






【题目要求】:
- 分析网页url,找到规律,遍历前5页;
- 获取每个商品的价格和策略;
- 找到商品的策略,包括自营 放心购 包邮等信息,使用.text获取直接输出会换行,用replace("\n", " ")进行替换,替换后头尾多余的空格用strip()去掉;
- 输出格式:优惠:xxx 策略:自营 放心购
print(f"价格:{p_price} 策略:{title}")。 - 提示:如果你觉得输出的结果类似,又总是报错点击【我哪里错了】查看格式,需要按题目要求格式来输出哦。
- 注意:如果你打开网页商品数量较少,更改配送位置哦。
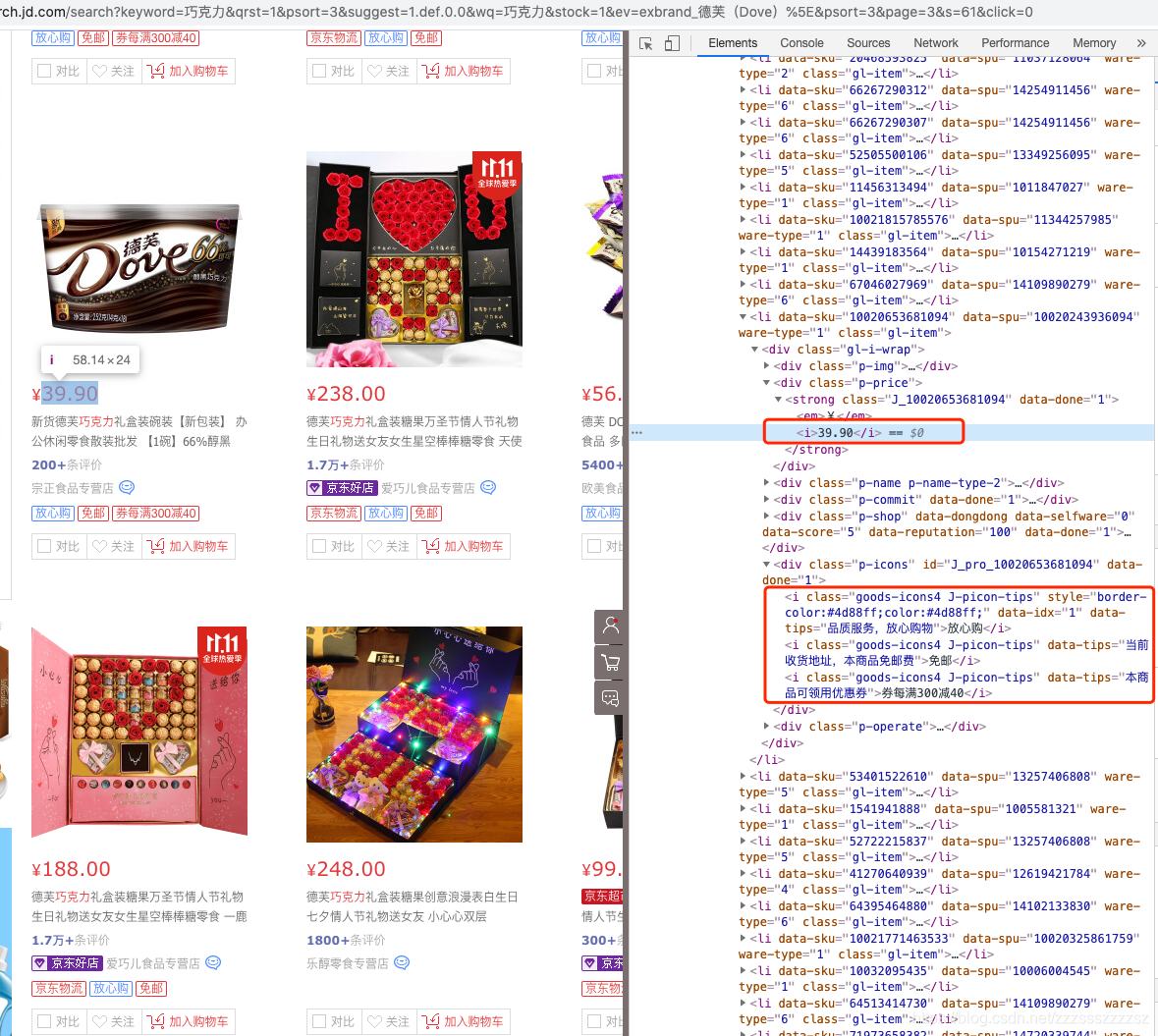
# 使用import导入requests模块
import requests
# 从bs4中导入BeautifulSoup模块
from bs4 import BeautifulSoup
# 将User-Agent以字典键对形式赋值给headers,并加入cookie
headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"cookie":"shshshfpa=59756f24-6de8-90a9-92f3-022a321cbcaa-1589969605; __jdu=1589969605288365795565; shshshfpb=fZNp5OzH0j2T%20X%20WnJhzrBg%3D%3D; qrsc=3; user-key=b05356ef-c40b-44d2-a837-60df17e9b74e; cn=0; _pst=jd_51aaae03cedfa; unick=jd_51aaae03cedfa; pin=jd_51aaae03cedfa; _tp=FNP1fTo2ON7jgdbikn0lWAbSqMI20pF0xO0Iq%2FccQVc%3D; pinId=qN40m03yULDpSLzjaHwm07V9-x-f3wj7; __jdc=122270672; rkv=1.0; 3AB9D23F7A4B3C9B=DVCEDHG6BLYWMZMJIWNBOSTWP7GOWK77C5VJKGVQO7F3JHUFZVL5V5B5UKDYLF2LK5VAEIOSN2YRG33EJLXR6ZJ2TU; __jdv=122270672|direct|-|none|-|1602475191357; areaId=22; ipLoc-djd=22-1930-50947-0; __jda=122270672.1589969605288365795565.1589969605.1602487075.1602569356.29; shshshfp=b393a5ab6c1163583435b3a90574cb22; shshshsID=ef428a912dae95ba61fd7ac2ee0af172_9_1602570753319; __jdb=122270672.9.1589969605288365795565|29.1602569356"}
# 使用for循环遍历range()函数生成的0-4的数字
for i in range(0, 5):
# 计算每页url中的变量page
page = i * 2 + 1
# 计算每页url中的变量product_counter
product_counter = i * 60 + 1
# 使用格式化方法,将网址赋值给变量url
url = f"https://search.jd.com/search?keyword=%E5%B7%A7%E5%85%8B%E5%8A%9B&qrst=1&psort=3&suggest=1.def.0.0&wq=%E5%B7%A7%E5%85%8B%E5%8A%9B&stock=1&ev=exbrand_%E5%BE%B7%E8%8A%99%EF%BC%88Dove%EF%BC%89%5E&psort=3&page={page}&s={product_counter}&click=0"
res=requests.get(url,headers=headers)
html=res.text
soup=BeautifulSoup(html,"lxml")
content_all=soup.find_all("li")
c=""
for content in content_all:
price=content.find(class_="p-price")
policy=content.find(class_="p-icons")
if price !=None:
a=price.find("i").string
b=policy.find_all("i")
for bb in b:
c=(c+" "+bb.string).strip()
print(f"价格:{a} 策略:{c}")
c=""

















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









