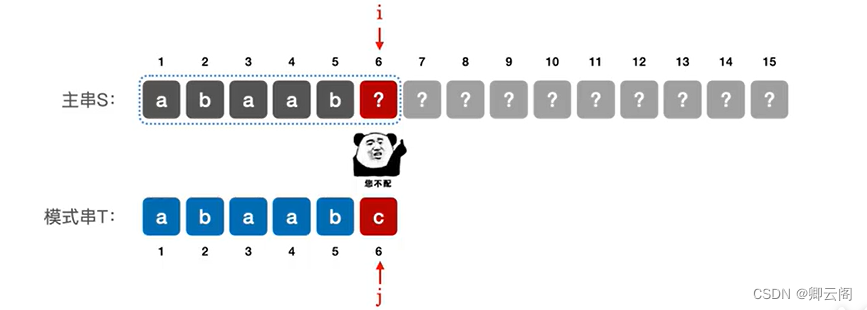
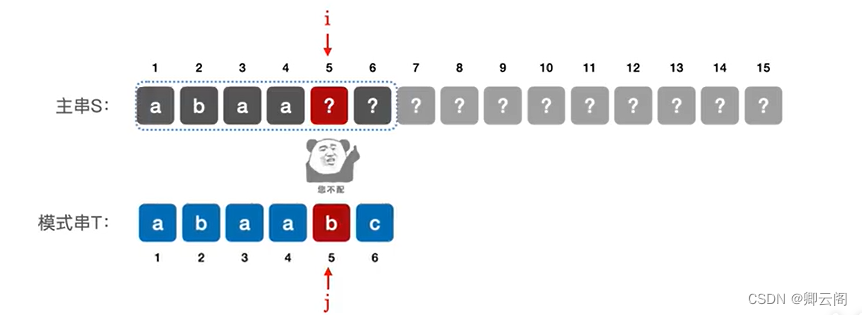
发现此时i和j指向的字符依然是相等的,所以i和j继续向后移,直到i和j的指向的值不相等的时候,说明匹配失败。(此时i=j=6)说明第一个子串和模式串匹配失败。
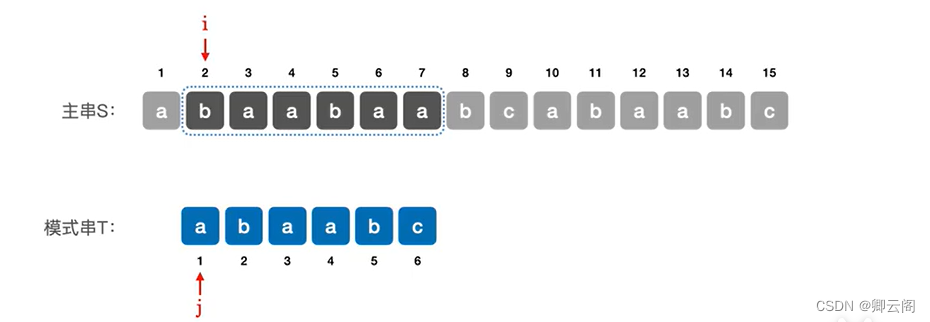
下面看第二个模式串。第二个子串的起始位置应该是2这个位置,如当前的子串匹配失败,则主串指针i指向下一个子串的第一个位置,模式串指针j回到模式串的第一个位置。j的当前位置说明我们匹配到了子串的第几个字符,i-j可以让i指针回到目前子串的前一个位置,+2指向下一个子串的起始位置。
此时i=2,j=1,下面匹配第二个子串,发现此时匹配失败。
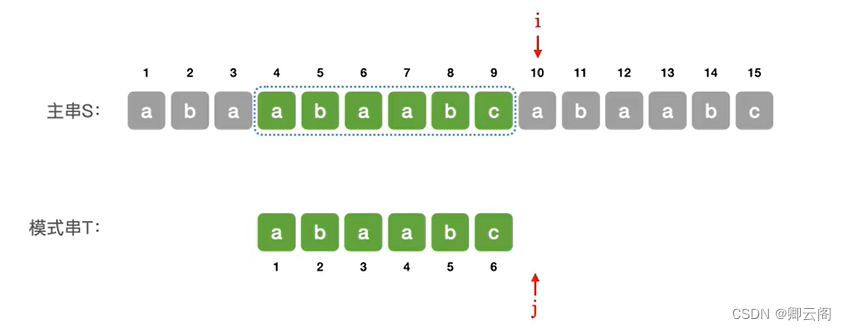
进行第3个子串的匹配,当i=4,j=2的时候匹配失败。
进行第4个子串的匹配 ,此时j所指向的位置已经超过了模式串的长度,说明子串匹配成功返回当前子串前一个字符的位置。(i-T.Length)
朴素模式匹配算法的代码实现
思路:一次操作-如果i和j指向的字符相等,继续比较,如果不相等,i指针指向下一个要比较的字符,j指针指向模式串的第一个字符。其中i,j的值要小于当前串的长度。这个循环结束之后,如果,j的值大于当前模式串的长度,说明匹配成功,返回,在主串中的位置。(i-T.Length)。
int Index(SString S,SString T) { int i=1; int j=1; while(i<=S.Length&&j<=T.Length) { if(S.[i]==T.[j]) { ++i; ++j; } else { i=i-j+2; j=1; } } if(j>T.Length) return i-T.Length; else return 0; }朴素模式匹配算法性能分析
匹配成功的最好时间复杂度:O(m)
若模式串长度为m,主串长度为n,则直到匹配成功/匹配失败最多需要 (n-m+1)*m 次比较最坏时间复杂度:O(nm)
很多时候n>>>>m,最坏的情况每个子串都要对比m个字符,一共有n-m+1个子串,要 (n-m+1)*m 次比较。
KMP算法
现在我们先回顾一下,朴素模式匹配算法的算法思路,就是我们会把主串中所有和模式串长度相同的子串依次和模式串进行对比,直到找到第一个完全匹配的为止,一旦发现当前这个子串中某个字符不匹配,就匹配下一个子串。(为什么要从头开始匹配第二个子串呐,因为我们在主串中的这些字符到底是什么我们并不知道,所以只能从子串的第一个字符依次的往后进行匹配。
