







Softmax 是神经网络中另一种输出层函数,计算输出层的值。主要用于神经网络最后一层,作为输出层进行多分类,是Logistic二分类的推广。两者各有特点,也有联系。本文主要介绍Softmax函数,然后与sigmoid做比较。这里笔者就偷个小赖,大部分的内容请参阅大牛的总结:Softmax回归内容。在Softmax回归内容中详细介绍了Softmax和sigmoid函数,本文在此基础上,加上一点解释,用另一种方式来介绍Softmax,虽没有大牛们总结的好,但所谓条条大路通罗马,也有异曲同工之处。下面开始分析,请先阅读Softmax回归内容。
1 Softmax
在Softmax回归内容中,logistic回归代价函数为:
![\begin{align}J(\theta) &= -\frac{1}{m} \left[ \sum_{i=1}^m (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) + y^{(i)} \log h_\theta(x^{(i)}) \right] \\&= - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=0}^{1} 1\left\{y^{(i)} = j\right\} \log p(y^{(i)} = j | x^{(i)} ; \theta) \right]\end{align}](http://deeplearning.stanford.edu/wiki/images/math/5/4/9/5491271f19161f8ea6a6b2a82c83fc3a.png)
Softmax代价函数与logistic 代价函数在形式上非常类似,只是在Softmax损失函数中对类标记的
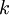 个可能值进行了累加。注意在Softmax回归中将
个可能值进行了累加。注意在Softmax回归中将
 分类为类别
分类为类别
 的概率为:
的概率为:
个可能值进行了累加。注意在Softmax回归中将
分类为类别
的概率为:
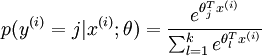 .
.
对于
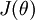 的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} \left( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) \right) \right] }\end{align}](http://deeplearning.stanford.edu/wiki/images/math/5/9/e/59ef406cef112eb75e54808b560587c9.png)
【注:这里解释一下,上面梯度公式的推导过程:对logP关于θj求导,这里的P为:.
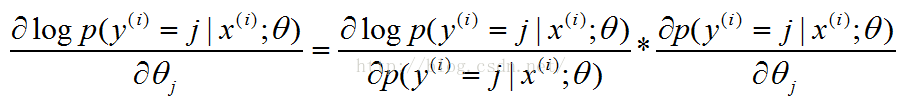
下面将.即为p:
.即为p:
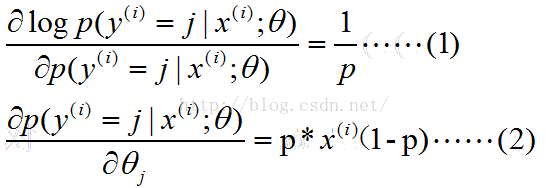
(1)式中将log看为ln函数;(2)的求导利用分数求导法则求导在将p换入,将1换为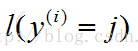 ,因为当y=j时,即为1。】
,因为当y=j时,即为1。】
2 本文讲解Softmax
(1)Softmax
第一步:与sigmoid函数相同的是,
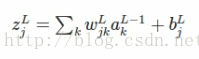
第二步:
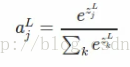
其中k表示L层的神经元个数,整个式子可以理解为某个神经元的函数值占该层神经元总函数值得比例,类似于概率。
这与sigmoid中不同,sigmoid中激活函数a=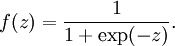 可以看出:
可以看出:
可以看出:
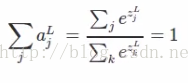
即Softmax的输出的每个值都是>=0,并且其总和为1,所以可以认为其为概率分布,这与sigmoid也是不同的,这就是Softmax回归内容中是选取Softmax还是选取sigmoid的区别的原因。
(2)Softmax学习慢与否?
要知道Softmax是否存在学习慢的问题,首先先定义Softmax的cost函数:
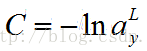
若a趋于1时,C为0,反之,若a小,则C会大,所以该函数能作为代价函数。
看学习是否快慢,就要看偏导数:
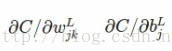 是否小。【注:这在博客神经网络三:浅析神经网络backpropagation算法中的代价函数中有解释,不清楚的可参阅】。求得偏导为:
是否小。【注:这在博客神经网络三:浅析神经网络backpropagation算法中的代价函数中有解释,不清楚的可参阅】。求得偏导为:
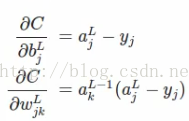
这里就不仔细介绍其求解过程了,与
1 Softmax
中的求解相似,以w的求解为例,简单解释其过程:C对w求导,(1)C对a求,a对w求;(2)a对w求导,先对z求,z对w求。
求得的偏导对比于cross-entropy中的导数【注:参阅神经网络三:浅析神经网络backpropagation算法中的代价函数】:
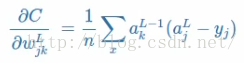
基本上是一样的,所以Softmax具有和cross-entropy相同的优点,就是不会出现学习慢的问题。















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











