







目录
一、前言
最近,将transformer在CV领域中新出现的T2T-ViT模型修改,再加上ArcFace用于人脸识别,将过程记录下来,欢迎探讨。
二、训练准备
1、T2T-ViT的Pytorch版本
2、人脸识别数据和代码架构
(1)人脸识别数据和代码架构用的是https://github.com/TreB1eN/InsightFace_Pytorch。下载该工程,解压,在当前目录中建立文件夹:T2T-ViT。将T2T-ViT的几个文件放入T2T-ViT文件夹中。
(2)修改config.py文件
在conf.use_mobilfacenet下面加入:
conf.use_t2tvit = False(3)修改Learner.py文件。
添加:
import T2T_ViT
from timm.models import create_model
from timm.optim import create_optimizer注:没有timm的,运行:
pip3 install timm在类face_learner中的__init__中引入conf.use_t2tvit:
if conf.use_mobilfacenet:
self.model = MobileFaceNet(conf.embedding_size).to(conf.device)
print('MobileFaceNet model generated')
elif conf.use_botnet:
self.model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=self.class_num).to(conf.device)
print('botnet model generated')
elif conf.use_t2tvit:
self.model = create_model('T2t_vit_t_14',
img_size=112,
pretrained=False,
num_classes=self.class_num,
drop_rate=0.1,
drop_connect_rate=None,
drop_path_rate=None,
drop_block_rate=None,
global_pool=None,
bn_tf=False,
bn_momentum=None,
bn_eps=None,
checkpoint_path='').to(conf.device)
print("t2tvit model generated")
else:
self.model = Backbone(conf.net_depth, conf.drop_ratio, conf.net_mode).to(conf.device)
print('{}_{} model generated'.format(conf.net_mode, conf.net_depth))注:因训练图片大小为112*112,故这里需要指明img_size=112。
添加t2t-vit的优化器optimizer:
if conf.use_mobilfacenet:
self.optimizer = optim.SGD([
{'params': paras_wo_bn[:-1], 'weight_decay': 4e-5},
{'params': [paras_wo_bn[-1]] + [self.head.kernel], 'weight_decay': 4e-4},
{'params': paras_only_bn}
], lr = conf.lr, momentum = conf.momentum)
elif conf.use_botnet:
parameters = add_bot_weight_decay(self.model)+[{'params': [self.head.kernel], 'weight_decay': 5e-4}]
self.optimizer = optim.SGD(parameters, lr = conf.lr, momentum = conf.momentum)
print("botnet optimizers generated")
elif conf.use_t2tvit:
self.optimizer = create_t2tvit_optimizer(self.model, self.head.kernel)
print("t2tvit optimizers generated")
else:
self.optimizer = optim.SGD([
{'params': paras_wo_bn + [self.head.kernel], 'weight_decay': 5e-4},
{'params': paras_only_bn}
], lr = conf.lr, momentum = conf.momentum)其中的create_t2tvit_optimizer函数为:
def add_weight_decay(model, kernel, weight_decay=1e-5, skip_list=()):
decay = []
no_decay = []
for name, param in model.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias") or name in skip_list:
no_decay.append(param)
else:
decay.append(param)
return [
{'params': no_decay, 'weight_decay': 0.},
{'params': [kernel], 'weight_decay': 5e-4},
{'params': decay, 'weight_decay': weight_decay}]
def create_t2tvit_optimizer(model, kernel):
weight_decay = .05
lr = 5e-4
opt = 'adamw'
filter_bias_and_bn = True
opt_lower = opt.lower()
if weight_decay and filter_bias_and_bn:
skip = {}
if hasattr(model, 'no_weight_decay'):
skip = model.no_weight_decay()
parameters = add_weight_decay(model, kernel, weight_decay, skip)
weight_decay = 0.
