







 本文回顾了消息队列的典型应用场景,包括异步处理、流量削峰、系统解耦和数据同步,并以Kafka为例,详细介绍了主题、分区、broker和副本机制,以及消费者组的工作原理。
本文回顾了消息队列的典型应用场景,包括异步处理、流量削峰、系统解耦和数据同步,并以Kafka为例,详细介绍了主题、分区、broker和副本机制,以及消费者组的工作原理。
不管是工程师还是架构师我相信你或多或少知道消息队列的作用,这里我们先回顾下消息队列的典型应用场景,然后再以kafka为切入点看看kafaka是内部怎么运行的。
典型应用场景:
- 异步处理。消息发送后,发送任务就算处理完成,不用同步等待处理结果,同步转异步了。
- 流量削峰。由于消息队列本身具有存储数据的功能,它可以把大量数据存起来。所以可以抵挡流量,起到流量先存起来后续慢慢处理的作用。
- 系统解耦。业务系统之间可以通过消息队列进行交换消息,既方便统一标准,也方便后续扩展。
- 数据同步。因为消息队列具有持久化和重试功能,所以还可以作为数据同步的管道。比如将mysql数据实时同步到es中,这里会将变更消息发送到消息队列,然后消费数据后存入es。后面我会写文章剖析该方案。
下面以kafka为切入点看下,kafka内部怎么运行的。这里先贴张网上的架构图,我觉得画的很好,图文结合更好理解。
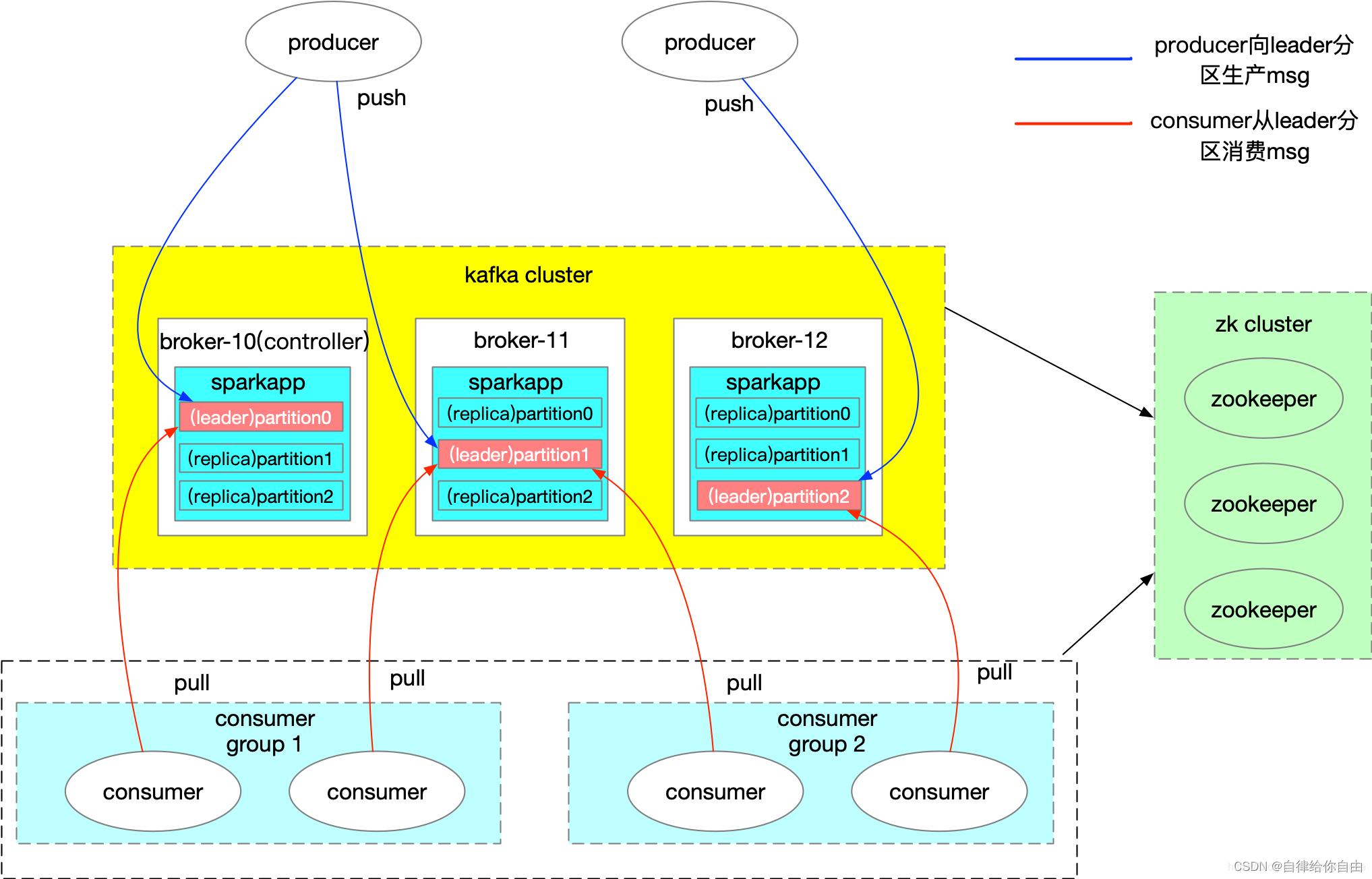
主题和分区:
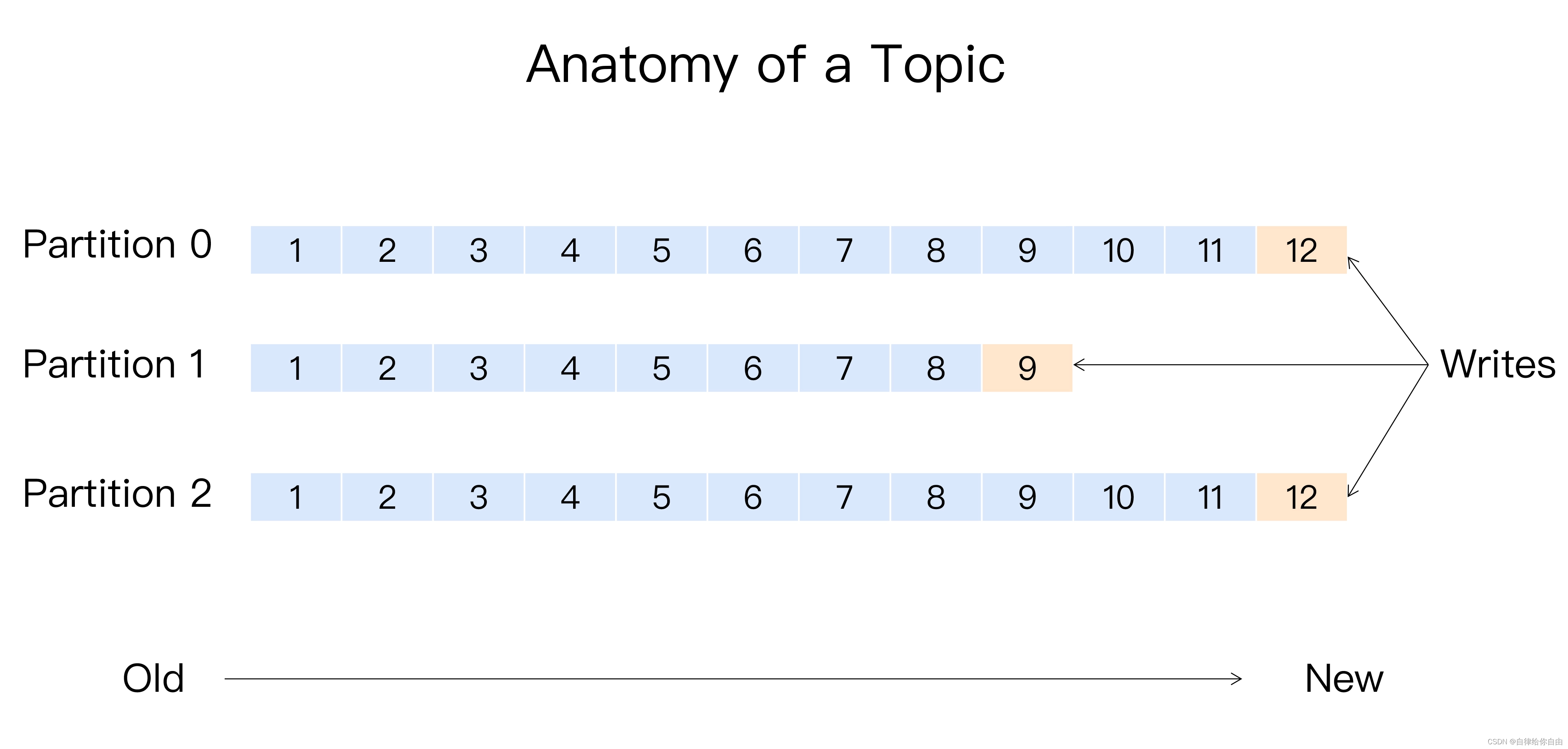
生产者发送消息需要指定主题,比如《运单发车》这个主题。主题下可以配置多个分区,分区对应图上的partition。分区的作用是提供系统负载均衡能力,或者说是系统的扩展能力。试想下没有分区,相同的主题则只有一个队列,性能怎么会高呢?一条消息会根据消息key按指定的分区算法落到对应的分区上。相同的key则会落到同一个分区上,那么相同的key也就有了顺序性。
