







原文:
http://blog.csdn.net/beerbuddys/article/details/40712957
下面的内容很长,倒杯水(有茶或者咖啡更好),带上耳机,准备就绪再往下看。下面我们来看强分类器是如何训练的,该过程在CvCascadeBoost::train函数中完成,代码如下:
[cpp] view plain copy print?
- bool CvCascadeBoost::train( const CvFeatureEvaluator* _featureEvaluator,
- int _numSamples,
- int _precalcValBufSize, int _precalcIdxBufSize,
- const CvCascadeBoostParams& _params )
- {
- bool isTrained = false;
- CV_Assert( !data );
- clear();
- // 样本的数据都存在 _featureEvaluator 里面,这里把训练相关的数据都
- // 用CvCascadeBoostTrainData类封装,内部创建了运行时需要的一些内存
- // 方便后面使用
- data = new CvCascadeBoostTrainData( _featureEvaluator, _numSamples,
- _precalcValBufSize, _precalcIdxBufSize, _params );
- CvMemStorage *storage = cvCreateMemStorage();
- // 创建一个 CvSeq 序列,存放一个强分类器的所有弱分类器
- weak = cvCreateSeq( 0, sizeof(CvSeq), sizeof(CvBoostTree*), storage );
- storage = 0;
- set_params( _params );
- if ( (_params.boost_type == LOGIT) || (_params.boost_type == GENTLE) )
- {
- // 从_featureEvaluator->cls 中拷贝样本的类别信息到 data->responses
- // 因为这两种boost方法计算式把类别从0/1该为-1/+1使用
- data->do_responses_copy();
- }
- // 设置所有样本初始权值为1/n
- update_weights( 0 );
- cout << "+----+---------+---------+" << endl;
- cout << "| N | HR | FA |" << endl;
- cout << "+----+---------+---------+" << endl;
- do
- {
- // 训练一个弱分类器,弱分类器是棵CART树
- CvCascadeBoostTree* tree = new CvCascadeBoostTree;
- if( !tree->train( data, subsample_mask, this ) )
- {
- delete tree;
- break;
- }
- // 得到弱分类器加入序列
- cvSeqPush( weak, &tree );
- // 根据boost公式更新样本数据的权值
- update_weights( tree );
- // 根据用户输入参数,把一定比例的(0.05)权值最小的样本去掉
- trim_weights();
- // subsample_mask 保存每个样本是否参数训练的标记(值为0/1)
- // 没有可用样本了,退出训练
- if( cvCountNonZero(subsample_mask) == 0 )
- break;
- } // 如果当前强分类器达到了设置的虚警率要求或弱分类数目达到上限停止
- while( !isErrDesired() && (weak->total < params.weak_count) );
- if(weak->total > 0)
- {
- data->is_classifier = true;
- data->free_train_data();
- isTrained = true;
- }
- else
- clear();
- return isTrained;
- }
bool CvCascadeBoost::train( const CvFeatureEvaluator* _featureEvaluator,
int _numSamples,
int _precalcValBufSize, int _precalcIdxBufSize,
const CvCascadeBoostParams& _params )
{
bool isTrained = false;
CV_Assert( !data );
clear();
// 样本的数据都存在 _featureEvaluator 里面,这里把训练相关的数据都
// 用CvCascadeBoostTrainData类封装,内部创建了运行时需要的一些内存
// 方便后面使用
data = new CvCascadeBoostTrainData( _featureEvaluator, _numSamples,
_precalcValBufSize, _precalcIdxBufSize, _params );
CvMemStorage *storage = cvCreateMemStorage();
// 创建一个 CvSeq 序列,存放一个强分类器的所有弱分类器
weak = cvCreateSeq( 0, sizeof(CvSeq), sizeof(CvBoostTree*), storage );
storage = 0;
set_params( _params );
if ( (_params.boost_type == LOGIT) || (_params.boost_type == GENTLE) )
{
// 从_featureEvaluator->cls 中拷贝样本的类别信息到 data->responses
// 因为这两种boost方法计算式把类别从0/1该为-1/+1使用
data->do_responses_copy();
}
// 设置所有样本初始权值为1/n
update_weights( 0 );
cout << "+----+---------+---------+" << endl;
cout << "| N | HR | FA |" << endl;
cout << "+----+---------+---------+" << endl;
do
{
// 训练一个弱分类器,弱分类器是棵CART树
CvCascadeBoostTree* tree = new CvCascadeBoostTree;
if( !tree->train( data, subsample_mask, this ) )
{
delete tree;
break;
}
// 得到弱分类器加入序列
cvSeqPush( weak, &tree );
// 根据boost公式更新样本数据的权值
update_weights( tree );
// 根据用户输入参数,把一定比例的(0.05)权值最小的样本去掉
trim_weights();
// subsample_mask 保存每个样本是否参数训练的标记(值为0/1)
// 没有可用样本了,退出训练
if( cvCountNonZero(subsample_mask) == 0 )
break;
} // 如果当前强分类器达到了设置的虚警率要求或弱分类数目达到上限停止
while( !isErrDesired() && (weak->total < params.weak_count) );
if(weak->total > 0)
{
data->is_classifier = true;
data->free_train_data();
isTrained = true;
}
else
clear();
return isTrained;
}
代码中首先把训练相关的数据用CvCascadeBoostTrainData封装,一遍后面传递给其它函数,将每个样本的权值设置为1/N,N为总样本数。此后便开始进入弱分类器训练循环。我们接着来看弱分类器的训练,代码位于CvCascadeBoostTree::train中。
[cpp] view plain copy print?
- bool
- CvBoostTree::train( CvDTreeTrainData* _train_data,
- const CvMat* _subsample_idx, CvBoost* _ensemble )
- {
- clear();
- ensemble = _ensemble;
- data = _train_data;
- data->shared = true;
- return do_train( _subsample_idx );
- }
bool
CvBoostTree::train( CvDTreeTrainData* _train_data,
const CvMat* _subsample_idx, CvBoost* _ensemble )
{
clear();
ensemble = _ensemble;
data = _train_data;
data->shared = true;
return do_train( _subsample_idx );
}
注意这里的参数_ensemble实际是CvCascadeBoost类型的指针,转入调用CvBoostTree::do_train函数,传入的参数为参与训练的样本的索引数组,具体代码如下:
[cpp] view plain copy print?
- bool CvDTree::do_train( const CvMat* _subsample_idx )
- {
- bool result = false;
- CV_FUNCNAME( "CvDTree::do_train" );
- __BEGIN__;
- // 创建CART树根节点,设置根节点是数据为输入数据集
- root = data->subsample_data( _subsample_idx );
- // 开始分割节点,向树上增加子节点,构成CART树。如果设置弱分类器
- CV_CALL( try_split_node(root));
- if( root->split )
- {
- CV_Assert( root->left );
- CV_Assert( root->right );
- if( data->params.cv_folds > 0 )
- CV_CALL( prune_cv() );
- if( !data->shared )
- data->free_train_data();
- result = true;
- }
- __END__;
- return result;
- }
bool CvDTree::do_train( const CvMat* _subsample_idx )
{
bool result = false;
CV_FUNCNAME( "CvDTree::do_train" );
__BEGIN__;
// 创建CART树根节点,设置根节点是数据为输入数据集
root = data->subsample_data( _subsample_idx );
// 开始分割节点,向树上增加子节点,构成CART树。如果设置弱分类器
CV_CALL( try_split_node(root));
if( root->split )
{
CV_Assert( root->left );
CV_Assert( root->right );
if( data->params.cv_folds > 0 )
CV_CALL( prune_cv() );
if( !data->shared )
data->free_train_data();
result = true;
}
__END__;
return result;
}
创建一个root节点后,对root节点进行分割,调用try_split_node函数实现,代码如下:
[cpp] view plain copy print?
