









前言
OLAP和OLTP
数据处理大致可以分成两大类:
联机分析处理OLAP(On-Line Analytical Processing)
联机事务处理OLTP(On-Line Transaction Processing)
OLTP是传统的关系数据库的主要应用,主要用于基本的、日常的事务处理。例如银行交易
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果
OLAP(On-Line Analytical Processing)在线分析处理是一种共享多维信息的快速分析技术;
OLAP利用多维数据库技术使用户从不同角度观察数据
OLAP用于支持复杂的分析操作,侧重与对管理人员的决策支持,可以满足分析人员的快速、灵活地进行大数据复量的复杂查询的要求、并且以一种直观易懂的形式呈现查询结果,辅助决策
基本概念
度量:数据度量的指标,数据的实际含义(最终要统计的结果值,measure)
维度:描述与业务主题相关的一组属性,(条件)
事实:不同维度在某一取值下的度量(事实表:维度+度量)
OLAP特点
- 快速性:用户对OLAP的快速反应能力有很高的要求。系统应能在5秒内对用户的大部分分析要求做出反应。
- 可分析性:OLAP系统应能处理与应用有关的任何逻辑分析和统计分析。
- 多维性:多维性是OLAP的关键属性。系统必须提供对数据的多维视图和分析,包括对层次维和多重层次维的完全支持。
- 信息性:不论数据量有多大,也不管数据存储在何处,OLAP系统应能及时获得信息,并且管理大容量信息。
OLAP分类
1.按存储方式分类(https://blog.csdn.net/liu251/article/details/40785291)
- ROLAP
ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维至少使用一个表来存放维的层次、成员类别等维的描述信息。维表和事实表通过主关键字和外关键字联系在一起,形成了"星型模式"。对于层次复杂的维,为避免冗余数据占用过大的存储空间,可以使用多个表来描述,这种星型模式的扩展称为"雪花模式"。特点是将细节数据保留在关系型数据库的事实表中,聚合后的数据也保存在关系型的数据库中。这种方式查询效率最低,不推荐使用。 - MOLAP
表示基于多维数据组织的OLAP实现(Multidimensional OLAP)。以多维数据组织方式为核心,也就是说,MOLAP使用多维数组存储数据。多维数据在存储中将形成"立方块(Cube)“的结构,在MOLAP中对"立方块"的"旋转”、“切块”、"切片"是产生多维数据报表的主要技术。特点是将细节数据和聚合后的数据均保存在cube中,所以以空间换效率,查询时效率高,但生成cube时需要大量的时间和空间。 - HOLAP