现在我们开始换个思路来分析这个问题,如果第一个子串匹配到最后一个字符才发现匹配失败,那么子串前面的字符一定是和模式串对应的(不匹配的字符之前,一定是和模式串一致的)通过模式串的部分匹配,我们知道子串前面几个元素是什么。
根据朴素模式匹配算法的思想,匹配失败后,我们只能匹配下一个子串,但是现在我们已经知道了这个子串前面几个字符的信息,我们发现第2个子串的第一个字符已经和模式串不匹配。所以当前子串不需要再进行检测和匹配。可以直接跳过。
下一个子串,现在这个子串我们也知道它前面几个元素的信息,第一个字符匹配,第二个字符不匹配,所以这个子串也没有必要进行检查。
然后我们再看下一个子串现在这个子串同样的,我们知道它头部的几个字符的信息,第2个,第2个可以和模式串进行匹配,第3个字符是什么确不知道,所以我们可以从第3个位置开始向后匹配。
我们再来梳理一下我们的思路,当我们匹配到某一个字符发生失配的时候,这个字符之前的主串的信息,我们是可以确定的,和模式串是保持一致的,这个时候我们就没有必要检查,第2个元素开头的子串(因为b和a已经不匹配了),也没有必要检查第3个元素开头的子串。
而是可以直接开始对比第4个元素开头的那个子串,并且对于这个子串来说,我们也没有必要对比第一个元素和第二个元素,因为我们可以确定这两个元素一定是可以和模式串匹配的,现在暂时还不能确定的是模式串的第三个元素,和主串中刚才失配的那个元素,是否可以匹配,因此当第6个元素匹配失败时,可令主串指针i不变,模式串指针j=3。从模式串的第三个元素开始向后匹配。在这个过程中,我们跳过了几个子串的对比,也跳过了第4个元素开头的那个子串开头两个元素的对比。
我们再来验证一下,假设i从主串的第5个元素开始匹配,同样我们匹配到最后一个元素的时候发现元素失配,因此当第6个元素匹配失败时,可令主串指针i不变,模式串指针j=3。从模式串的第三个元素开始向后匹配。主串说明了这个结论具有通用性,模式串指针j下一个元素的位置,只与模式串有关。目前我们探讨的是第6个元素发生失配的时候应该怎么做,
如果是第5个元素发生失配了,应该怎么做?此时前面的4个元素要保持一致,第2子串也无法匹配(第1元素就匹配失败),第3子串也无法匹配(第2个元素就匹配失败)。
第4子串已知信息可以匹配,结论模式串j=2。
同理可以得到第4个元素匹配失败时,结论模式串j=2。第3个元素匹配失败时,结论模式串j=1。第2个元素匹配失败时,结论模式串j=1。第1个元素匹配失败时刚才发,生失配时,我们都是让i保持不变,然后让j等于某一个值,为了代码的书写方便,我们可以先让j=0(指向模式串的第一个元素的前一个位置)可以先让j=0,然后i和j统一向后移动,继续对比后面的子串。