else:
parameters = model.parameters()
opt_args = dict(lr=lr, weight_decay=weight_decay)
if opt_lower == 'adam':
optimizer = optim.Adam(parameters, **opt_args)
elif opt_lower == 'adamw':
optimizer = optim.AdamW(parameters, **opt_args)
elif opt_lower == 'sgd' or opt_lower == 'nesterov':
opt_args.pop('eps', None)
momentum = 0.9
optimizer = optim.SGD(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'momentum':
momentum = 0.9
opt_args.pop('eps', None)
optimizer = optim.SGD(parameters, momentum=momentum, nesterov=False, **opt_args)
return optimizer(4)修改train.py文件,加入:
conf.use_mobilfacenet = False
conf.use_botnet = False
conf.use_t2tvit = True
conf.lr = args.lr
conf.batch_size = 64
conf.num_workers = args.num_workers注:这里因电脑本身CUDA内存原因,只能使用batch_size = 64。
3、完整训练代码
conf.use_mobilfacenet = False
conf.use_botnet = False
conf.use_t2tvit = True说明:上述三个参数均为False时,使用的是ResNet(默认是ir_se,depth=50)进行人脸识别训练;剩下的哪个为True,使用对应的模型进行训练
人脸识别数据参考源代码(https://github.com/TreB1eN/InsightFace_Pytorch)中的获取方式如下,具体参考源代码(https://github.com/TreB1eN/InsightFace_Pytorch),这里不做介绍。
三、训练和结果
1、训练
保持原github上其余参数的设置,运行:
python3 train.py2、结果
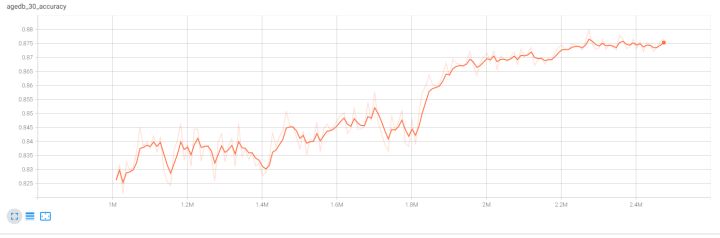
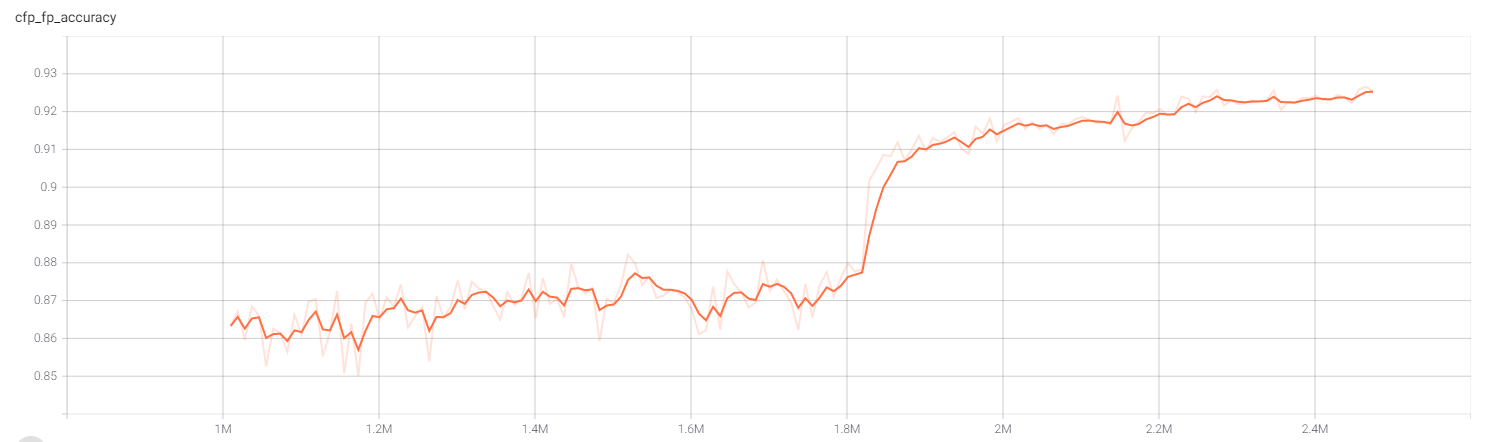
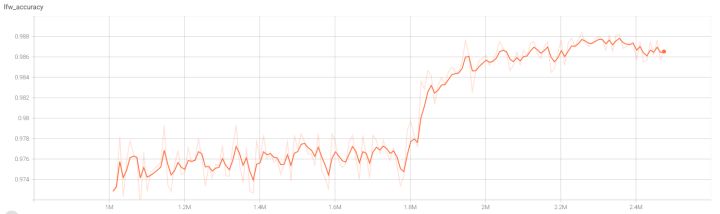
结果20多个epochs的训练后,在数据集上的准确率如下图所示。因在训练过程中中断,后重新接上训练,故对应的log是训练中间到最后的,不是全部的。在LFW、CFP-FP、AgeDB-30中的识别率分别为:98.67%、92.53%、87.53%,相比BoTNet(98.98%、92.18%、90.29%, 见博客:基于Pytorch版本的BoTNet的人脸识别效果),在AgeDB-30数据集有差异,其他基本一样,但相比原github上提供的效果(LFW 0.9952、CFP-FP 0.9504、AgeDB-30 0.9622),还是差了不少。后续还需要不断调参,或改进现有网络,看看是否有上升的空间。各位如有更好方法,欢迎探讨!


















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











