







🌞欢迎来到机器学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2024年11月17日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

数学基础
补充题目:奇异值分解
简单来说学习相似的目的就是为了矩阵分解,比如我现在一个机器学习的表格数据,可以把它看成是一个矩阵,一般我们会让这个矩阵乘以它的转置变成一个对称阵。对这个对称阵矩阵分解成n个同样大小的矩阵,特征值的大小代表对应矩阵的重要程度。(主成分分析)
矩阵的相似对角化
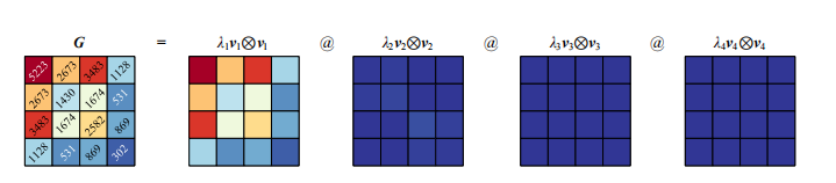
实对称矩阵的相似对角化
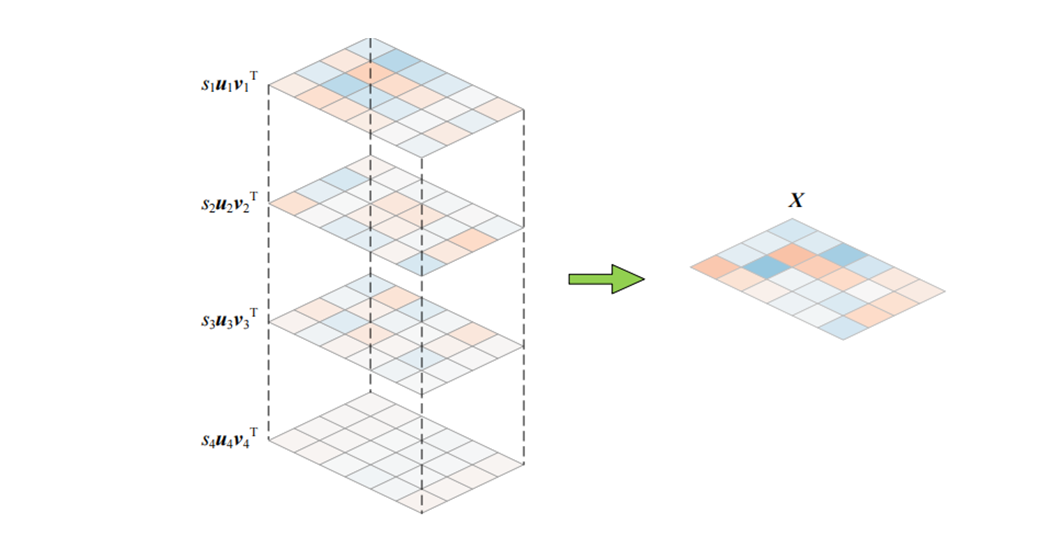
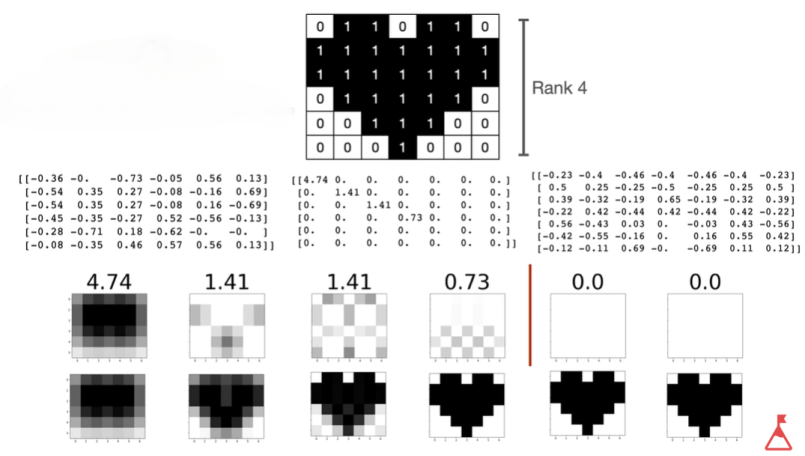
普通矩阵的分解(奇异值分解)
但是一张照片不太可能是一个方阵,如何把它压缩存贮呐?中间是奇异值矩阵,奇异值越大表示和原来的照片越相似。
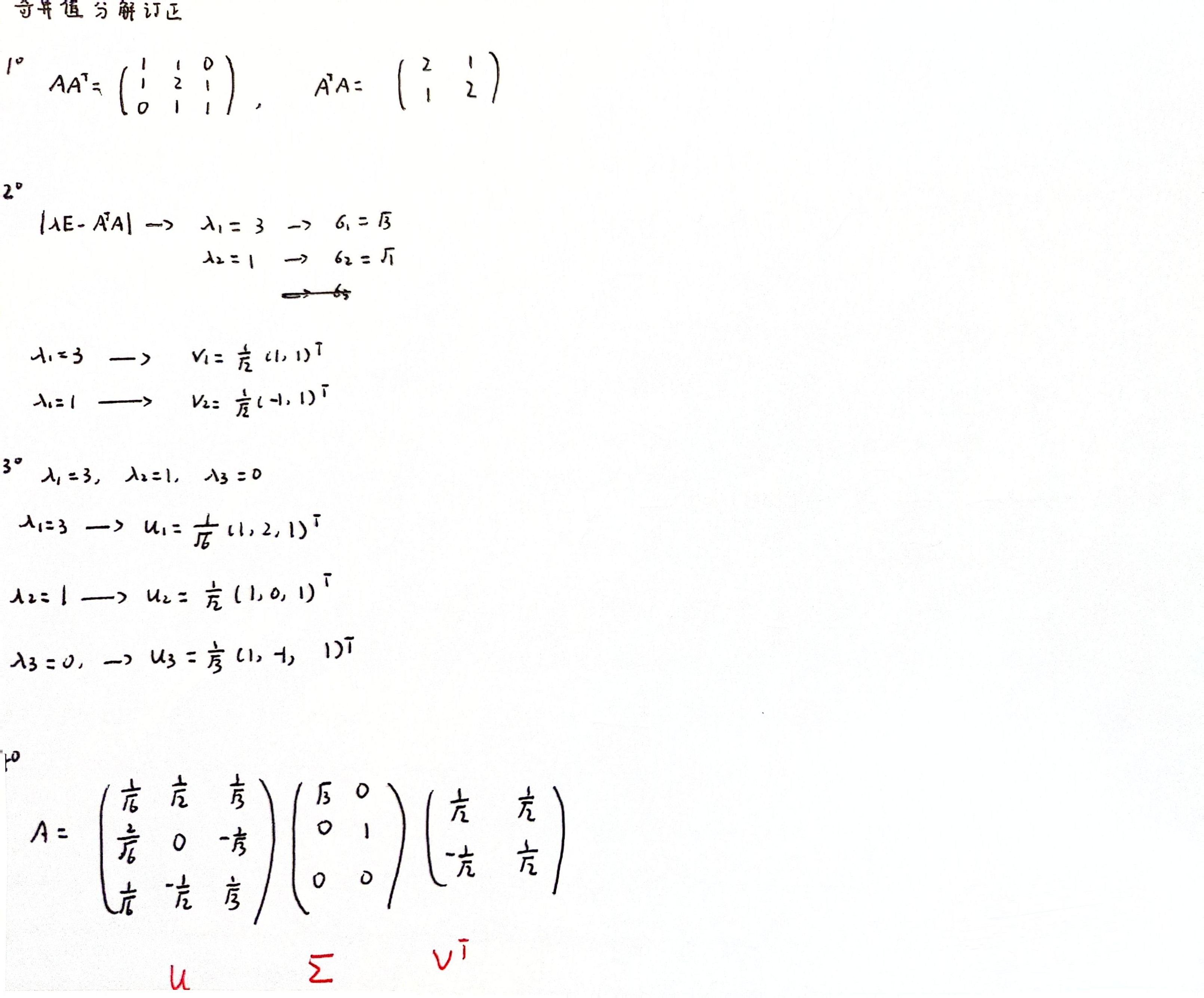
