







1 基本概念
HDFS为擦除编码(EC)提供了支持,以更有效地存储数据。与默认三个副本机制相比,EC策略可以节省约50%的存储空间
但不可忽略的是编解码的运算会消耗CPU资源。纠删码的编解码性能对其在HDFS中的应用起着至关重要的作用,如果不利用硬件方面的优化就很难得到理想的性能。英特尔的智能存储加速库(ISA-L)提供了对纠删码编解码的优化,极大的提升了其性能
纠删码是hadoop3.x新加入的功能,之前的hdfs都是采用副本方式容错,默认情况下,一个文件有3个副本,可以容忍任意2个副本(datanode)不可用,这样提高了数据的可用性,但也带来了2倍的冗余开销。例如3TB的空间,只能存储1TB的有效数据。而纠删码则可以在同等可用性的情况下,节省更多的空间,以RS-6-3-1024K这种纠删码策略为例子,6份原始数据,编码后生成3份校验数据,一共9份数据,只要最终有6份数据存在,就可以得到原始数据,它可以容忍任意3份数据不可用.
2 纠删码操作
2.1 纠删码策略查看
hdfs ec -listPolicies

上述策略中有多种,如上述策略箭头指向,这里介绍其中一种,其他
以此类推
RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。例如上传一个40MB的数据,那么就会将40MB的数据按1024KB为一块进行完全划分(1024KB也是最小的数据单元)。而策略中的6表示分割6个原始数据部分,对于40MB的数据,划分为6个部分,那么每个部分是7MB,7MB的数据可以看做由多个1024KB的组成,同时它也是使用1024KB进行计算的(因为并不能做到每个数据内容都能进行一个6的整倍数)原始数据部分存储是6*7MB=42MB,而使用原来副本数存储(我这里设置的是3个),那么占用的内存就是120MB,虽然纠删码策略的校验单元也占用内存,但是理论上纠删码策略节省的空间高达50%,
State:表示策略的状态。上图中RS-6-3-1024K表示开启状态
理论状态下RS-6-3-1024k需要9台DataNode,RS-3-2-1024k需要5台DataNode支持,其他以此类推
2.2 纠删码策略设置
纠删码策略是与具体的路径(
path)相关联的。也就是说,如果我们要使用纠删码,则要给一个具体的路径设置纠删码策略,后续,所有往此目录下存储的文件,都会执行此策略
默认只开启对RS-6-3-1024k策略的支持,如要使用别的策略需要先启用
以下以为input目录设置RS-3-2-1024K为例,开启纠删码策略,就不会以原来的副本策略去存储文件
1、 开启对RS-3-2-1024k策略的支持(开启以后才能使用该策略)
#开启
hdfs ec -enablePolicy -policy RS-3-2-1024k
#禁用
hdfs ec -disablePolicy -policy RS-3-2-1024k

2、在HDFS创建目录,并设置擦除策略
#目录创建
hdfs dfs -mkdir /input
#为input目录设置策略
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
#获取目录的纠删码策略
hdfs ec -getPolicy -path /input