- void CvDTree::try_split_node( CvDTreeNode* node )
- {
- CvDTreeSplit* best_split = 0;
- int i, n = node->sample_count, vi;
- bool can_split = true;
- double quality_scale;
- // 计算当前节点的 value,节点的风险 node_risk
- calc_node_value( node );
- // 节点样本数目过少样本数(默认为10) 或者树深度达到设置值(默认为1),也就是一个分割节点
- if( node->sample_count <= data->params.min_sample_count ||
- node->depth >= data->params.max_depth )
- can_split = false;
- // is_classifer:false
- if( can_split && data->is_classifier )
- {
- // check if we have a "pure" node,
- // we assume that cls_count is filled by calc_node_value()
- int* cls_count = data->counts->data.i;
- int nz = 0, m = data->get_num_classes();
- for( i = 0; i < m; i++ )
- nz += cls_count[i] != 0;
- if( nz == 1 ) // there is only one class
- can_split = false;
- }
- else if( can_split )
- {
- // 平均error值很小了,说明已经分得很好,没必要继续下去 regression_accuracy (0.01)
- if( sqrt(node->node_risk)/n < data->params.regression_accuracy )
- can_split = false;
- }
- if( can_split )
- {
- // 调用函数找到最优分割,弱分类器训练的重头戏
- best_split = find_best_split(node);
- // TODO: check the split quality ...
- node->split = best_split;
- }
- if( !can_split || !best_split )
- {
- data->free_node_data(node);
- return;
- }
- // ignore this
- quality_scale = calc_node_dir( node );
- // 级联参数 use_surrogates = use_1se_rule = truncate_pruned_tree = false;
- if( data->params.use_surrogates )
- {
- // find all the surrogate splits
- // and sort them by their similarity to the primary one
- for( vi = 0; vi < data->var_count; vi++ )
- {
- CvDTreeSplit* split;
- int ci = data->get_var_type(vi);
- if( vi == best_split->var_idx )
- continue;
- if( ci >= 0 )
- split = find_surrogate_split_cat( node, vi );
- else
- split = find_surrogate_split_ord( node, vi );
- if( split )
- {
- // insert the split
- CvDTreeSplit* prev_split = node->split;
- split->quality = (float)(split->quality*quality_scale);
- while( prev_split->next &&
- prev_split->next->quality > split->quality )
- prev_split = prev_split->next;
- split->next = prev_split->next;
- prev_split->next = split;
- }
- }
- }
- // 创建左右子节点,把node的节点的数据分给left,right子节点
- split_node_data( node );
- // 递归实现子节点划分,分割左右子节点
- try_split_node( node->left );
- try_split_node( node->right );
- }
void CvDTree::try_split_node( CvDTreeNode* node )
{
CvDTreeSplit* best_split = 0;
int i, n = node->sample_count, vi;
bool can_split = true;
double quality_scale;
// 计算当前节点的 value,节点的风险 node_risk
calc_node_value( node );
// 节点样本数目过少样本数(默认为10) 或者树深度达到设置值(默认为1),也就是一个分割节点
if( node->sample_count <= data->params.min_sample_count ||
node->depth >= data->params.max_depth )
can_split = false;
// is_classifer:false
if( can_split && data->is_classifier )
{
// check if we have a "pure" node,
// we assume that cls_count is filled by calc_node_value()
int* cls_count = data->counts->data.i;
int nz = 0, m = data->get_num_classes();
for( i = 0; i < m; i++ )
nz += cls_count[i] != 0;
if( nz == 1 ) // there is only one class
can_split = false;
}
else if( can_split )
{
// 平均error值很小了,说明已经分得很好,没必要继续下去 regression_accuracy (0.01)
if( sqrt(node->node_risk)/n < data->params.regression_accuracy )
can_split = false;
}
if( can_split )
{
// 调用函数找到最优分割,弱分类器训练的重头戏
best_split = find_best_split(node);
// TODO: check the split quality ...
node->split = best_split;
}
if( !can_split || !best_split )
{
data->free_node_data(node);
return;
}
// ignore this
quality_scale = calc_node_dir( node );
// 级联参数 use_surrogates = use_1se_rule = truncate_pruned_tree = false;
if( data->params.use_surrogates )
{
// find all the surrogate splits
// and sort them by their similarity to the primary one
for( vi = 0; vi < data->var_count; vi++ )
{
CvDTreeSplit* split;
int ci = data->get_var_type(vi);
if( vi == best_split->var_idx )
continue;
if( ci >= 0 )
split = find_surrogate_split_cat( node, vi );
else
split = find_surrogate_split_ord( node, vi );
if( split )
{
// insert the split
CvDTreeSplit* prev_split = node->split;
split->quality = (float)(split->quality*quality_scale);
while( prev_split->next &&
prev_split->next->quality > split->quality )
prev_split = prev_split->next;
split->next = prev_split->next;
prev_split->next = split;
}
}
}
// 创建左右子节点,把node的节点的数据分给left,right子节点
split_node_data( node );
// 递归实现子节点划分,分割左右子节点
try_split_node( node->left );
try_split_node( node->right );
}
创建一个新的分割节点最为关键的就是要找到一个特征和阈值的组合,该分割能够把数据划分得最好(在误差的意义上),在find_best_split(node)中实现,我们看代码:
[cpp] view plain copy print?
- CvDTreeSplit* CvDTree::find_best_split( CvDTreeNode* node )
- {
- DTreeBestSplitFinder finder( this, node );
- // 在开启TBB情况下,多核并行处理
- cv::parallel_reduce(cv::BlockedRange(0, data->var_count), finder);
- // 保存最优分割
- CvDTreeSplit *bestSplit = 0;
- if( finder.bestSplit->quality > 0 )
- {
- bestSplit = data->new_split_cat( 0, -1.0f );
- memcpy( bestSplit, finder.bestSplit, finder.splitSize );
- }
- return bestSplit;
- }
CvDTreeSplit* CvDTree::find_best_split( CvDTreeNode* node )
{
DTreeBestSplitFinder finder( this, node );
// 在开启TBB情况下,多核并行处理
cv::parallel_reduce(cv::BlockedRange(0, data->var_count), finder);
// 保存最优分割
CvDTreeSplit *bestSplit = 0;
if( finder.bestSplit->quality > 0 )
{
bestSplit = data->new_split_cat( 0, -1.0f );
memcpy( bestSplit, finder.bestSplit, finder.splitSize );
}
return bestSplit;
}
关键代码位于的DTreeBestSplitFinder::operator()函数中,代码遍历特征序号为range.begin()--range.end()之间的特征,调用tree->find_split_ord_reg函数对特征vi找到最优的阈值。
[cpp] view plain copy print?