【1】已知在所有男子与女子中分别有 5% 与 0.25% 的人患有色盲症。假设男女的比例为 1:1。现在随机抽查一人发现其患有色盲症,计算其为男子的概率。

【2】(三门问题)有三扇关闭的门,其中一扇门的后面有辆跑车,而另外两扇门的后面各藏有一只山羊,跑车在哪一扇门的后面是完全随机的。参赛者需要从中选择一扇门,如果参赛者选中后面有车的那扇门就可以赢得这辆跑车。参赛者随机选定了一扇门,但未去开启它的时候,节目主持人会开启剩下两扇门的其中一扇,其门后是一只山羊。此时参赛者是否应该保持他的原来选择,还是应该转而选择剩下的那一道门?



【注意:】第7题的订正

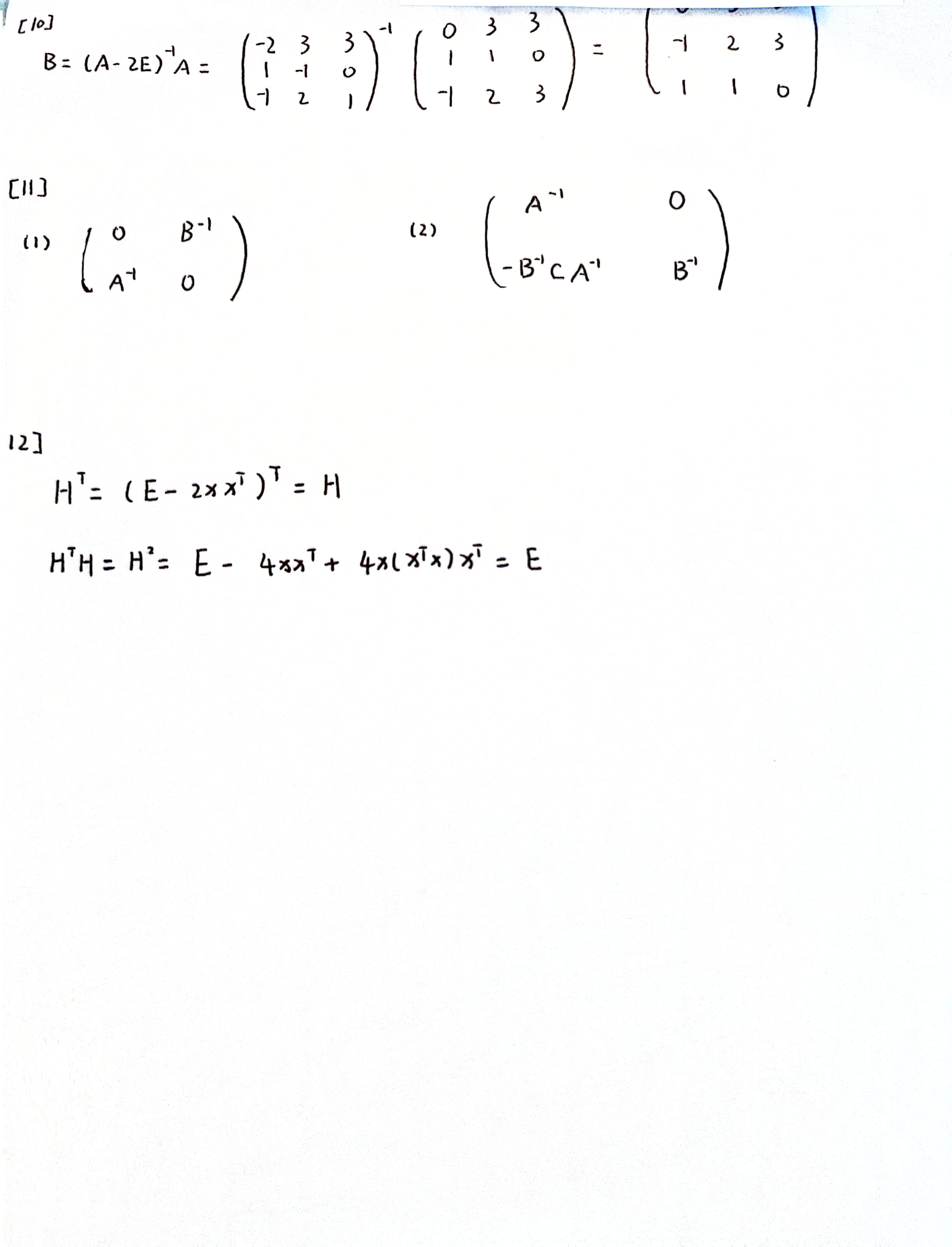