表示基于混合数据组织的OLAP实现(Hybrid OLAP)。如低层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。特点是将细节数据保留在关系型数据库的事实表中,但是聚合后的数据保存在cube中,聚合时需要比ROLAP更多的时间,查询效率比ROLAP高,但低于MOLAP。
2.按处理方式分类(https://blog.csdn.net/dufufd/article/details/78621158)
- Server OLAP
数据在服务器端的多维分析 - Client OLAP
把部分数据下载到本地,为用户提供本地的多维分析
OLAP基本操作
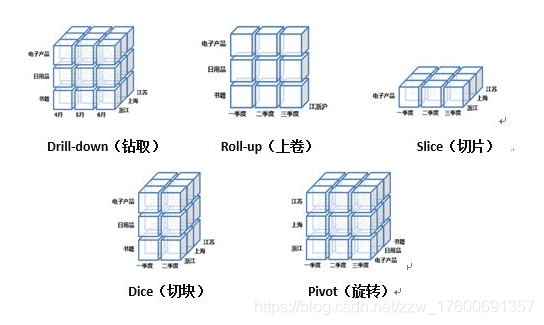
- Drill-down:钻取,在维的不同层次间的变化,从上层降到下一层,或者说将汇总数据拆分成更细节的数据。比如第二季度的数据拆分成4、5、6月
- Roll-up:上卷,钻取的逆操作,从下层升到上一层,将更细粒度的数据向高层次进行聚合。比如将一年12个月的数据聚合成四个季度的数据
- Slice:切片,获取数据某一个维上特定值的数据,比如在时间维上,有十二个月,取4月的数据
- Dice:切快,获取数据在某一个维上多个值的数据,比如在时间维上,取3,4,5月的数据,这些数据就是一个快
- Pivot:旋转,维的位置的转换,就像二维表中行列的转换
OLTP:On-Line Transaction Processing,联机事务处理,表示事务性非常高的系统,一般都是高可用的在线系统。以小的事物和小的查询为主,评测其系统时,一般看每秒执行的Transaction和Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个、几千个。select语句的执行量每秒几千甚至几万个。典型的OLAP系统有电子上午系统、银行、证券等。
Kylin简介
Apache kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口以及多维分析(OLAP)以支持超大规模数据。它能在亚秒内查询巨大的Hive表。最初由eBay Inc. 开发并贡献至开源社区。
- 可扩展超快OLAP引擎
是为解除在Hadoop/Spark上百亿规模数据的查询延迟而设计 - Hadoop ANSI SQL接口
kylin为Hadoop提供SQL支持大部分查询功能 - 交互式查询能力
通过kylin,用户可以和Hadoop在亚秒级内进行交互,在同样的数据集上,提供比Hive更好的性能 - 多维立方体(MOLAP Cube)
用户可以在kylin内为百亿以上的数据集定义数据模型,并构建立方体 - 与BI无缝结合(BI:商业智能)
kylin提供和BI工具的整合能力,如Tableau,PowerBL/Excel,MSTR,QlikSense,Hue和superSet - Job的管理和监控
- 解码和压缩
- 增量更新
- 利用HBase Coprocessor
Coprocessor:协处理器 - 基于HyperLogLog的Dinstinc Count近似算法