- void DTreeBestSplitFinder::operator()(const BlockedRange& range)
- {
- int vi, vi1 = range.begin(), vi2 = range.end();
- int n = node->sample_count;
- CvDTreeTrainData* data = tree->get_data();
- AutoBuffer<uchar> inn_buf(2*n*(sizeof(int) + sizeof(float)));
- // 遍历特征 vi
- for( vi = vi1; vi < vi2; vi++ )
- {
- CvDTreeSplit *res;
- // 取特征 数值特征为 -(vi+1) < 0,编码类型特征 vi >= 0,仅用作标识
- int ci = data->get_var_type(vi);
- if( node->get_num_valid(vi) <= 1 )
- continue;
- if( data->is_classifier )
- {
- if( ci >= 0 )
- res = tree->find_split_cat_class( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
- else
- res = tree->find_split_ord_class( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
- }
- else
- {
- if( ci >= 0 )
- res = tree->find_split_cat_reg( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
- else // 找到特征vi对应的最优分割,也就是求取最优阈值
- res = tree->find_split_ord_reg( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
- }
- // 更新bestSplit为quality最高的分割
- if( res && bestSplit->quality < split->quality )
- memcpy( (CvDTreeSplit*)bestSplit, (CvDTreeSplit*)split, splitSize );
- }
- }
- DTreeBestSplitFinder::join函数的作用是在使用TBB库并行计算时,把不同线程的运行结果进行合并,保存最优结果,这里保留quality更好的分割节点。
- void DTreeBestSplitFinder::join( DTreeBestSplitFinder& rhs )
- {
- if( bestSplit->quality < rhs.bestSplit->quality )
- memcpy( (CvDTreeSplit*)bestSplit, (CvDTreeSplit*)rhs.bestSplit, splitSize );
- }
void DTreeBestSplitFinder::operator()(const BlockedRange& range)
{
int vi, vi1 = range.begin(), vi2 = range.end();
int n = node->sample_count;
CvDTreeTrainData* data = tree->get_data();
AutoBuffer<uchar> inn_buf(2*n*(sizeof(int) + sizeof(float)));
// 遍历特征 vi
for( vi = vi1; vi < vi2; vi++ )
{
CvDTreeSplit *res;
// 取特征 数值特征为 -(vi+1) < 0,编码类型特征 vi >= 0,仅用作标识
int ci = data->get_var_type(vi);
if( node->get_num_valid(vi) <= 1 )
continue;
if( data->is_classifier )
{
if( ci >= 0 )
res = tree->find_split_cat_class( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
else
res = tree->find_split_ord_class( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
}
else
{
if( ci >= 0 )
res = tree->find_split_cat_reg( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
else // 找到特征vi对应的最优分割,也就是求取最优阈值
res = tree->find_split_ord_reg( node, vi, bestSplit->quality, split, (uchar*)inn_buf );
}
// 更新bestSplit为quality最高的分割
if( res && bestSplit->quality < split->quality )
memcpy( (CvDTreeSplit*)bestSplit, (CvDTreeSplit*)split, splitSize );
}
}
DTreeBestSplitFinder::join函数的作用是在使用TBB库并行计算时,把不同线程的运行结果进行合并,保存最优结果,这里保留quality更好的分割节点。
void DTreeBestSplitFinder::join( DTreeBestSplitFinder& rhs )
{
if( bestSplit->quality < rhs.bestSplit->quality )
memcpy( (CvDTreeSplit*)bestSplit, (CvDTreeSplit*)rhs.bestSplit, splitSize );
}
Haar特征的值两个(或三个)矩形区域均值之差,是一个浮点数值。对所有样本求取特征值得到一个数组,一个分割就是找到一个最有的阈值把数据分成左右两部分,使得两边的总体误差最小。回顾一下原理部分讲过的例子,红色为正样本,绿色为负样本,阈值就是找一条垂直x轴的分割线。
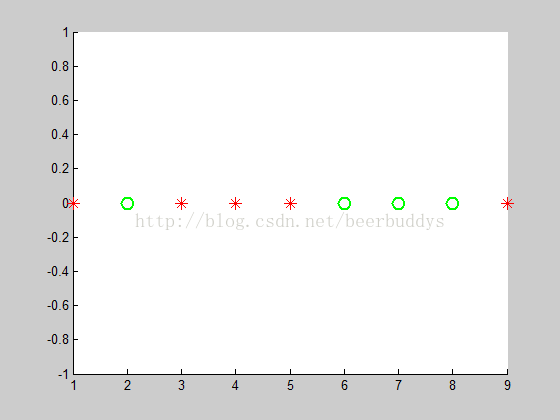
Haar特征值数据
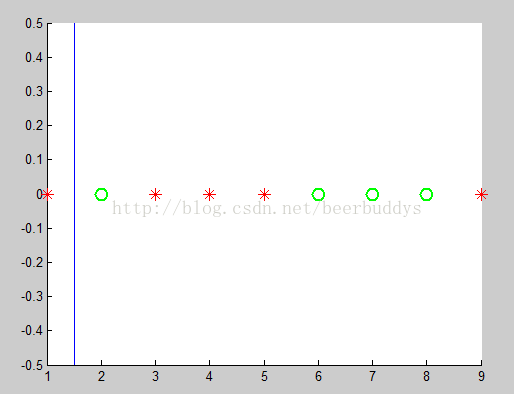
取阈值为1.5
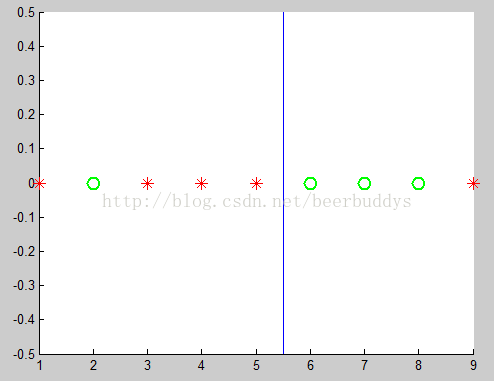
取阈值为5.5
代码首先调用get_ord_var_data计算当期节点上所有样本的第vi个haar特征值,然后按照从小到大排序返回排序后的值数组values,然后根据values找到最优分割阈值(也就是移动图中的蓝色分割线)。代码依次测试最优阈值为values[i]和values[i+1]的中值,找到最小化总体误差的一个,返回得到的split。
[cpp] view plain copy print?