机器学习
机器学习的步骤
训练集:模型训练
验证集:参数选择
测试集:模型评估
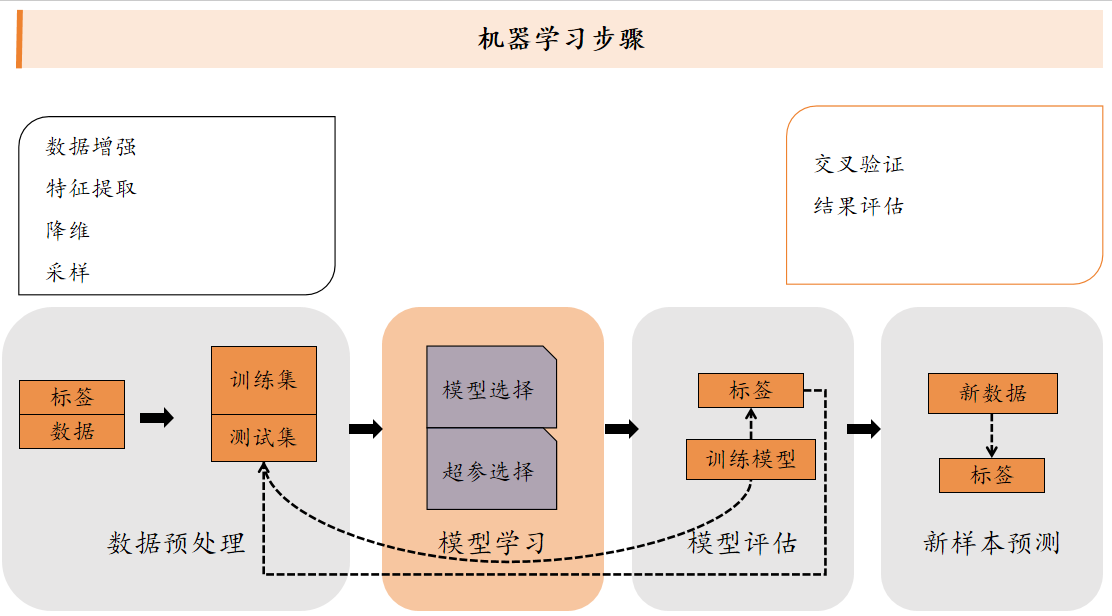
机器学习的分类
性能评价指标

评估方法
留出法
交叉验证法(交叉调优法)
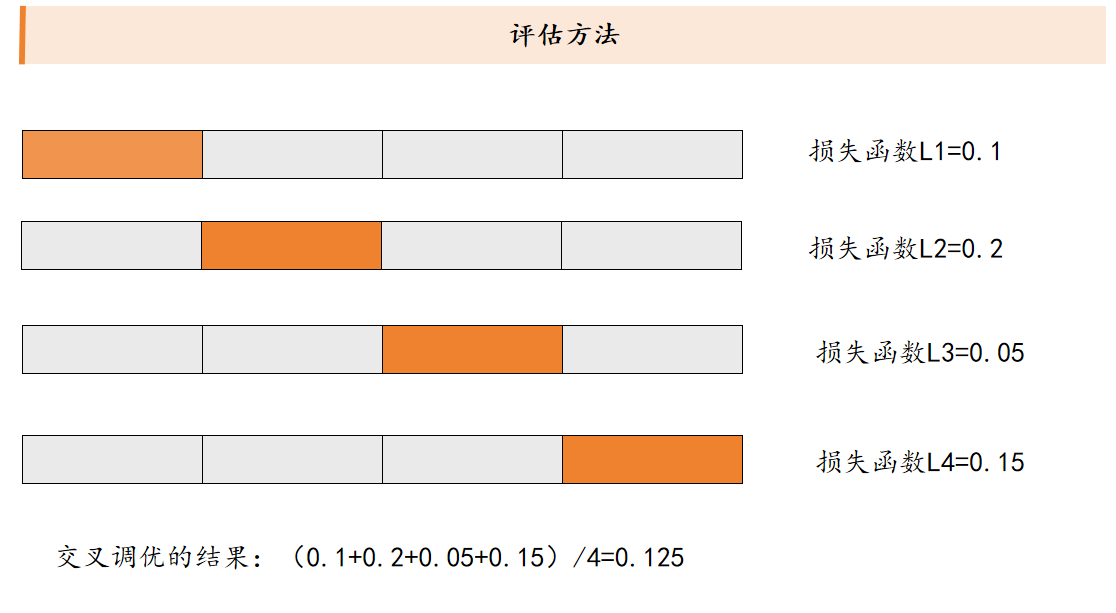
基本的名词:
优化:使得目标函数在见过的数据上表现的好。
泛化:使得目标函数在没见过的数据上表现的好。
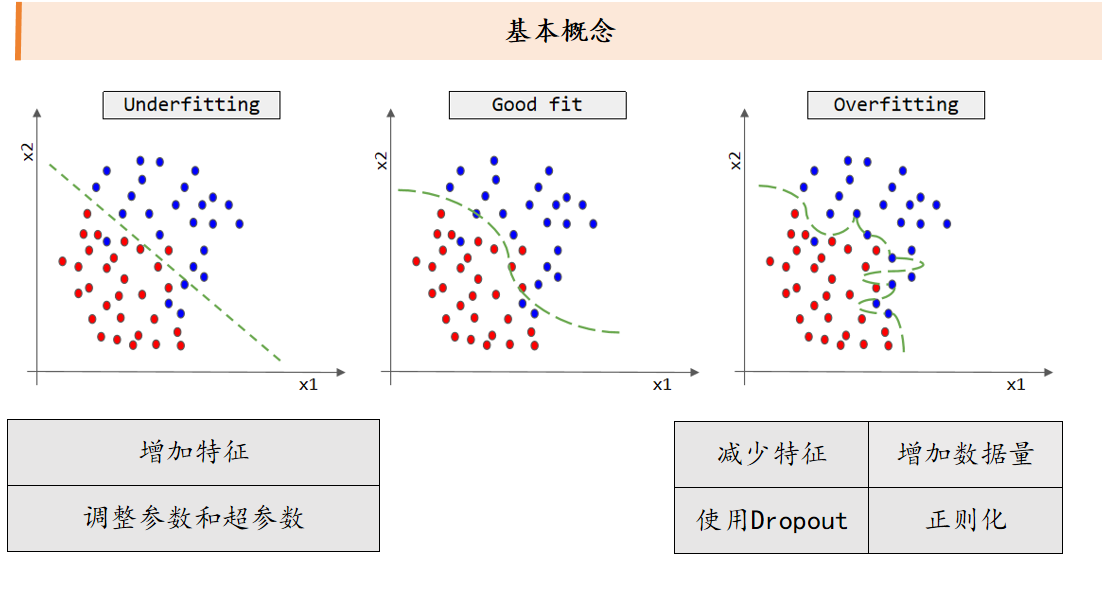