broker和副本机制:
broker可以理解为kafka服务器进程,多个broker就构成了集群。消息算出要落到哪个分区后,消息该往哪个broker发送消息呢?客户端会从连接的broker上去拿到元信息。元信息里包含了broker列表,分区列表,副本列表等信息,可以理解为主题分区及副本的映射关系。那么找到自己对应的分区在哪个broker后,会往该broker发送消息。
那副本又是什么?副本其实是kafka高可用的实现方式,顾名思义一个数据存多个副本数据。只有一个leader副本,有多个跟随副本。跟随副本只做备份使用,多了也不会分摊系统读写性能。因为读写只会在leader副本进行。跟随副本只会在leader副本的broker挂了时,候选为leader副本。你看架构图中的partition0、partition1、partition2分属于不同的broker,当partition0的broker挂了时,那么partition1,partition2的机器会基于zookeeper选举为新的leader,从而继续提供服务。
消费者组:
说完消息发送和存储,那么接着说怎么消费消息。多个消费者如果指定了同一个groupId_1,那么就组成了同一个消费者组。同一个分区里的消息只会被一个消费者消费。如果消费者挂了,消费协调者会指定同组里其他消费者顶上(这也是叫《重平衡》)。消费者在消费过程中有个字段叫消费者位移,这个记录了消费者消费到哪个消息位置了。消费到哪个位置了,则提交哪个位置,不提交则可以重新继续消费。如果只有一个消费者组那么就是点对点模式,因为消息只会被一个组消费一次。如果再增加一个消费者组groupId_2,那么消息就会被两个组消费,这其实就实现了发布订阅模式。
了解内部大体怎么运行的后,后续我们再分析每个细节怎么运行的。















 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