- CvDTreeSplit*
- CvBoostTree::find_split_ord_reg( CvDTreeNode* node, int vi, float init_quality, CvDTreeSplit* _split, uchar* _ext_buf )
- {
- const float epsilon = FLT_EPSILON*2;
- const double* weights = ensemble->get_subtree_weights()->data.db;
- int n = node->sample_count;
- int n1 = node->get_num_valid(vi);
- cv::AutoBuffer<uchar> inn_buf;
- if( !_ext_buf )
- inn_buf.allocate(2*n*(sizeof(int)+sizeof(float)));
- uchar* ext_buf = _ext_buf ? _ext_buf : (uchar*)inn_buf;
- float* values_buf = (float*)ext_buf;
- int* indices_buf = (int*)(values_buf + n);
- int* sample_indices_buf = indices_buf + n;
- const float* values = 0;
- const int* indices = 0;
- // 计算所有样本的第vi个haar特征值,values为特征值数组,已经从小到大排序
- data->get_ord_var_data( node, vi, values_buf, indices_buf, &values, &indices, sample_indices_buf );
- float* responses_buf = (float*)(indices_buf + n);
- // 取所有样本的真是响应值(+1/-1)
- const float* responses = data->get_ord_responses( node, responses_buf, sample_indices_buf );
- int i, best_i = -1;
- double L = 0, R = weights[n]; // R 为总权值和
- double best_val = init_quality, lsum = 0, rsum = node->value*R;
- // compensate for missing values
- for( i = n1; i < n; i++ )
- {
- int idx = indices[i];
- double w = weights[idx];
- rsum -= responses[idx]*w;
- R -= w;
- }
- // find the optimal split
- for( i = 0; i < n1 - 1; i++ )
- {
- int idx = indices[i];
- double w = weights[idx];
- double t = responses[idx]*w;
- L += w; R -= w; // L为左边权值和,R为右边权值和
- lsum += t; rsum -= t; // lsum左边正样本权值和-负样本权值和
- // rsum右边正样本权值和-负样本权值和
- if( values[i] + epsilon < values[i+1] )
- {
- // 计算当前分割下的error
- double val = (lsum*lsum*R + rsum*rsum*L)/(L*R);
- if( best_val < val )
- {
- best_val = val;
- best_i = i;
- }
- }
- }
- CvDTreeSplit* split = 0;
- if( best_i >= 0 )
- {
- split = _split ? _split : data->new_split_ord( 0, 0.0f, 0, 0, 0.0f );
- split->var_idx = vi;
- // 最优阈值取前后两个特征值的中间值
- split->ord.c = (values[best_i] + values[best_i+1])*0.5f;
- split->ord.split_point = best_i; // 最优特征值序号
- split->inversed = 0;
- split->quality = (float)best_val;// 最小error
- }
- return split;
- }
CvDTreeSplit*
CvBoostTree::find_split_ord_reg( CvDTreeNode* node, int vi, float init_quality, CvDTreeSplit* _split, uchar* _ext_buf )
{
const float epsilon = FLT_EPSILON*2;
const double* weights = ensemble->get_subtree_weights()->data.db;
int n = node->sample_count;
int n1 = node->get_num_valid(vi);
cv::AutoBuffer<uchar> inn_buf;
if( !_ext_buf )
inn_buf.allocate(2*n*(sizeof(int)+sizeof(float)));
uchar* ext_buf = _ext_buf ? _ext_buf : (uchar*)inn_buf;
float* values_buf = (float*)ext_buf;
int* indices_buf = (int*)(values_buf + n);
int* sample_indices_buf = indices_buf + n;
const float* values = 0;
const int* indices = 0;
// 计算所有样本的第vi个haar特征值,values为特征值数组,已经从小到大排序
data->get_ord_var_data( node, vi, values_buf, indices_buf, &values, &indices, sample_indices_buf );
float* responses_buf = (float*)(indices_buf + n);
// 取所有样本的真是响应值(+1/-1)
const float* responses = data->get_ord_responses( node, responses_buf, sample_indices_buf );
int i, best_i = -1;
double L = 0, R = weights[n]; // R 为总权值和
double best_val = init_quality, lsum = 0, rsum = node->value*R;
// compensate for missing values
for( i = n1; i < n; i++ )
{
int idx = indices[i];
double w = weights[idx];
rsum -= responses[idx]*w;
R -= w;
}
// find the optimal split
for( i = 0; i < n1 - 1; i++ )
{
int idx = indices[i];
double w = weights[idx];
double t = responses[idx]*w;
L += w; R -= w; // L为左边权值和,R为右边权值和
lsum += t; rsum -= t; // lsum左边正样本权值和-负样本权值和
// rsum右边正样本权值和-负样本权值和
if( values[i] + epsilon < values[i+1] )
{
// 计算当前分割下的error
double val = (lsum*lsum*R + rsum*rsum*L)/(L*R);
if( best_val < val )
{
best_val = val;
best_i = i;
}
}
}
CvDTreeSplit* split = 0;
if( best_i >= 0 )
{
split = _split ? _split : data->new_split_ord( 0, 0.0f, 0, 0, 0.0f );
split->var_idx = vi;
// 最优阈值取前后两个特征值的中间值
split->ord.c = (values[best_i] + values[best_i+1])*0.5f;
split->ord.split_point = best_i; // 最优特征值序号
split->inversed = 0;
split->quality = (float)best_val;// 最小error
}
return split;
}
我们再来看看如何求取haar特征的,get_ord_var_data函数代码较长,没有注释的部分大可直接略过,直接看注释部分,调用(*featureEvaluator)( vi, sampleIndices[i])计算第smapleIndices[i]个样本的第vi个特征值。计算完成后,调用icvSortIntAux按照从小到大排序。
[cpp] view plain copy print?
- void CvCascadeBoostTrainData::get_ord_var_data( CvDTreeNode* n, int vi, float* ordValuesBuf, int* sortedIndicesBuf,
- const float** ordValues, const int** sortedIndices, int* sampleIndicesBuf )
- {
- int nodeSampleCount = n->sample_count;
- const int* sampleIndices = get_sample_indices(n, sampleIndicesBuf);
- if ( vi < numPrecalcIdx )
- {
- if( !is_buf_16u )
- *sortedIndices = buf->data.i + n->buf_idx*get_length_subbuf() + vi*sample_count + n->offset;
- else
- {
- const unsigned short* shortIndices = (const unsigned short*)(buf->data.s + n->buf_idx*get_length_subbuf() +
- vi*sample_count + n->offset );
- for( int i = 0; i < nodeSampleCount; i++ )
- sortedIndicesBuf[i] = shortIndices[i];
- *sortedIndices = sortedIndicesBuf;
- }
- if( vi < numPrecalcVal )
- {
- for( int i = 0; i < nodeSampleCount; i++ )
- {
- int idx = (*sortedIndices)[i];
- idx = sampleIndices[idx];
- ordValuesBuf[i] = valCache.at<float>( vi, idx);
- }
- }
- else
- {
- for( int i = 0; i < nodeSampleCount; i++ )
- {
- int idx = (*sortedIndices)[i];
- idx = sampleIndices[idx];