- 友好的WEB-UI界面,以管理、监控和使用立方体
- 项目及表级别的访问控制安全
- 支持LDAP、SSO
kylin架构
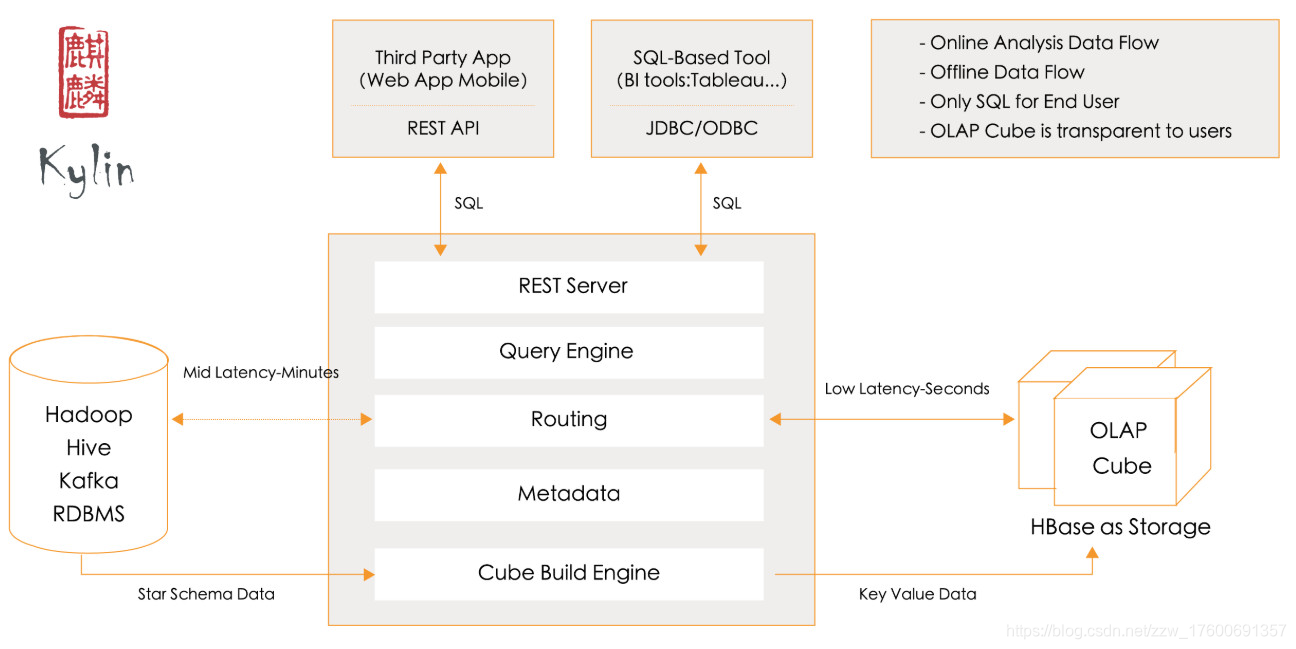
Hadoop/Hive:kylin是一个MOLAP系统,将Hive中的数据进行预处理,利用MR或者Spark进行实现
HBase:kylin用来存储OLAP分析结果cube数据的地方,实现多维数据集的交互式查询
rest server:提供restful 接口
query engine:使用开源的calcite框架实现sql的解析,是Sql引擎层
routing:路由层,负责将解析生成的执行计划转成cube缓存的查询
metadata:kylin大部分元数据信息的存储
Cube Build Engine:负责kylin预计算中创建Cube
kylin工作原理
Apache kylin的工作原理本质上是MOLAP(Multidimensional On-Line Analytical Processing) Cube,也就是多维立方体在线分析计算
kylin的核心思想是预计算,即对多维分析可能用到的度量(即条件)进行预计算,把计算好的结果保存成cube,并存储到HBase中。共查询时直接使用。把高复杂的聚合计算和多表联合等操作转换成预计算结果的查询。这决定了kylin具有良好的快速查询和高并发能力
名词解释
- 事实表
用来记录具体事件的,包含每个事件的具体要素以及具体发生的事情(发生的条件以及事件结果) - 对事实表中具体要素的描述信息(条件表)
- 维度
观察数据的角度,查询条件 - 度量
被聚合的统计值,在对应查询条件下的查询结果 - cuboid
维度的任意组合,即多条查询条件结果的组合,比如年龄18的学生的查询结果和年龄18,性别男的查询结果的组和 - cube
所有维度的组和,包括所有的cuboid
多维数据分析模型
星型模型:(百度百科:https://baike.baidu.com/item/星型模型/9133897?fr=aladdin)
星形模式是多维的数据关系,它由事实表(Fact Table)和维表(Dimension Table)组成。每个维表中都会有一个维作为主键,所有这些维的主键结合成事实表的主键。事实表的非主键属性称为事实,它们一般都是数值或其他可以进行计算的数据。
星形模式是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据;而维度都是文字、时间等类型的数据,按这种方式组织好数据我们就可以按照不同的维(事实表主键的部分或全部)来对这些事实数据进行求和(summary)、求平均(average)、计数(count)、百分比(percent)的聚集计算,甚至可以做20~80分析。这样就可以从不同的角度数字来分析业务主题的情况。
雪花模型:(百度百科:https://baike.baidu.com/item/雪花模型/3139991)
