







 本文介绍了Hadoop 3.0中的Erasure Coding纠删码技术,该技术是一种数据保护手段,能减少副本带来的存储空间消耗。文章详细阐述了Erasure Coding的优势和劣势,以及在Hadoop中的实现过程,包括数据恢复的3个步骤,并指出了潜在的改进点。
本文介绍了Hadoop 3.0中的Erasure Coding纠删码技术,该技术是一种数据保护手段,能减少副本带来的存储空间消耗。文章详细阐述了Erasure Coding的优势和劣势,以及在Hadoop中的实现过程,包括数据恢复的3个步骤,并指出了潜在的改进点。
前言
HDFS也可以支持Erasure Coding功能了,将会在Hadoop 3.0中发布,可以凭图为证:
在HDFS-7285中,实现了这个新功能.鉴于此功能还远没有到发布的阶段,可能后面此块相关的代码还会进行进一步的改造,因此只是做一个所谓的预分析,帮助大家提前了解Hadoop社区目前是如何实现这一功能的.本人之前也没有接触过Erasure Coding技术,中间过程也确实有些偶然,相信本文可以带给大家收获.
巧遇Hadoop 3.0 Erasure Coding
第一次主动去了解erasure coding这个东西纯粹是好奇,因为我平时主要混迹于Hadoop社区中HDFS模块部分,经常看到有很多的Issue Summary以单词Erasure Coding打头,而且这些任务一般都隶属于HDFS-8031下的子任务,比如下图所示的1个:

原来这是Erasure coding后续1阶段的工作.然后我就上网查了一下Erasure coding的意思于是就萌生了写此文的意图.Erasure coding同样作为一门技术,在学习hadoop 3.0 erasure coding之前,还是非常有必要去了解学习Erasure coding这门技术.
Erasure coding纠删码
Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术.他通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性.在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复.下面结合图片进行简单的演示,首先有原始数据n个,然后加入m个校验数据块.如下图所示:
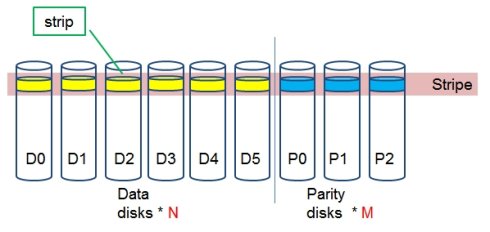
Parity部分就是校验数据块,我们把一行数据块组成为Stripe条带,每行条带由n个数据块和m个校验块组成.原始数据块和校验数据块都可以通过现有的数据块进行恢复,原则如下:
- 如果校验数据块发生错误,通过对原始数据块进行编码重新生成
- 如果原始数据块发生错误, 通过校验数据块的解码可以重新生成
而且m和n的值并不是固定不变的,可以进行相应调整.可能有人会好奇,这其中到底是什么原理呢? 其实道理很简单,你把上面这图看成矩阵,由于矩阵的运算具有可逆性,所以就能使数据进行恢复,给出一张标准的矩阵相乘图,大家可以将二者关联.
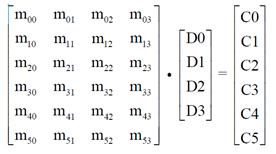
至于里面涉及数学推理的方面,同学们可以自行寻找资料进行学习.
Erasure Coding技术的优劣势
优势
纠删码技术作为一门数据保护技术,自然有许多的优势,首先可以解决的就是目前分布式系统,云计算中采用副本来防止数据的丢失.副本机制确实可以解决数据丢失的问题,但是翻倍的数据存储空间也必然要被消耗.这一点却是非常致命的.EC技术的运用就可以直接解决这个问题.
劣势
EC技术的优势确实明显,但是他的使用也是需要一些代价的,一旦数据需要恢复,他会造成2大资源的消耗:
- 网络带宽的消耗,因为数据恢复需要去读其他的数据块和校验块
- 进行编码,解码计算需要消耗CPU资源
概况来讲一句话,就是既耗网络又耗CPU,看来代价也不小.所以这么来看,将此计数用于线上服务可能会觉得不够稳定,所以最好的选择是用于冷数据集群,有下面2点原因可以支持这种选择
- 冷数据集群往往有大量的长期没有被访问的数据,体量确实很大,采用EC技术,可以大大减少副本数
- 冷数据集群基本稳定,耗资源量少,所以一旦进行数据恢复,将不会对集群造成大的影响
出于上述2种原因,冷数据集群无非是一个很好的选择.
Erasure Coding技术在Hadoop中的实现
前面花了大量的篇幅介绍EC技术,相信大家已经或多或少了解了这项技术.现在才是本文的一个重点,Hadoop Erasure Coding的实现.因为我们都知道,Hadoop作为一个成熟的分布式系统,用的也是3副本策略,所以这项技术的产生对于Hadoop本身来说,意义还是非常重大的.考虑到EC技术在Hadoop中的实现细节可能比较复杂,所以我不会逐行代码般的进行分析,从大的方向上理一理实现思路.
EC概念在Hadoop中的演变
EC概念指的是data block数据块,parity block校验块,stripe条带等这些概念在H
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