- ordValuesBuf[i] = (*featureEvaluator)( vi, idx);
- }
- }
- }
- else // vi >= numPrecalcIdx 特征没有计算 valCache
- {
- cv::AutoBuffer<float> abuf(nodeSampleCount);
- float* sampleValues = &abuf[0];
- if ( vi < numPrecalcVal )
- {
- for( int i = 0; i < nodeSampleCount; i++ )
- {
- sortedIndicesBuf[i] = i;
- sampleValues[i] = valCache.at<float>( vi, sampleIndices[i] );
- }
- }
- else
- { // 计算节点样本的特征值,通过featureEvaluator.operator()得到
- // 样本索引存在sampleIndices里面
- for( int i = 0; i < nodeSampleCount; i++ )
- {
- sortedIndicesBuf[i] = i;
- // 调用featureEvaluator.operator()计算第vi个haar特征值
- sampleValues[i] = (*featureEvaluator)( vi, sampleIndices[i]);
- }
- }
- // 对索引进行排序,特征值从小到大,sampleValues 里面放的是特征值
- // icvSortIntAux 根据sampleValues的值排序
- icvSortIntAux( sortedIndicesBuf, nodeSampleCount, &sampleValues[0] );
- for( int i = 0; i < nodeSampleCount; i++ )
- ordValuesBuf[i] = (&sampleValues[0])[sortedIndicesBuf[i]];
- *sortedIndices = sortedIndicesBuf;
- }
- // *sortedIndices 样本排序后的索引数组,指示特征值在排序中的位置
- // *ordValues 特征值排序结果,用户计算最优分割
- *ordValues = ordValuesBuf;
- }
void CvCascadeBoostTrainData::get_ord_var_data( CvDTreeNode* n, int vi, float* ordValuesBuf, int* sortedIndicesBuf,
const float** ordValues, const int** sortedIndices, int* sampleIndicesBuf )
{
int nodeSampleCount = n->sample_count;
const int* sampleIndices = get_sample_indices(n, sampleIndicesBuf);
if ( vi < numPrecalcIdx )
{
if( !is_buf_16u )
*sortedIndices = buf->data.i + n->buf_idx*get_length_subbuf() + vi*sample_count + n->offset;
else
{
const unsigned short* shortIndices = (const unsigned short*)(buf->data.s + n->buf_idx*get_length_subbuf() +
vi*sample_count + n->offset );
for( int i = 0; i < nodeSampleCount; i++ )
sortedIndicesBuf[i] = shortIndices[i];
*sortedIndices = sortedIndicesBuf;
}
if( vi < numPrecalcVal )
{
for( int i = 0; i < nodeSampleCount; i++ )
{
int idx = (*sortedIndices)[i];
idx = sampleIndices[idx];
ordValuesBuf[i] = valCache.at<float>( vi, idx);
}
}
else
{
for( int i = 0; i < nodeSampleCount; i++ )
{
int idx = (*sortedIndices)[i];
idx = sampleIndices[idx];
ordValuesBuf[i] = (*featureEvaluator)( vi, idx);
}
}
}
else // vi >= numPrecalcIdx 特征没有计算 valCache
{
cv::AutoBuffer<float> abuf(nodeSampleCount);
float* sampleValues = &abuf[0];
if ( vi < numPrecalcVal )
{
for( int i = 0; i < nodeSampleCount; i++ )
{
sortedIndicesBuf[i] = i;
sampleValues[i] = valCache.at<float>( vi, sampleIndices[i] );
}
}
else
{ // 计算节点样本的特征值,通过featureEvaluator.operator()得到
// 样本索引存在sampleIndices里面
for( int i = 0; i < nodeSampleCount; i++ )
{
sortedIndicesBuf[i] = i;
// 调用featureEvaluator.operator()计算第vi个haar特征值
sampleValues[i] = (*featureEvaluator)( vi, sampleIndices[i]);
}
}
// 对索引进行排序,特征值从小到大,sampleValues 里面放的是特征值
// icvSortIntAux 根据sampleValues的值排序
icvSortIntAux( sortedIndicesBuf, nodeSampleCount, &sampleValues[0] );
for( int i = 0; i < nodeSampleCount; i++ )
ordValuesBuf[i] = (&sampleValues[0])[sortedIndicesBuf[i]];
*sortedIndices = sortedIndicesBuf;
}
// *sortedIndices 样本排序后的索引数组,指示特征值在排序中的位置
// *ordValues 特征值排序结果,用户计算最优分割
*ordValues = ordValuesBuf;
}
计算特征值
回顾一下haar特征,两个或三个矩形加权求和。权值的作用是为了平衡区域的面积,例如A和B两个特征,黑白面积一样,权值都为1:1,而C特征,实际是用包含黑色的大矩形去减中间的黑色矩形,因此权值为1:3,也就是黑色矩形权值为3。
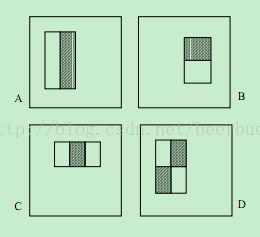
前面提到过使用积分图来加速求取一个矩形内的灰度和。积分图中每个点(x,y)保存的是从(0,0)开始的矩形的灰度和。

在积分图上求一个矩形内灰度和在积分图上只需要四个点进行运算,例如矩形D的和为v[4]+v[1]-v[2]-v[3]。其中v[]表示积分图对应的值。
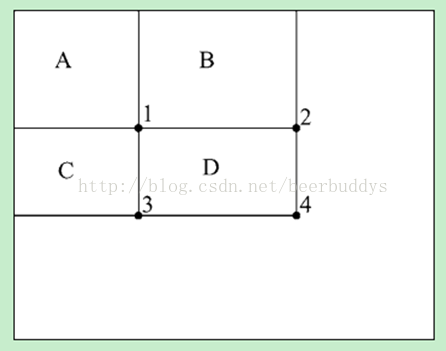
现在来看代码的实现,调用calc函数计算矩形区域的加权和,为了加快计算,矩形不是使用起点和宽高表示,创建了fastRect结构来保存上图中1234四个点相对于图像原点的偏离量,记作p0,p1,p2,p3。
得到加权和之后,在operator()函数中还除以了normfactor归一化系数,这一值就是图像的标准差,去除因不同对比度造成的差异。
[cpp] view plain copy print?
- inline float CvHaarEvaluator::operator()(int featureIdx, int sampleIdx) const
- {
- float nf = normfactor.at<float>(0, sampleIdx);
- return !nf ? 0.0f : (features[featureIdx].calc( sum, tilted, sampleIdx)/nf);
- }
- inline float CvHaarEvaluator::Feature::calc( const cv::Mat &_sum, const cv::Mat &_tilted, size_t y) const
- {
- const int* img = tilted ? _tilted.ptr<int>((int)y) : _sum.ptr<int>((int)y);
- float ret = rect[0].weight * (img[fastRect[0].p0] - img[fastRect[0].p1] - img[fastRect[0].p2] + img[fastRect[0].p3] ) +
- rect[1].weight * (img[fastRect[1].p0] - img[fastRect[1].p1] - img[fastRect[1].p2] + img[fastRect[1].p3] );
- if( rect[2].weight != 0.0f )
- ret += rect[2].weight * (img[fastRect[2].p0] - img[fastRect[2].p1] - img[fastRect[2].p2] + img[fastRect[2].p3] );
- return ret;
- }
inline float CvHaarEvaluator::operator()(int featureIdx, int sampleIdx) const
{
float nf = normfactor.at<float>(0, sampleIdx);
return !nf ? 0.0f : (features[featureIdx].calc( sum, tilted, sampleIdx)/nf);
}
inline float CvHaarEvaluator::Feature::calc( const cv::Mat &_sum, const cv::Mat &_tilted, size_t y) const
{
const int* img = tilted ? _tilted.ptr<int>((int)y) : _sum.ptr<int>((int)y);
float ret = rect[0].weight * (img[fastRect[0].p0] - img[fastRect[0].p1] - img[fastRect[0].p2] + img[fastRect[0].p3] ) +
rect[1].weight * (img[fastRect[1].p0] - img[fastRect[1].p1] - img[fastRect[1].p2] + img[fastRect[1].p3] );
if( rect[2].weight != 0.0f )
ret += rect[2].weight * (img[fastRect[2].p0] - img[fastRect[2].p1] - img[fastRect[2].p2] + img[fastRect[2].p3] );
return ret;
}
代码走到这里,一个弱分类器的流程就全部走完了。我们得到了一个弱分类器。我们继续回到强分类器训练流程中看看接下来做了什么工作。
[cpp] view plain copy print?