过拟合:函数表达能力过强,使得目标函数在训练集上的损失很小,在验证集上的损失很大。
解决方法:减少特征,增加数据量,使用Dropout,正则化。
欠拟合:函数表达能力过弱,使得目标函数在训练集和验证集上的损失都很大。
解决方法:增加特征,调整参数和超参数。
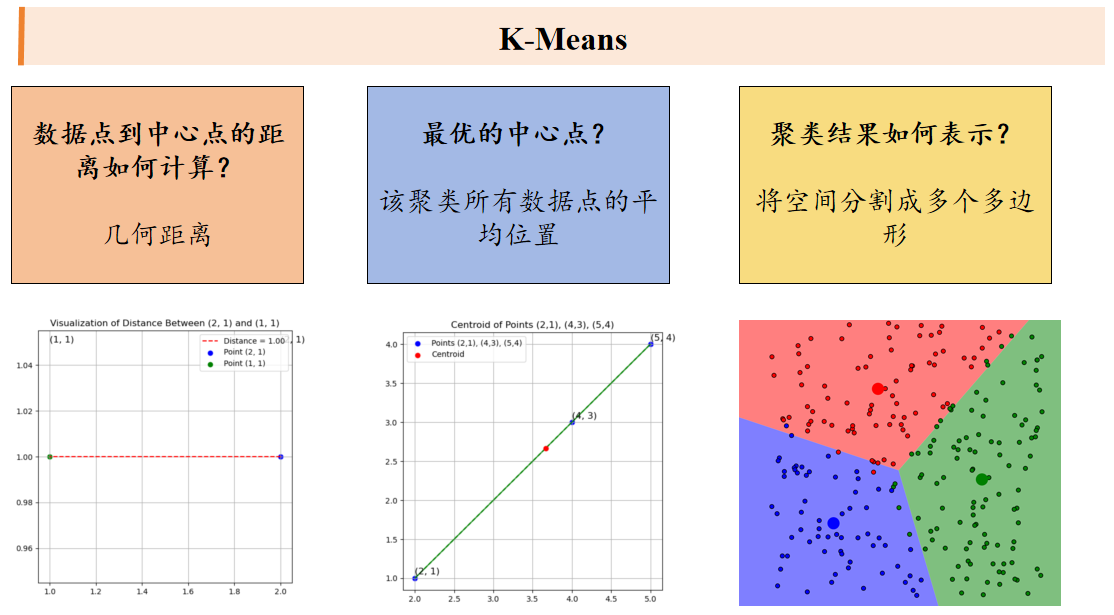
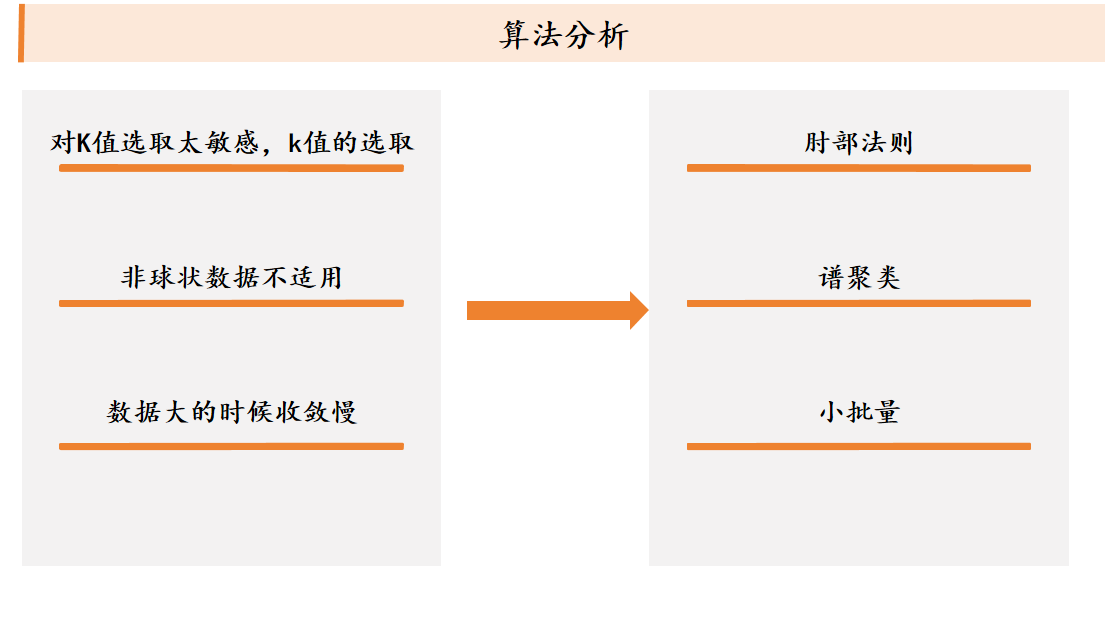
聚类算法
k平均算法:随机选取K个中心点,不断根据中心点的位置调整聚类分配方案,直到收敛。
谱聚类:构建无向图,降维聚类。

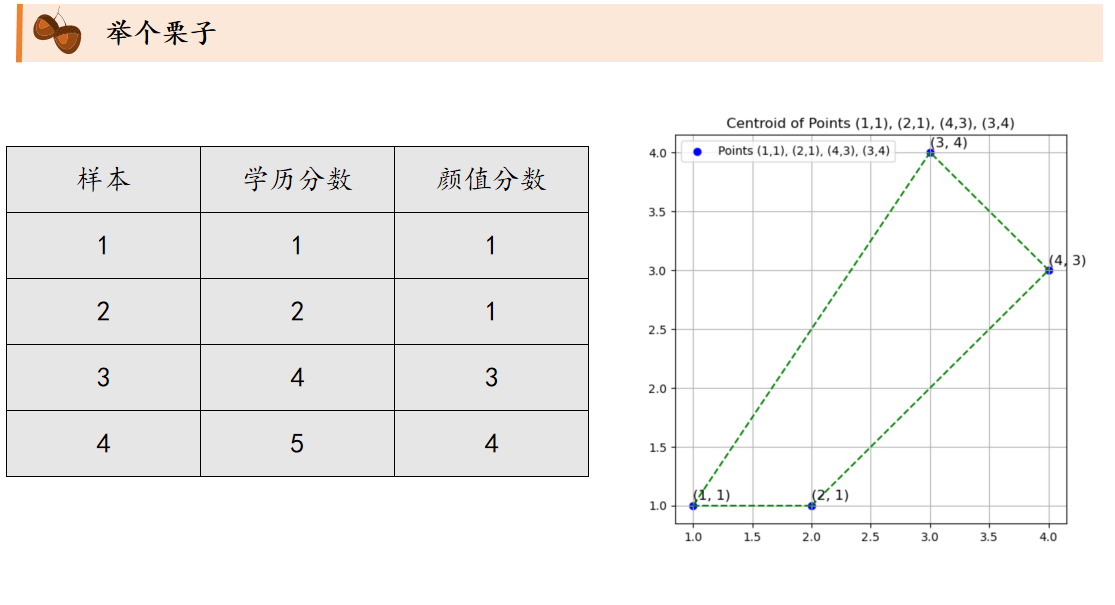
