







Sitting in Line
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5691
个人想法:这是我第一次感觉做状压这么难的地方,其实我并不会做这道题,因为我感觉完全没思路,我有点不敢去写,可能是我对状压理解的不够深,我听同学说可以用旅行商的状压来解决这道问题,可是我完全悟不出旅行商的道理来,然后我自己琢磨的想了想,我想出了一种自己对这道题理解的状压.实在艰辛啊…
分析:给你一堆数,有些可以和其他数字互换位置,有些却只能在固定的位置,要使得max{a1⋅a2+a2⋅a3+…+aN−1⋅aN}的值最大,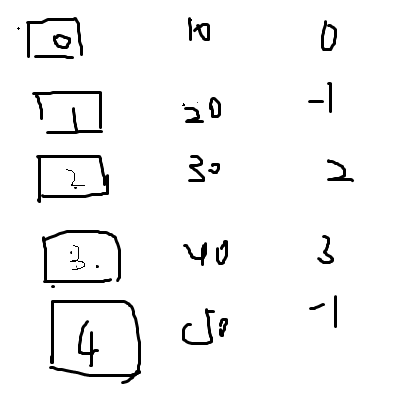
假若现在1,2层的数字是随机的,那么如果我选择第2层的时候,我并不知道前一层选择了的数字,随意我只能通过前一层枚举过的数字来递推下一层的数字.
首先我们会遇到这种情况,这时,我们递推就不需要利用上层的数字了,因为第一层已经被夹住,所以转移方程会成为dp[s|1<<1][1]加上a0a1+a1a2的值,决定过的值必须加上,同样道理还会出现
那 么第一层我就得处理成dp[s|1<<0][0]加上a0*a1的值,主要是因为后一层已经决定过了,这层就不管了,直接加上就行,其他情况也是类型的…
我的dp是先对状态预处理一下,例如第3章图的1,2层,其实直接把他的值乘起来就好了,因为值已经决定,我们不枚举这层,直接走过,可能状压有点难,直接看看代码吧–>
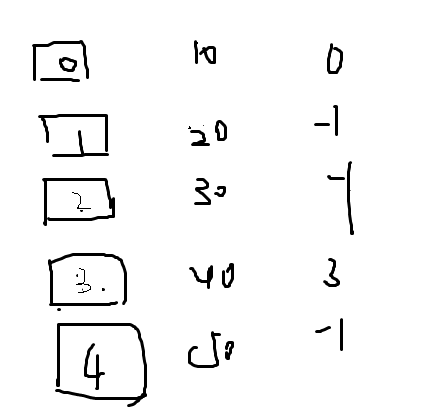
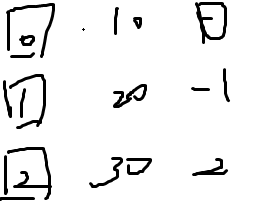
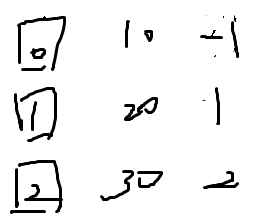
代码:
/* Author:GavinjouElephant
* Title:
* Number:
* main meanning:
*
*
*
*/
//#define OUT
#include <iostream>
using namespace std;
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
#include <sstream>
#include <cctype>
#include <vector>
#include <set>
#include <cstdlib>
#include <map>
#include <queue>
//#include<initializer_list>
//#include <windows.h>
//#include <fstream>
//#include <conio.h>
#define MaxN 0x7fffffff
#define MinN -0x7fffffff
#define Clear(x) memset(x,0,sizeof(x))
const int INF=0x6f6f6f6f;
int T;
int N;
int has;//初始有多少个层已经被利用
int Can[20];//这是用来表示这个位置的值是不是可选的
int Can_Value[20];//对应位置的值
int Top;//用来记录Pos的长度
int Pos[20];//表示哪层是没决定的
int State;//开始的状态
int dp[1<<16][20];
class Node
{
public:
int x;
int y;
}node[20];
bool cmp(const Node &a,const Node &b)
{
return a.y>b.y;
}
void init()
{
memset(Can,-1,sizeof(Can));
memset(dp,-0x6f,sizeof(dp));
memset(Pos,0,sizeof(Pos));
}
int getx(int x)
{
int ans=0;
while(x)
{
if(x&1)ans++;
x>>=1;
}
return ans;
}
int main()
{
#ifdef OUT
freopen("coco.txt","r",stdin);
freopen("lala.txt","w",stdout);
#endif
scanf("%d",&T);
int caseT=0;
while(T--)
{
Top=0;
State=0;
has=0;
caseT++;
printf("Case #%d:\n",caseT);
init();
scanf("%d",&N);
for(int i=0;i<N;i++)
{
scanf("%d%d",&node[i].x,&node[i].y);
if(node[i].y!=-1)
{
has++;
State+=(1<<node[i].y);
}
}
sort(node,node+N,cmp);