我们上面所说的逻辑如何用代码实习呐?其实我们上面分析模式串得到的结论可以用一个数组来表示这个信息,我们把这个数组称之为next数组,next数组指明了当我们在某一个位置发生失配的时候,j的值修改为多少,比较特殊的是当第一个元素失配时,j=0,i++,j++,用代码表示逻辑,首先,如果主串元素(S[i]!=T[j])不等于模式串元素,就修改(j=next[j]),比较特殊的是if(j==0) i++;j++。
时间复杂度
求next数组
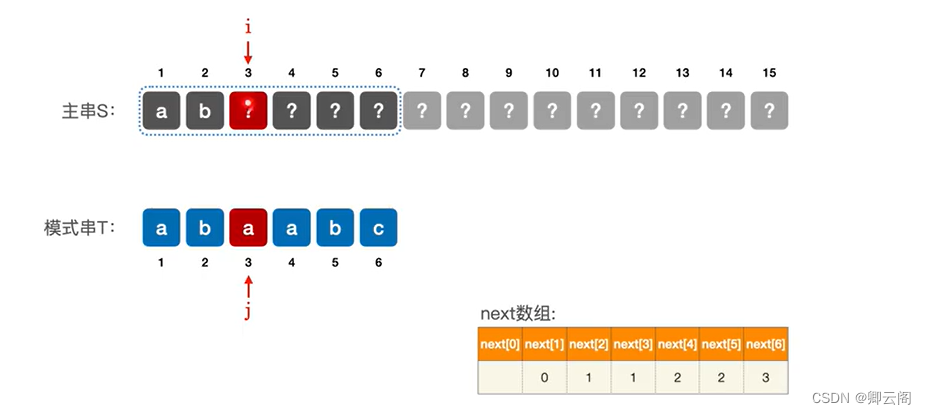
下面我们求下面这个主串的next数组,首先字符串的下标和next数组的下标是一一对应的,现在我们先求next[1];
next[2]=1
next[3]=1
next[4]=1
同理可以得到 next[5]=2, next[6]=1。
下面我们计算这个模式串的next数组:
KMP算法的优化
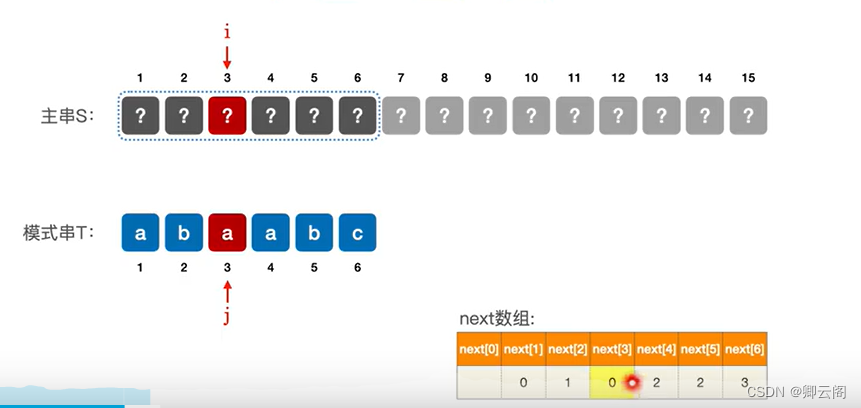
当模式串匹配到第3个字符的时候,出现不匹配,这个时候,next[3]=1,我们还可以进行如下的思考,第3个字符的时候,出现不匹配,说明主串S的第3个字符不是a,此时next[3]=1,也一定是失败的,此时next[1]=0。
接着我们回到前面这一步,j指针指向3这个位置的时候匹配失败,next[3]=1,下面要匹配第一个字符,但是我们有知道,第一个字符和第三个字符是相等的,所以第一个字符的匹配一定也是失败的,因此当第三个字符匹配失败的时候,我们完全可以让j等于0,(这样就可以跳过一步)。
下面我们再来一个例子,假设模式串匹配到5这个元素时发现匹配失败,在这种情况下next[5]=2,这又存在着一个问题,我们能知道S中的第5个元素的值一定不等于b,所以刚才让j指针指向2,这次匹配也一定是失败的,因为失配时的字符和j指针下一个指向的字符是一样的,匹配失败后next[1]=1,所以我们可以直接next[5]=1.
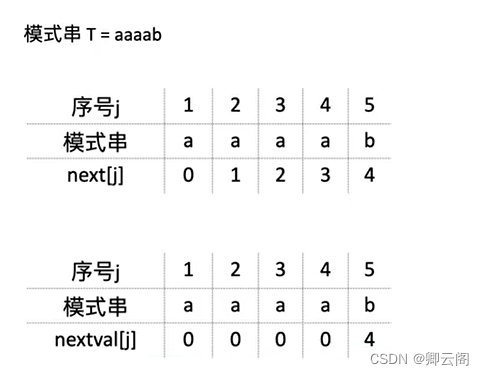
怎么求nextval数组?
首先nextval[1]=0;如果当前的next[j]指向的字符和当前j所指向的字符,他们俩不相等,我们就让nextval[j]=next[j],如果当前的next[j]指向的字符和当前j所指向的字符,他们俩相等,我们就让nextval[j]=nextval[next[j]]。




















































11-03
08-09
 149
149
149
09-03
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