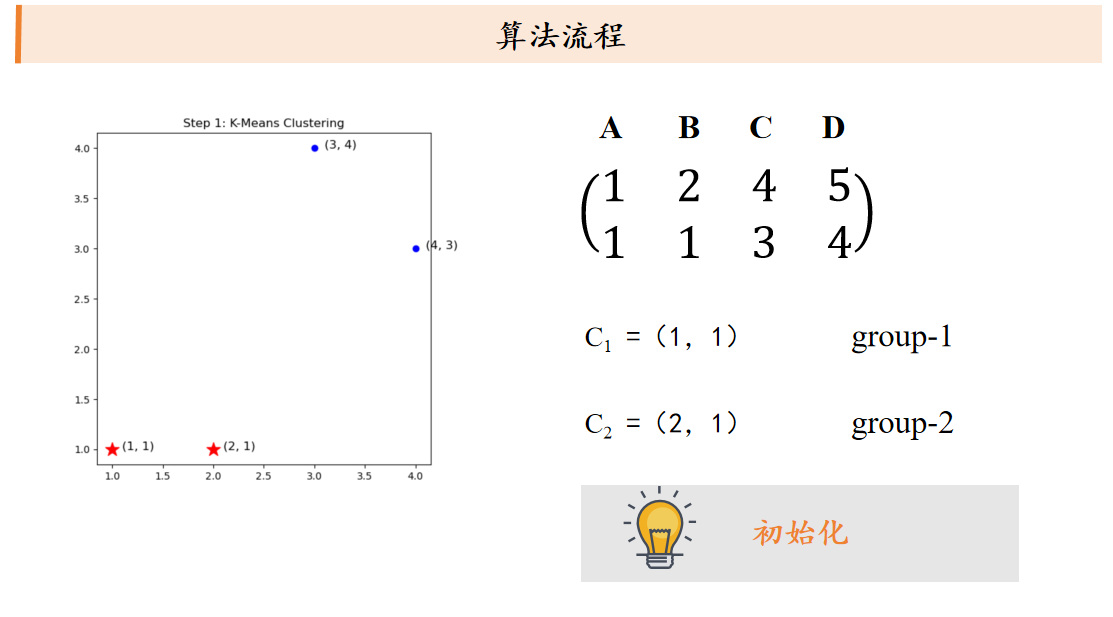
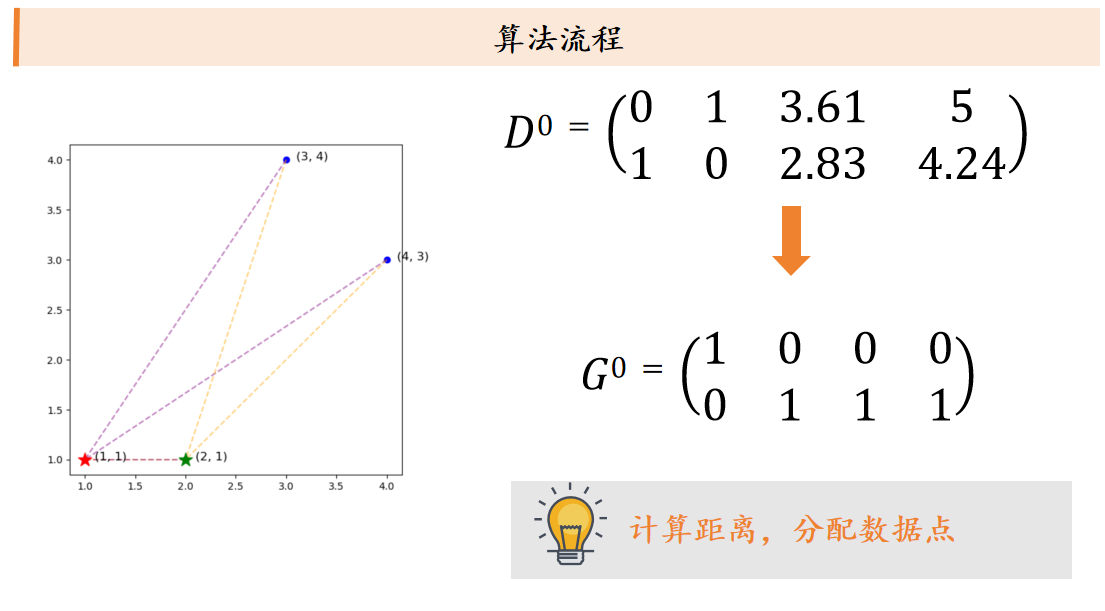
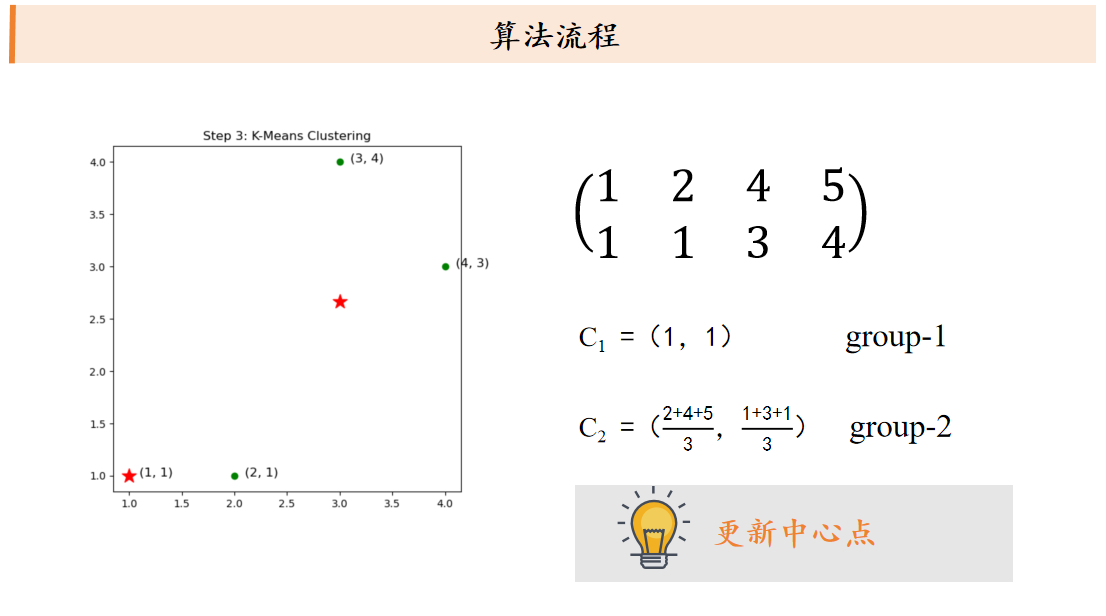
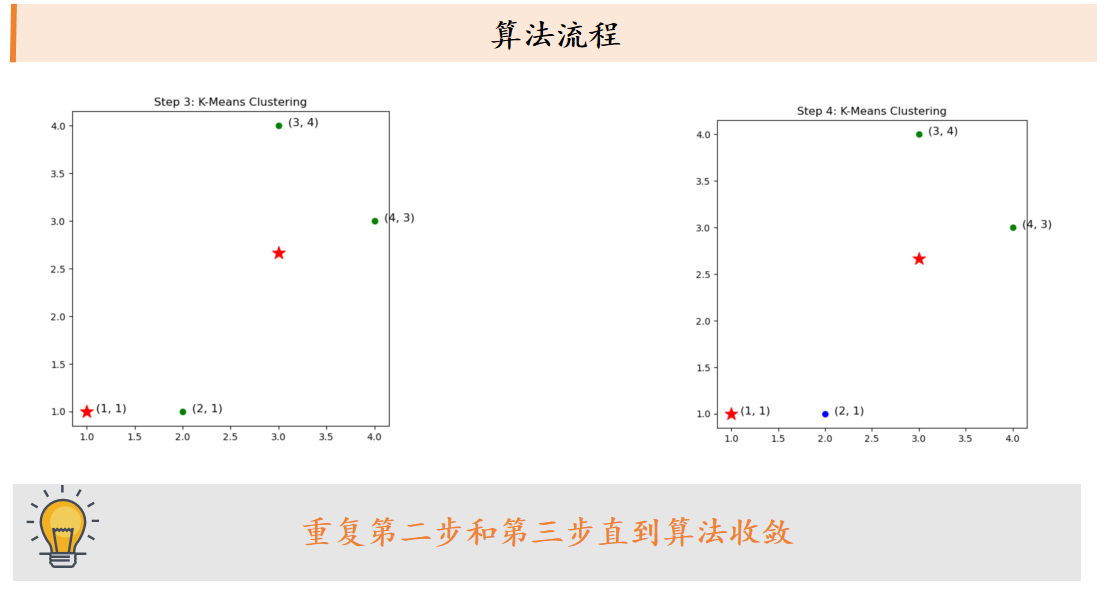
课后习题:
【1】监督学习的输人为 X,输出为 Y,我们的目标是学习一个函数 f。请举一些现实生活中的例子,说明 X 和 Y 可以是什么?对于给定的 X 和 Y,是否存在唯一的最优解 f?