- bool CvCascadeBoost::train( const CvFeatureEvaluator* _featureEvaluator,
- int _numSamples,
- int _precalcValBufSize, int _precalcIdxBufSize,
- const CvCascadeBoostParams& _params )
- {
- bool isTrained = false;
- // ...此前代码略过
- // 设置所有样本初始权值为1/n
- update_weights( 0 );
- cout << "+----+---------+---------+" << endl;
- cout << "| N | HR | FA |" << endl;
- cout << "+----+---------+---------+" << endl;
- do
- {
- // 训练一个弱分类器,弱分类器是棵CART树
- CvCascadeBoostTree* tree = new CvCascadeBoostTree;
- if( !tree->train( data, subsample_mask, this ) )
- {
- delete tree;
- break;
- }
- // 得到弱分类器加入序列
- cvSeqPush( weak, &tree );
- // 根据boost公式更新样本数据的权值
- update_weights( tree );
- // 根据用户输入参数,把一定比例的(0.05)权值最小的样本去掉
- trim_weights();
- // subsample_mask 保存每个样本是否参数训练的标记(值为0/1)
- // 没有可用样本了,退出训练
- if( cvCountNonZero(subsample_mask) == 0 )
- break;
- } // 如果当前强分类器达到了设置的虚警率要求或弱分类数目达到上限停止
- while( !isErrDesired() && (weak->total < params.weak_count) );
- if(weak->total > 0)
- {
- data->is_classifier = true;
- data->free_train_data();
- isTrained = true;
- }
- else
- clear();
- return isTrained;
- }
bool CvCascadeBoost::train( const CvFeatureEvaluator* _featureEvaluator,
int _numSamples,
int _precalcValBufSize, int _precalcIdxBufSize,
const CvCascadeBoostParams& _params )
{
bool isTrained = false;
// ...此前代码略过
// 设置所有样本初始权值为1/n
update_weights( 0 );
cout << "+----+---------+---------+" << endl;
cout << "| N | HR | FA |" << endl;
cout << "+----+---------+---------+" << endl;
do
{
// 训练一个弱分类器,弱分类器是棵CART树
CvCascadeBoostTree* tree = new CvCascadeBoostTree;
if( !tree->train( data, subsample_mask, this ) )
{
delete tree;
break;
}
// 得到弱分类器加入序列
cvSeqPush( weak, &tree );
// 根据boost公式更新样本数据的权值
update_weights( tree );
// 根据用户输入参数,把一定比例的(0.05)权值最小的样本去掉
trim_weights();
// subsample_mask 保存每个样本是否参数训练的标记(值为0/1)
// 没有可用样本了,退出训练
if( cvCountNonZero(subsample_mask) == 0 )
break;
} // 如果当前强分类器达到了设置的虚警率要求或弱分类数目达到上限停止
while( !isErrDesired() && (weak->total < params.weak_count) );
if(weak->total > 0)
{
data->is_classifier = true;
data->free_train_data();
isTrained = true;
}
else
clear();
return isTrained;
}
首先将得到的弱分类器加入序列weak,然后根据Adaboost公式(我们采用的Gentle adaboost)更新所有样本的权值,为下一轮弱分类器训练作准备。更新权值调用trim_weights函数,根据的设置,将一定比例的权值很小的样本从训练集中去除(能够提高训练的速度,对性能有一定的影响)。
我们来看权值更新是如何进行的。当传入tree为0时,设置每个样本权值为1/n。得到一个弱分类器后,传入上一个弱分类器tree,样本i更新后的为:w_i *= exp(-y_i*f(x_i)),其中y_i为样本的真实响应(+1/-1值)f(x_i)表示输入的弱分类器tree对样本i的响应值。最后将调整后的样本总权值调整为1。
[cpp] view plain copy print?
- void CvCascadeBoost::update_weights( CvBoostTree* tree )
- {
- int n = data->sample_count;
- double sumW = 0.;
- int step = 0;
- float* fdata = 0;
- int *sampleIdxBuf;
- const int* sampleIdx = 0;
- int inn_buf_size = ((params.boost_type == LOGIT) || (params.boost_type == GENTLE) ? n*sizeof(int) : 0) +
- ( !tree ? n*sizeof(int) : 0 );
- cv::AutoBuffer<uchar> inn_buf(inn_buf_size);
- uchar* cur_inn_buf_pos = (uchar*)inn_buf;
- if ( (params.boost_type == LOGIT) || (params.boost_type == GENTLE) )
- {
- step = CV_IS_MAT_CONT(data->responses_copy->type) ?
- 1 : data->responses_copy->step / CV_ELEM_SIZE(data->responses_copy->type);
- // data->responses_copy = data->responses 为样本的真实相应(正样本+1,负样本-1)
- fdata = data->responses_copy->data.fl;
- sampleIdxBuf = (int*)cur_inn_buf_pos; cur_inn_buf_pos = (uchar*)(sampleIdxBuf + n);
- sampleIdx = data->get_sample_indices( data->data_root, sampleIdxBuf );
- }
- CvMat* buf = data->buf;
- size_t length_buf_row = data->get_length_subbuf();
- if( !tree ) // before training the first tree, initialize weights and other parameters
- {
- int* classLabelsBuf = (int*)cur_inn_buf_pos; cur_inn_buf_pos = (uchar*)(classLabelsBuf + n);
- // 实际上也是取data->responses数据指针,此时正样本为1,负样本为0
- const int* classLabels = data->get_class_labels(data->data_root, classLabelsBuf);
- // in case of logitboost and gentle adaboost each weak tree is a regression tree,
- // so we need to convert class labels to floating-point values
- double w0 = 1./n;
- double p[2] = { 1, 1 };
- cvReleaseMat( &orig_response );
- cvReleaseMat( &sum_response );
- cvReleaseMat( &weak_eval );
- cvReleaseMat( &subsample_mask );
- cvReleaseMat( &weights );
- orig_response = cvCreateMat( 1, n, CV_32S );
- weak_eval = cvCreateMat( 1, n, CV_64F );
- subsample_mask = cvCreateMat( 1, n, CV_8U );
- weights = cvCreateMat( 1, n, CV_64F );
- subtree_weights = cvCreateMat( 1, n + 2, CV_64F );
- if (data->is_buf_16u)
- {
- unsigned short* labels = (unsigned short*)(buf->data.s + data->data_root->buf_idx*length_buf_row +
- data->data_root->offset + (data->work_var_count-1)*data->sample_count);
- for( int i = 0; i < n; i++ )
- {
- // save original categorical responses {0,1}, convert them to {-1,1}
- // 将样本标签{0,1}转到{-1,+1}
- orig_response->data.i[i] = classLabels[i]*2 - 1;
- // make all the samples active at start.
- // later, in trim_weights() deactivate/reactive again some, if need
- // subsample_mask标识每个样本是否使用,为1表示参与训练
- subsample_mask->data.ptr[i] = (uchar)1;
- // make all the initial weights the same.
- // 设置样本的初始权值为1/n,每个样本权值一样
- weights->data.db[i] = w0*p[classLabels[i]];
- // set the labels to find (from within weak tree learning proc)
- // the particular sample weight, and where to store the response.
- labels[i] = (unsigned short)i;
- }
- }
- else
- {
- int* labels = buf->data.i + data->data_root->buf_idx*length_buf_row +
- data->data_root->offset + (data->work_var_count-1)*data->sample_count;
- for( int i = 0; i < n; i++ )
- {
- // save original categorical responses {0,1}, convert them to {-1,1}
- orig_response->data.i[i] = classLabels[i]*2 - 1;
- subsample_mask->data.ptr[i] = (uchar)1;
- weights->data.db[i] = w0*p[classLabels[i]];
- labels[i] = i;
- }
- }
- if( params.boost_type == LOGIT )
- {
- sum_response = cvCreateMat( 1, n, CV_64F );
- for( int i = 0; i < n; i++ )
- {
- sum_response->data.db[i] = 0;
- fdata[sampleIdx[i]*step] = orig_response->data.i[i] > 0 ? 2.f : -2.f;
- }
- // in case of logitboost each weak tree is a regression tree.
- // the target function values are recalculated for each of the trees
- data->is_classifier = false;
- }
- else if( params.boost_type == GENTLE )
- {
- // 设置 data->reponse 为{-1,+1}
- for( int i = 0; i < n; i++ )
- fdata[sampleIdx[i]*step] = (float)orig_response->data.i[i];
- data->is_classifier = false;
- }
- }
- else
- {
- // at this moment, for all the samples that participated in the training of the most
- // recent weak classifier we know the responses. For other samples we need to compute them
- if( have_subsample )
- {
- // invert the subsample mask
- cvXorS( subsample_mask, cvScalar(1.), subsample_mask );
- // run tree through all the non-processed samples
- for( int i = 0; i < n; i++ )
- if( subsample_mask->data.ptr[i] )
- {
- weak_eval->data.db[i] = ((CvCascadeBoostTree*)tree)->predict( i )->value;
- }
- }
- // ... 其他boost方式处理,忽略
- {
- // Gentle AdaBoost:
- // weak_eval[i] = f(x_i) in [-1,1]
- // w_i *= exp(-y_i*f(x_i))
- assert( params.boost_type == GENTLE );
- for( int i = 0; i < n; i++ )
- weak_eval->data.db[i] *= -orig_response->data.i[i];
- cvExp( weak_eval, weak_eval );
- for( int i = 0; i < n; i++ )
- {
- double w = weights->data.db[i] * weak_eval->data.db[i];
- weights->data.db[i] = w;
- sumW += w;
- }
- }
- }
- // renormalize weights
- if( sumW > FLT_EPSILON )
- {
- sumW = 1./sumW;
- for( int i = 0; i < n; ++i )
- weights->data.db[i] *= sumW;
- }
- }
void CvCascadeBoost::update_weights( CvBoostTree* tree )
{
int n = data->sample_count;
double sumW = 0.;
int step = 0;
float* fdata = 0;
int *sampleIdxBuf;
const int* sampleIdx = 0;
int inn_buf_size = ((params.boost_type == LOGIT) || (params.boost_type == GENTLE) ? n*sizeof(int) : 0) +
( !tree ? n*sizeof(int) : 0 );
cv::AutoBuffer<uchar> inn_buf(inn_buf_size);
uchar* cur_inn_buf_pos = (uchar*)inn_buf;
if ( (params.boost_type == LOGIT) || (params.boost_type == GENTLE) )
{
step = CV_IS_MAT_CONT(data->responses_copy->type) ?
