







本文主要讲解神经网络中的正则化(Regularization)和Dropout,都是用了减小过拟合。正则化在机器学习领域中很重要。主要针对模型过拟合问题而提出来的。本文是观看麦子学院的视频整理而来。下面开始介绍。
1 正则化
机器学学习中的正则化相关的内容可以参见李航的书:统计学习方法。参阅者可以先了解有关的内容。正则化是用来降低overfitting(过拟合)的,减少过拟合的的其他方法有:增加训练集数量,等等。对于数据集梳理有限的情况下,防止过拟合的另外一种方式就是降低模型的复杂度,怎么降低?一种方式就是在cost函数中加入正则化项,正则化项可以理解为复杂度,cost越小越好,但cost加上正则项之后,为了使cost小,就不能让正则项变大,也就是不能让模型更复杂,这样就降低了模型复杂度,也就降低了过拟合。这就是正则化。正则化也有很多种,常见为两种L2和L1。
1.1 L2 Regularization
下面先定义Regularization cross-entropy 函数:

相比于cross-entropy函数,这里多了最后一项,也就是正则化项。该项就是神经网络中的权重之和,其中λ>0为Regularization参数,n为训练集包含的实例个数。L2正则化项这里是指最后一项的w的平方项。
而对于二次cost,也可以加上正则化项:
Regularization quadratic cost:

概括上面两种函数为:

可以看出来,Regularization的cost偏向于让神经网络学习比较小的权重w,否则第一项的C0明显减小。
λ:调整两项的相对重要程度,较小的λ偏向于让第一项C0最小化,较大的λ倾向于最小化增大的项:权重值和。
对上面公式求导得:

相比于没有正则项时,对w的偏导多了一项λw/n,而对偏向b不变。
对于随机梯度算法来说,权重w和偏向b的更新法则变为:

对于随机梯度下降算法变为:
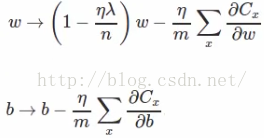
其中m为mini_batch_size的大小。下面简单分析Regularization能降低overfitting的原因:
在神经网络中,正则化网络更倾向于小的权重,在权重小的情况下,数据x随机的变化不会对神经网络的模型造成太大的影响,所以可能性更小的受到数据局部噪音的影响。而未加入正则化的神经网络,权重大,容易通过较大的模型改变来适应数据,更容易学习到局部的噪音。
1.2 L1 Regularization
先介绍L1 Regularization cost函数为:
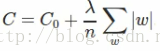
对C关于w求偏导得:
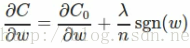
sgn(w)表示为符号函数,w为正,结果为1,w为负结果为-1。权重的更新法则为:
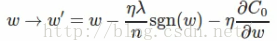
与L2 Regularization对比: 两者都是减小权重,但方式不同:
L1减少一个常量(η,λ,n根据输入都是固定的,sgn(w)为1或-1,故为常量),而L2减少的是权重的一个固定的比例;如果权重本身很大的话,L2减少的比L1减少的多,若权重小,则L1减少的更多。多以L1倾向于集中在少部分重要的连接上(w小)。这里要注意的是:sgn(w)在w=0时不可导,故要事先令sgn(w)在w=0时的导数为0。
2 Dropout
Dropout的目的也是用来减少overfitting(过拟合)。而和L1,L2Regularization不同的是,Dropout不是针对cost函数,而是改变神经网络本身的结构。下面开始简单的假设Dropout。
假设有一个神经网络:
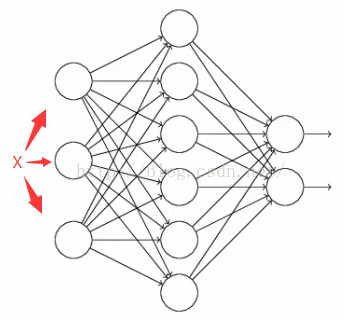
按照之前的方法,根据输入X,先正向更新神经网络,得到输出值,然后反向根据backpropagation算法来更新权重和偏向。而Dropout不同的是,
1)在开始,随机删除掉隐藏层一半的神经元,如图,虚线部分为开始时随机删除的神经元:
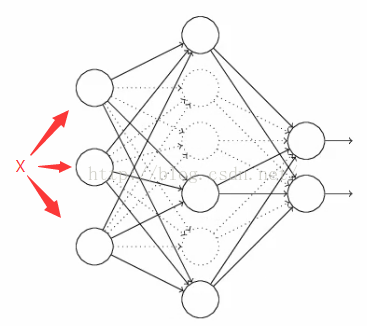
2)然后,在删除后的剩下一半的神经元上正向和反向更新权重和偏向;
3)再恢复之前删除的神经元,再重新随机删除一半的神经元,进行正向和反向更新w和b;
4)重复上述过程。
最后,学习出来的神经网络中的每个神经元都是在只有一半的神经元的基础上学习的,因为更新次数减半,那么学习的权重会偏大,所以当所有神经元被回复后(上述步骤2)),把得到的隐藏层的权重减半。
对于Dropout为什么可以减少overfitting的原因如下:
一般情况下,对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少overfitting。Dropout就是利用这个原理,每次丢掉一半的一隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其他神经元之间的更加健壮robust的特征。在Dropout的作者文章中,测试手写数字的准确率达到了98.7%!所以Dropout不仅减少overfitting,还能提高准确率。
















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