if(N==1){printf("%d\n",node[0].x);continue;}
int index=0;
for(int i=0;i<N;i++)
{
if(node[i].y!=-1)
{
Can[node[i].y]=0;
Can_Value[node[i].y]=node[i].x;
continue;
}
for(;index<N;index++)
{
if(Can[index]==-1)
{
Pos[Top++]=index;
Can_Value[index]=node[i].x;
index++;
break;
}
}
}
//上面的一堆代码其实就是处理一下位置,因为 p是未知得,我就处理一下,p!=-1的先放对应Can里面,然后剩下的随便排就好
//下面这一段是把那种连续层的值先加上,
int Value=0;
for(int j=1;j<N;j++)
{
if((State&(1<<j))&&(State&(1<<(j-1))))
{
Value+=Can_Value[j]*Can_Value[j-1];
}
}
dp[State][0]=Value;
//先预处理第一层,因为第一层递推后面层,而且判断条件和后续层不一样,所以为了少点代码就先处理了
for(int j=0;j<N;j++)
{
int now=Pos[0];
int left=now-1;
int right=now+1;
if(State&(1<<j))continue;
if(now==0)
{
if(Can[right]==-1)
{
dp[State|(1<<j)][j]=Value;//这代表下一层是可选的状态
}
else
{
dp[State|(1<<j)][j]=Value+(Can_Value[j]*Can_Value[right]);
}
}
else if(now==N-1)
{
dp[State|(1<<j)][j]=Value+(Can_Value[j]*Can_Value[left]);
}
else
{
if(Can[right]==-1)
{
dp[State|(1<<j)][j]=Value+(Can_Value[j]*Can_Value[left]);
// cout<<Value<<endl;
}
else
{
dp[State|(1<<j)][j]=Value+(Can_Value[j]*Can_Value[left])+(Can_Value[j]*Can_Value[right]);
}
}
}
for(int s=State+1;s<((1<<N)-1);s++)
{
int x=getx(s);
int now=Pos[x-has];
int left=now-1;
int right=now+1;
if(x==has)continue;
for(int j=0;j<N;j++)
{
if(s&(1<<j))continue;
for(int k=0;k<N;k++)
{
if(dp[s][k]==-INF)continue;//如果这个状态没有其他状态递推过过来,那就不管了,
//这一样的对当前层进行处理,一定要注意究竟前一层是不是可选的和后一层是不是可选的;
if(now==N-1)
{
if(Can[left]==-1)
{
dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[k]);
}
else
{
dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[left]);
}
}
else
{
if(Can[left]==-1)
{
if(Can[right]==-1) {dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[k]);}
else {dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[k]+Can_Value[j]*Can_Value[right]);}
}
else
{
if(Can[right]==-1) {dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[left]);}
else{dp[s|(1<<j)][j]=max(dp[s|(1<<j)][j],dp[s][k]+Can_Value[j]*Can_Value[left]+Can_Value[j]*Can_Value[right]);}
}
}
}
}
}
int ans=-INF;
for(int j=0;j<N;j++)
{
ans=max(ans,dp[(1<<N)-1][j]);
}
printf("%d\n",ans);
}
return 0;
}















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