1 : data->responses_copy->step / CV_ELEM_SIZE(data->responses_copy->type);
// data->responses_copy = data->responses 为样本的真实相应(正样本+1,负样本-1)
fdata = data->responses_copy->data.fl;
sampleIdxBuf = (int*)cur_inn_buf_pos; cur_inn_buf_pos = (uchar*)(sampleIdxBuf + n);
sampleIdx = data->get_sample_indices( data->data_root, sampleIdxBuf );
}
CvMat* buf = data->buf;
size_t length_buf_row = data->get_length_subbuf();
if( !tree ) // before training the first tree, initialize weights and other parameters
{
int* classLabelsBuf = (int*)cur_inn_buf_pos; cur_inn_buf_pos = (uchar*)(classLabelsBuf + n);
// 实际上也是取data->responses数据指针,此时正样本为1,负样本为0
const int* classLabels = data->get_class_labels(data->data_root, classLabelsBuf);
// in case of logitboost and gentle adaboost each weak tree is a regression tree,
// so we need to convert class labels to floating-point values
double w0 = 1./n;
double p[2] = { 1, 1 };
cvReleaseMat( &orig_response );
cvReleaseMat( &sum_response );
cvReleaseMat( &weak_eval );
cvReleaseMat( &subsample_mask );
cvReleaseMat( &weights );
orig_response = cvCreateMat( 1, n, CV_32S );
weak_eval = cvCreateMat( 1, n, CV_64F );
subsample_mask = cvCreateMat( 1, n, CV_8U );
weights = cvCreateMat( 1, n, CV_64F );
subtree_weights = cvCreateMat( 1, n + 2, CV_64F );
if (data->is_buf_16u)
{
unsigned short* labels = (unsigned short*)(buf->data.s + data->data_root->buf_idx*length_buf_row +
data->data_root->offset + (data->work_var_count-1)*data->sample_count);
for( int i = 0; i < n; i++ )
{
// save original categorical responses {0,1}, convert them to {-1,1}
// 将样本标签{0,1}转到{-1,+1}
orig_response->data.i[i] = classLabels[i]*2 - 1;
// make all the samples active at start.
// later, in trim_weights() deactivate/reactive again some, if need
// subsample_mask标识每个样本是否使用,为1表示参与训练
subsample_mask->data.ptr[i] = (uchar)1;
// make all the initial weights the same.
// 设置样本的初始权值为1/n,每个样本权值一样
weights->data.db[i] = w0*p[classLabels[i]];
// set the labels to find (from within weak tree learning proc)
// the particular sample weight, and where to store the response.
labels[i] = (unsigned short)i;
}
}
else
{
int* labels = buf->data.i + data->data_root->buf_idx*length_buf_row +
data->data_root->offset + (data->work_var_count-1)*data->sample_count;
for( int i = 0; i < n; i++ )
{
// save original categorical responses {0,1}, convert them to {-1,1}
orig_response->data.i[i] = classLabels[i]*2 - 1;
subsample_mask->data.ptr[i] = (uchar)1;
weights->data.db[i] = w0*p[classLabels[i]];
labels[i] = i;
}
}
if( params.boost_type == LOGIT )
{
sum_response = cvCreateMat( 1, n, CV_64F );
for( int i = 0; i < n; i++ )
{
sum_response->data.db[i] = 0;
fdata[sampleIdx[i]*step] = orig_response->data.i[i] > 0 ? 2.f : -2.f;
}
// in case of logitboost each weak tree is a regression tree.
// the target function values are recalculated for each of the trees
data->is_classifier = false;
}
else if( params.boost_type == GENTLE )
{
// 设置 data->reponse 为{-1,+1}
for( int i = 0; i < n; i++ )
fdata[sampleIdx[i]*step] = (float)orig_response->data.i[i];
data->is_classifier = false;
}
}
else
{
// at this moment, for all the samples that participated in the training of the most
// recent weak classifier we know the responses. For other samples we need to compute them
if( have_subsample )
{
// invert the subsample mask
cvXorS( subsample_mask, cvScalar(1.), subsample_mask );
// run tree through all the non-processed samples
for( int i = 0; i < n; i++ )
if( subsample_mask->data.ptr[i] )
{
weak_eval->data.db[i] = ((CvCascadeBoostTree*)tree)->predict( i )->value;
}
}
// ... 其他boost方式处理,忽略
{
// Gentle AdaBoost:
// weak_eval[i] = f(x_i) in [-1,1]
// w_i *= exp(-y_i*f(x_i))
assert( params.boost_type == GENTLE );
for( int i = 0; i < n; i++ )
weak_eval->data.db[i] *= -orig_response->data.i[i];
cvExp( weak_eval, weak_eval );
for( int i = 0; i < n; i++ )
{
double w = weights->data.db[i] * weak_eval->data.db[i];
weights->data.db[i] = w;
sumW += w;
}
}
}
// renormalize weights
if( sumW > FLT_EPSILON )
{
sumW = 1./sumW;
for( int i = 0; i < n; ++i )
weights->data.db[i] *= sumW;
}
}
没增加一个弱分类器都是对当前强分类器的增强,我们需要检查当前的强分类器是否已经足够强,也就是它能否满足设置的性能指标,命中率(也就是recall)和虚警率达到要求。在isErrorDisired函数中进行,我们来看个究竟。
[cpp] view plain copy print?