答:X 和 Y 可以是各种各样的内容,比如图片、声音等,对于给定的 X 和 Y,可能会有多个最优解。
【2】请尝试区分 “优化” 和 “泛化” 两个概念。
答:优化是让 f 在见过的数据上表现好;泛化是指 f 在没有见过的数据上表现也好。
【3】请区分过拟合和欠拟合。
答:函数表达能力过强,使得机器学习算法在训练集上的损失很小,但是在测试数据集上的损失很大,叫过拟合;函数表达能力过弱,使得机器学习算法在训练集上和测试集上的损失都很大,叫欠拟合。
【4】除了本章介绍的损失函数外,你觉得还有什么函数能作为损失函数?L (f,x,y') = f (x)+y' 是一个好的损失函数吗?为什么?
答:本题为开放题,答案可以有绝对值函数、立方函数、交叉函数等。L (f,x,y') = f (x)+y' 不是一个好的损失函数,因为当 f (x)=y' 的时候损失函数取值不一定更小,所以无法指导我们寻找更好的 f 函数。
【5】请计算以下一维无监督分类问题,已知数据点为 1,2,3,6,7,9,请随机选择初始点,利用欧氏距离作为距离函数使用 Kmeans 算法计算二分类问题。
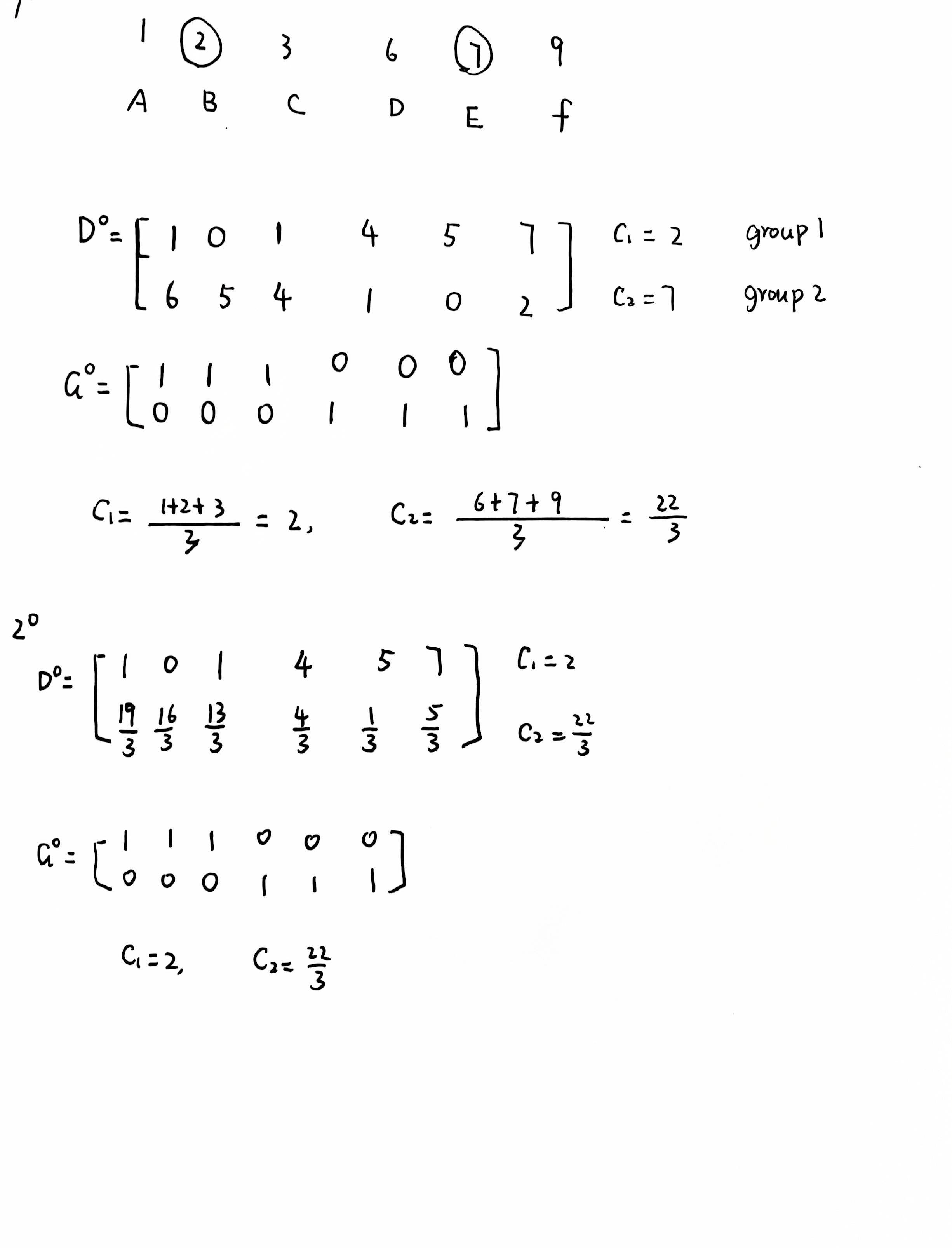
答:最终的中心点与类别的数据点为 (2:1,2,3),(7.5:6,7,9)。
【6】请计算以下二维无监督分类问题,已知数据点为 (0,0),(2,0),(1,9),(3,1),(1,8),(5,请随机选择初始点,利用欧氏距离作为距离函数使用 Kmeans 算法计算三分类问题。
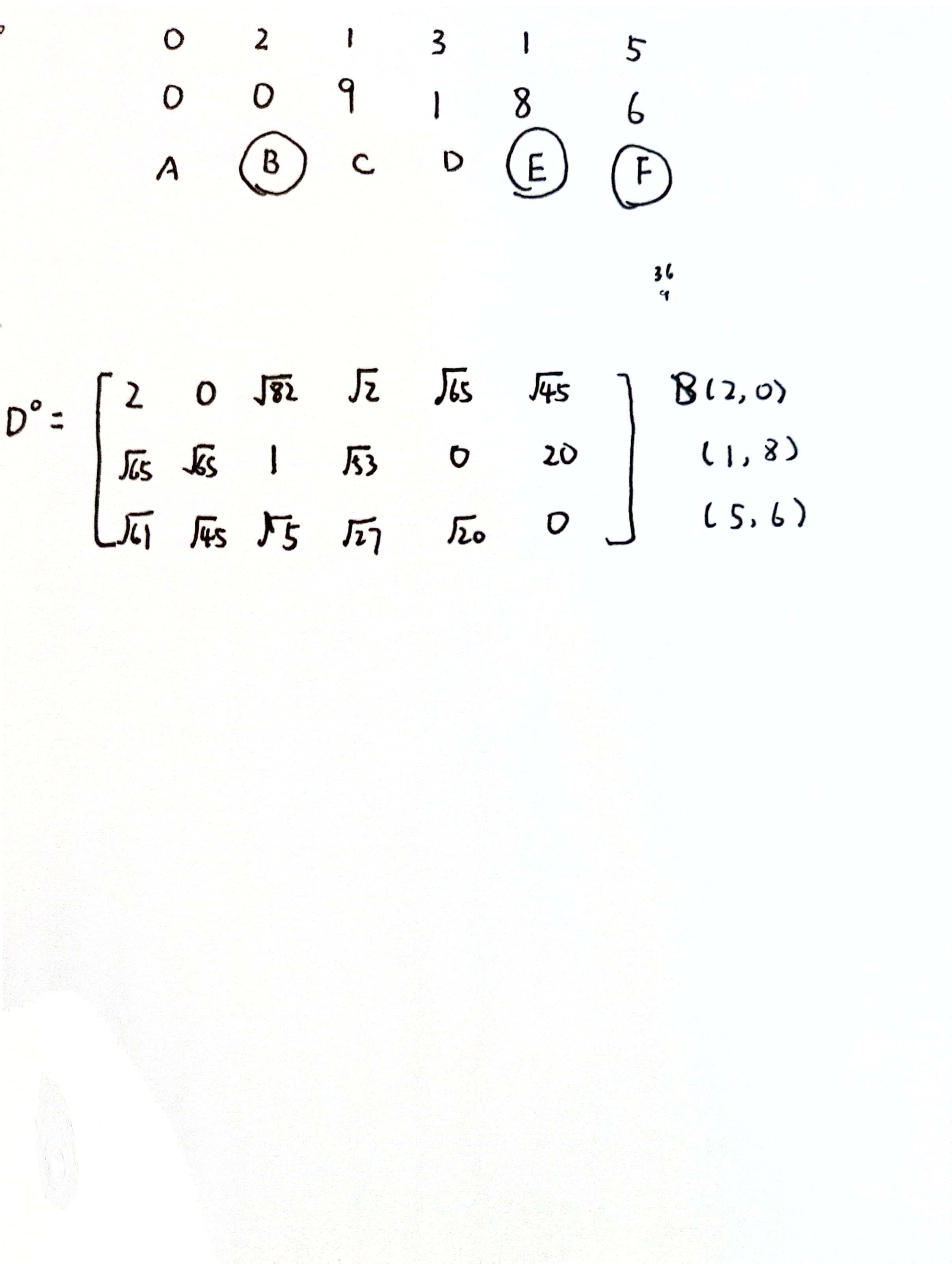