雪花模型是当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。
相比星型模型,雪花模型的特点是贴近业务,数据冗余较少,但由于表连接的增加,导致了效率相对星型模型来的要低一些。
电商维度模型建立实例
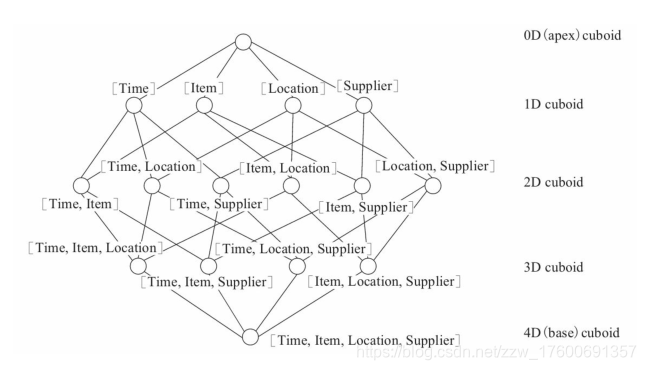
假定有一个电商的销售数据集,其中维度包括时间(Time)、商品(Item)、地点(Location)和供应商(Supplier),度量为销售额(GMV)。那么所有维度的组合就有2 4 =16种,比如一维度(1D)的组合[Time]、[Item]、[Location]、[Supplier]4种;二维度(2D)的组合有[Time,Item]、[Time,Location]、[Time、Supplier]、[Item,Location]、[Item,Supplier]、[Location,Supplier]6种;三维度(3D)的组合也有4种;最后零维度(0D)和四维度(4D)的组合各有1种,总共就有16种组合。
cube构建流程:
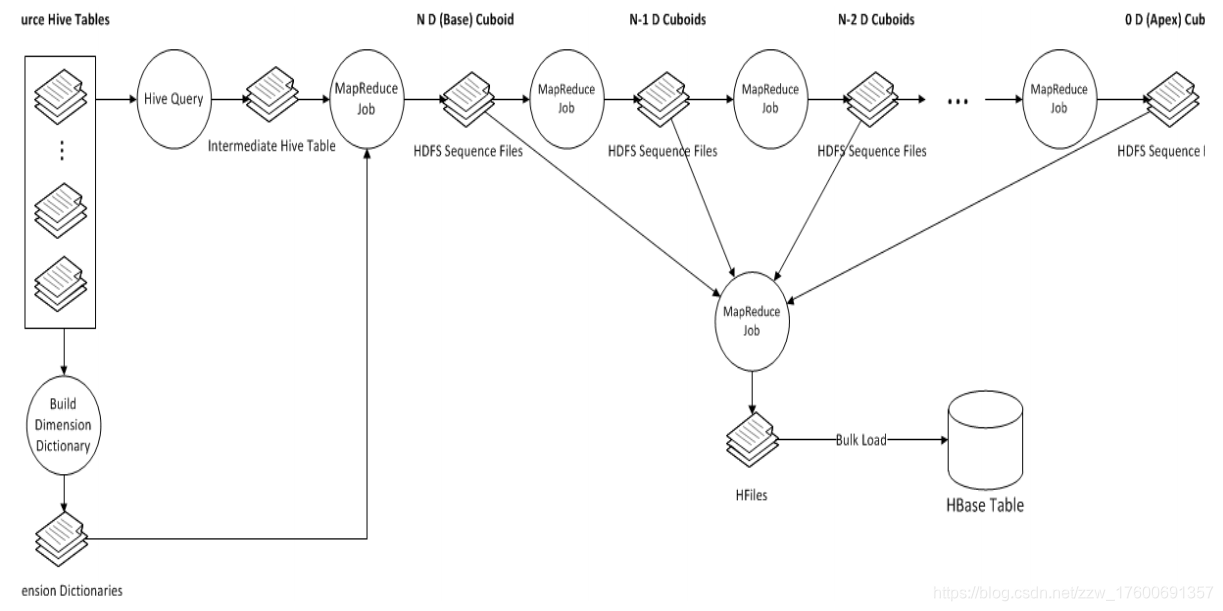
- 构建一个中间平表(Hive table),将Model中fact表和look up表构建成一个大的Flat Hive Table
- 重新分配Flat Hive Table
- 从事实表中抽取维度的Distinct(不同)值
- 对所有的维度表进行压缩编码,生成维度字典
- 计算和统计所有的维度组和,并保存。其中,每一种维度组合成为一个Cuboid
- 创建HTable
- 构建最基础的Cuboid数据
- 利用算法构建N维到0维的Cuboid数据
- 构建Cube
- 将Cuboid数据转换成HFIle
- 将HFile直接加载到HBase Table中
- 更新Cube数据
- 清理Hive
kylin搭建

1.最底层是数据来源层,可以通过Sqoop等工具将数据加载到hdfs等分布式文件系统中
2.kylin依赖hadoop平台,包括hbase、hive、mapreduce等。即kylin运行在hadoop的大数据平台上
kylin的部署有两种方式
1.单实例部署
在hadoop集群的一个节点上部署,然后启动。
部署特点:简单快捷,但处理并发请求比较多,单台会形成瓶颈
2.集群部署
集群模式只需要增加kylin的节点数,因为kylin的元数据是存储在hbase中的,只需要在kylin中配置,可以访问到相同一份元数据即可(kylin.metadata.url相同),并且集群中只有一个可运行的任务引擎,其他都是查询引擎
集群模式还可以使用LB(nginx),实现访问请求的负载均衡














 2348
2348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