3、上传文件,并查看文件编码后的存储情况
将任意文件上传到HDFS上,并查看副本数(当前集群中设置副本数是3,并且创建了5台DataNode,理论上RS-3-2-1024K需要5台DataNode支持)
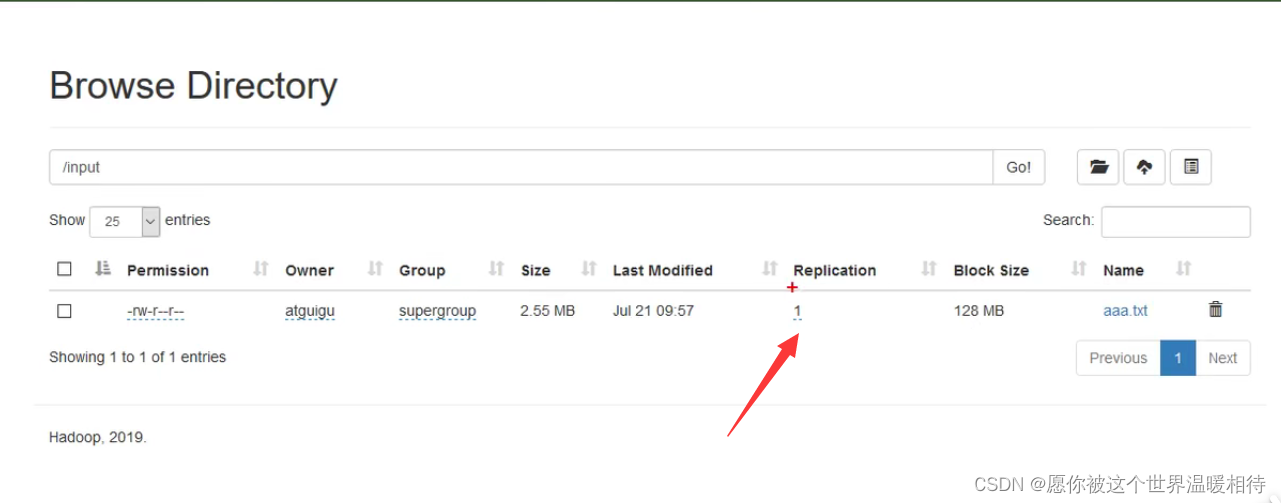
可以看到副本数为1,跟设置的不相同。点击文件可以产看数据的存储情况,可以看到在5台机器上都有数据,5个机器上的数据也就是我们的3个数据单元以及2个检验单元,每个单元在一个机器上,而不是5个单元在一个机器上。每个单元只会存一份
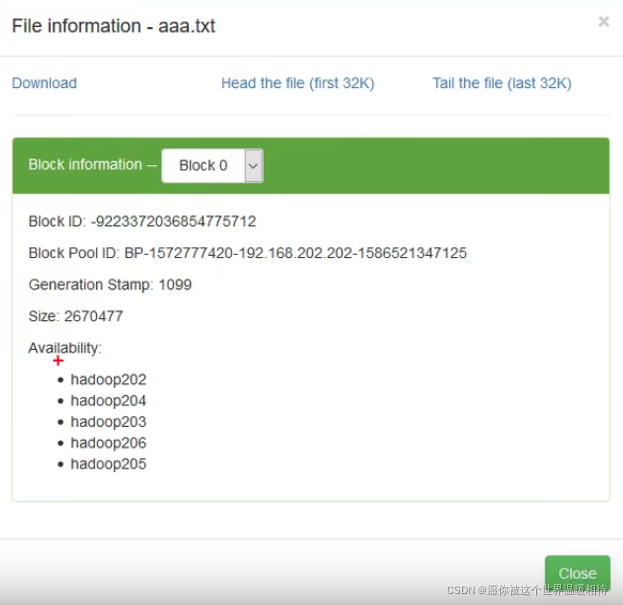
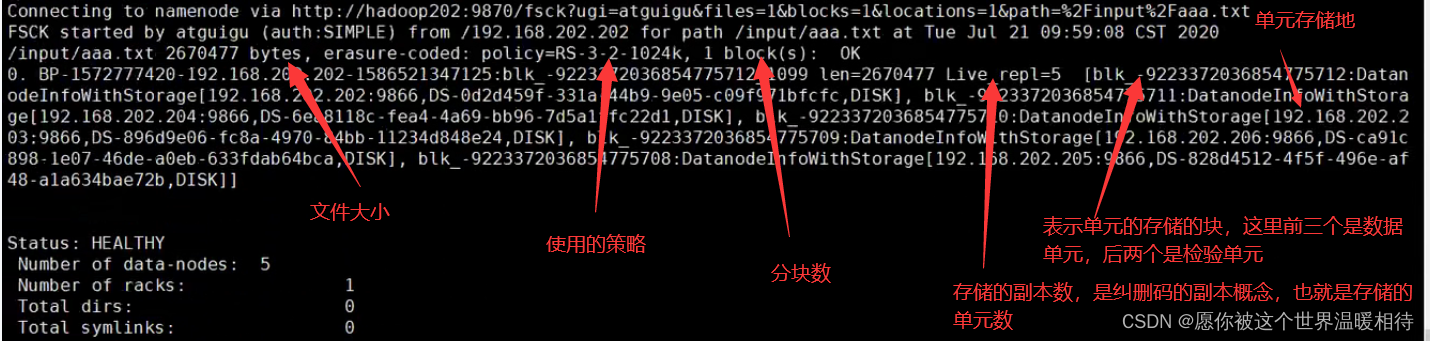
通过以下文件查看文件的存储情况
hdfs fsck /input/aaa.txt -files -blocks -locations
2.3 纠删码策略测试
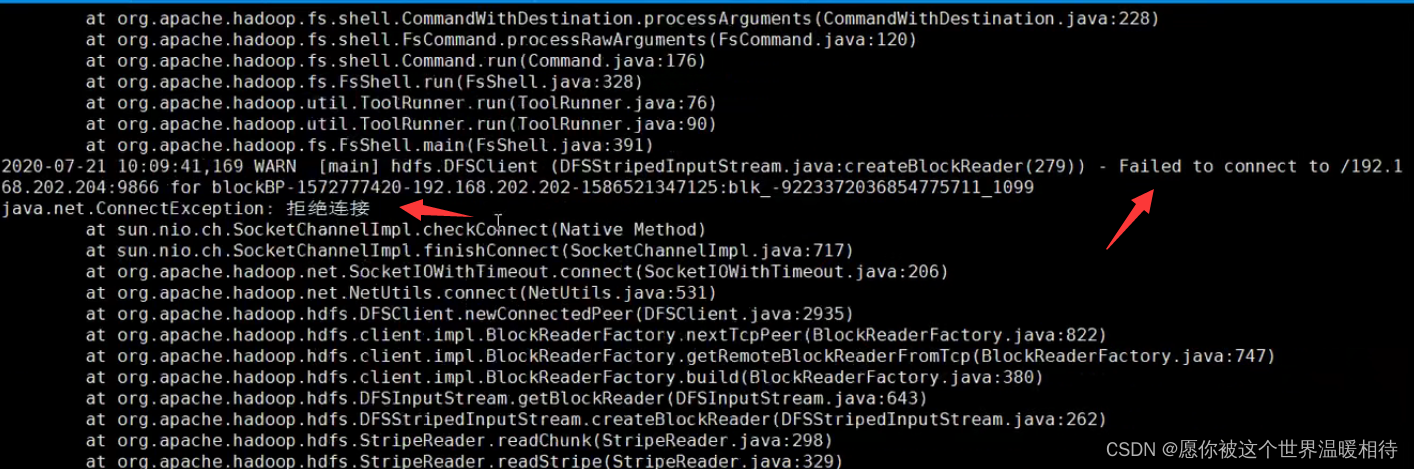
根据纠删码策略的特性,这里关闭其中一个DataNode,那么存储的5个单元中,就会缺失一个,尝试是否能正常获取文件,使用一下命令获取文件到本地
hadoop fs -get input/aaa.txt ./ec
正常而言是会报一下的错误,但是该存储是正常的,打开ec文件会看到文件被完整复制到了本地中

















 8186
8186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