- bool CvCascadeBoost::isErrDesired()
- {
- int sCount = data->sample_count,
- numPos = 0, numNeg = 0, numFalse = 0, numPosTrue = 0;
- vector<float> eval(sCount);
- // 计算每个正样本的弱分类器输出之和,predict函数中完成
- for( int i = 0; i < sCount; i++ )
- if( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getCls( i ) == 1.0F )
- eval[numPos++] = predict( i, true );
- // 所有正样本的该值进行从小到大排序
- icvSortFlt( &eval[0], numPos, 0 );
- // 因为我们要求正样本通过强分类器的比例为minHitRate
- // 因此阈值应该取从小到大排序数组中的(1.0F - minHitRate)处的值
- int thresholdIdx = (int)((1.0F - minHitRate) * numPos);
- threshold = eval[ thresholdIdx ];
- numPosTrue = numPos - thresholdIdx;
- for( int i = thresholdIdx - 1; i >= 0; i--)
- if ( abs( eval[i] - threshold) < FLT_EPSILON )
- numPosTrue++;
- float hitRate = ((float) numPosTrue) / ((float) numPos);
- // 确定强分类器的阈值threshold之后,还需要计算虚警率,也就是负样本通过该
- // 阈值的比例。同样的调用predict
- for( int i = 0; i < sCount; i++ )
- {
- if( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getCls( i ) == 0.0F )
- {
- numNeg++;
- // 返回1表示通过,也就是弱分类器和大于设置阈值,此处表示负样本通过强分类器
- if( predict( i ) )
- numFalse++;
- }
- }
- // 虚警率 = 通过的负样本/总负样本数
- float falseAlarm = ((float) numFalse) / ((float) numNeg);
- cout << "|"; cout.width(4); cout << right << weak->total;
- cout << "|"; cout.width(9); cout << right << hitRate;
- cout << "|"; cout.width(9); cout << right << falseAlarm;
- cout << "|" << endl;
- cout << "+----+---------+---------+" << endl;
- return falseAlarm <= maxFalseAlarm;
- }
bool CvCascadeBoost::isErrDesired()
{
int sCount = data->sample_count,
numPos = 0, numNeg = 0, numFalse = 0, numPosTrue = 0;
vector<float> eval(sCount);
// 计算每个正样本的弱分类器输出之和,predict函数中完成
for( int i = 0; i < sCount; i++ )
if( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getCls( i ) == 1.0F )
eval[numPos++] = predict( i, true );
// 所有正样本的该值进行从小到大排序
icvSortFlt( &eval[0], numPos, 0 );
// 因为我们要求正样本通过强分类器的比例为minHitRate
// 因此阈值应该取从小到大排序数组中的(1.0F - minHitRate)处的值
int thresholdIdx = (int)((1.0F - minHitRate) * numPos);
threshold = eval[ thresholdIdx ];
numPosTrue = numPos - thresholdIdx;
for( int i = thresholdIdx - 1; i >= 0; i--)
if ( abs( eval[i] - threshold) < FLT_EPSILON )
numPosTrue++;
float hitRate = ((float) numPosTrue) / ((float) numPos);
// 确定强分类器的阈值threshold之后,还需要计算虚警率,也就是负样本通过该
// 阈值的比例。同样的调用predict
for( int i = 0; i < sCount; i++ )
{
if( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getCls( i ) == 0.0F )
{
numNeg++;
// 返回1表示通过,也就是弱分类器和大于设置阈值,此处表示负样本通过强分类器
if( predict( i ) )
numFalse++;
}
}
// 虚警率 = 通过的负样本/总负样本数
float falseAlarm = ((float) numFalse) / ((float) numNeg);
cout << "|"; cout.width(4); cout << right << weak->total;
cout << "|"; cout.width(9); cout << right << hitRate;
cout << "|"; cout.width(9); cout << right << falseAlarm;
cout << "|" << endl;
cout << "+----+---------+---------+" << endl;
return falseAlarm <= maxFalseAlarm;
}
来看一下强分类器是如何预测的,在predict函数中,依次调用每个弱分类器的predict来给出第当前样本的输出,统计输出值sum。如果设置返回是否通过,则将sum与强分类器阈值threshold比较的结果。否则直接返回sum值。
[cpp] view plain copy print?
- float CvCascadeBoost::predict( int sampleIdx, bool returnSum ) const
- {
- CV_Assert( weak );
- double sum = 0;
- CvSeqReader reader;
- cvStartReadSeq( weak, &reader );
- cvSetSeqReaderPos( &reader, 0 );
- // 遍历当前所有的弱分类器
- for( int i = 0; i < weak->total; i++ )
- {
- CvBoostTree* wtree;
- CV_READ_SEQ_ELEM( wtree, reader );
- // 累加第i个弱分类器的输出
- sum += ((CvCascadeBoostTree*)wtree)->predict(sampleIdx)->value;
- }
- // 如果设置不返回和sum,返回sum是否通过强分类器的阈值threshold
- if( !returnSum )
- sum = sum < threshold - CV_THRESHOLD_EPS ? 0.0 : 1.0;
- return (float)sum;
- }
float CvCascadeBoost::predict( int sampleIdx, bool returnSum ) const
{
CV_Assert( weak );
double sum = 0;
CvSeqReader reader;
cvStartReadSeq( weak, &reader );
cvSetSeqReaderPos( &reader, 0 );
// 遍历当前所有的弱分类器
for( int i = 0; i < weak->total; i++ )
{
CvBoostTree* wtree;
CV_READ_SEQ_ELEM( wtree, reader );
// 累加第i个弱分类器的输出
sum += ((CvCascadeBoostTree*)wtree)->predict(sampleIdx)->value;
}
// 如果设置不返回和sum,返回sum是否通过强分类器的阈值threshold
if( !returnSum )
sum = sum < threshold - CV_THRESHOLD_EPS ? 0.0 : 1.0;
return (float)sum;
}
最后我们来看上面的弱分类器是如何预测的,predict函数中实现,已经做了注释。
[cpp] view plain copy print?
- CvDTreeNode* CvCascadeBoostTree::predict( int sampleIdx ) const
- {
- CvDTreeNode* node = root;
- if( !node )
- CV_Error( CV_StsError, "The tree has not been trained yet" );
- if ( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getMaxCatCount() == 0 ) // ordered
- {
- // 我们说过一个弱分类是一个CART树,结构上是一个二叉树,一个节点最多有左右孩子两个子节点
- // CART树上的分割节点总是有两个孩子,而叶子节点没有孩子。因此此处就是判断node为split节点
- // 也就是要走到叶子节点才会退出,结束树的遍历
- while( node->left )
- {
- CvDTreeSplit* split = node->split;
- // 取split节点的特征序号var_idx,计算第sampleIndex个样本的第var_idx个特征值
- float val = ((CvCascadeBoostTrainData*)data)->getVarValue( split->var_idx, sampleIdx );
- // 与split节点的阈值ord.c比较,如果小于,转向左孩子,否则转右孩子
- node = val <= split->ord.c ? node->left : node->right;
- }
- }
- else // categorical
- {
- while( node->left )
- {
- CvDTreeSplit* split = node->split;
- int c = (int)((CvCascadeBoostTrainData*)data)->getVarValue( split->var_idx, sampleIdx );
- node = CV_DTREE_CAT_DIR(c, split->subset) < 0 ? node->left : node->right;
- }
- }
- // 返回样本落入的叶节点
- return node;
- }
CvDTreeNode* CvCascadeBoostTree::predict( int sampleIdx ) const
{
CvDTreeNode* node = root;
if( !node )
CV_Error( CV_StsError, "The tree has not been trained yet" );
if ( ((CvCascadeBoostTrainData*)data)->featureEvaluator->getMaxCatCount() == 0 ) // ordered
{
// 我们说过一个弱分类是一个CART树,结构上是一个二叉树,一个节点最多有左右孩子两个子节点
// CART树上的分割节点总是有两个孩子,而叶子节点没有孩子。因此此处就是判断node为split节点
// 也就是要走到叶子节点才会退出,结束树的遍历
while( node->left )
{
CvDTreeSplit* split = node->split;
// 取split节点的特征序号var_idx,计算第sampleIndex个样本的第var_idx个特征值
float val = ((CvCascadeBoostTrainData*)data)->getVarValue( split->var_idx, sampleIdx );
// 与split节点的阈值ord.c比较,如果小于,转向左孩子,否则转右孩子
node = val <= split->ord.c ? node->left : node->right;
}
}
else // categorical
{
while( node->left )
{
CvDTreeSplit* split = node->split;
int c = (int)((CvCascadeBoostTrainData*)data)->getVarValue( split->var_idx, sampleIdx );
node = CV_DTREE_CAT_DIR(c, split->subset) < 0 ? node->left : node->right;
}
}
// 返回样本落入的叶节点
return node;
}














 4470
4470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