答:最终的中心点与类别的数据点为 {(1,8.5):(1,8),(1,9)),((5,6):(5,6)),{(2,0):(0,0),(2,0),(3,1)}。
【7】在第 5 题和第 6 题中,如果改变距离函数(例如,变成 L1 范数或者其他距离函数),对最后的结果会有什么影响?
参考答案:会产生影响,例如,如果采用 L1 范数作为距离函数,则中心点的选取存在很多选择,并且保证这些不同的中心点到数据点的距离之和是相同的。
【8】你能不能找到一个例子,使 Kmeans 算法在不同的初始点下得到的结果是不同的?
在数据分布不规则,或者是簇的形状、密度差异较大时,不同的初始质心可能会产生不同的聚类结果。
(1,2),(1,4),(1,0),(10,2),(10,4),(10,0)
不定项选择题
【9】机器学习处理的问题包括 ( ABC )
A. 无监督学习 B. 半监督学习 C. 监督学习 D. 有序学习
【10】我们希望一个在训练集上表现良好的模型在测试集上也有较好的表现,这种性质叫做
A. 优化 B. 泛化 C. 拟合 D. 表达
参考答案:B。
【11】在回归问题中,我们只能选择平方距离作为损失函数。 参考答案:错。还可以选择绝对距离等。
【12】为了提高泛化性,我们经常需要从训练数据集中分出一部分作为调优集。 参考答案:对。
【13】一般而言,较简单的模型更容易欠拟合,较复杂的模型更容易过拟合。 参考答案:对。
.





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











