







安装Hadoop前提:
1、Ubuntu14.04 虚拟机
2、JDK
3、Hadoop安装包
前面的条件就不说了,默认已经安装了VMware并安装好了Ubuntu14.04,配置好了Java环境。将hadoop安装包拷贝至虚拟机。
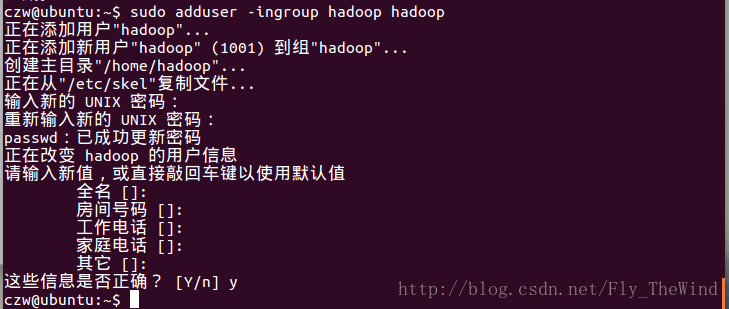
为了方便起见,添加hadoop用户组和hadoop用户
添加用户组

添加用户
切换到hadoop用户
安装ssh,免密登陆
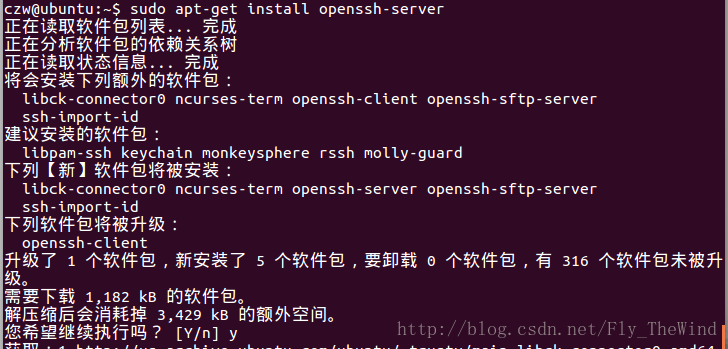
查看是否启动ssh服务,如果没有则使用sudo /etc/init.d/ssh start启动ssh

cd ~/.ssh #如果没有该目录,执行ssh localhost
ssh-keygen -t rsa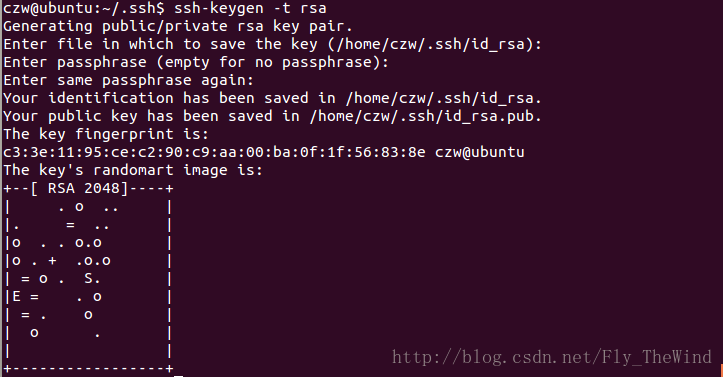
这样就生成了一对公钥和私钥,暂时先不管,到时候将公钥拷贝到需要联机的Ubuntu2的~/.ssh/authorized_keys下,这样Ubuntu2就可以无密码访问这Ubunut1了。同理将Ubuntu2下生成的公钥拷贝到Ubuntu1下。
tar zxvf hadoop-2.7.4.tar.gz
mv ./hadoop-2.7.4 /usr/local/hadoop改变hadoop文件的用户和用户组
sudo chown -R hadoop ./hadoop
sudo chgrp -R hadoop ./hadoop
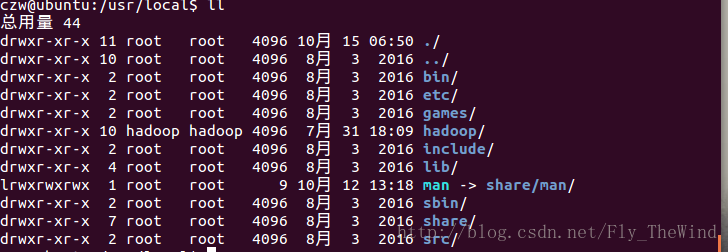
使用/usr/local/hadoop/bin/hadoop查看是否安装成功,出现提示则安装成功
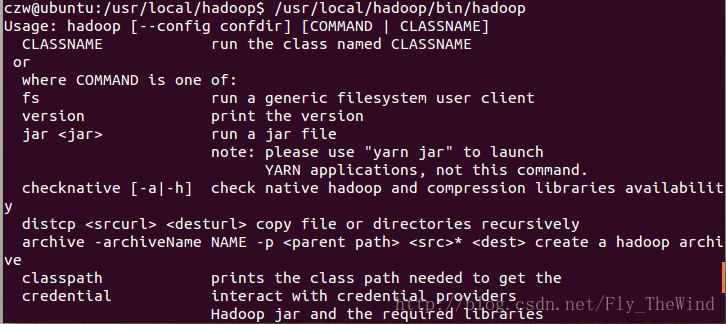
配置环境变量vi ~/.bashrc
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL更新一下source ~/.bashrc
这样就可以在终端直接使用hadoop等命令了。
从单机到为分布式
进入/usr/local/hadoop/etc/hadoop/下,在 core-site.xml中把
<configuration>
</configuration>替换为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>同样的在hdfs-site.xml中,替换为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>配置完成后,执行 NameNode 的格式化:
hdfs namenode -format执行完结果如下
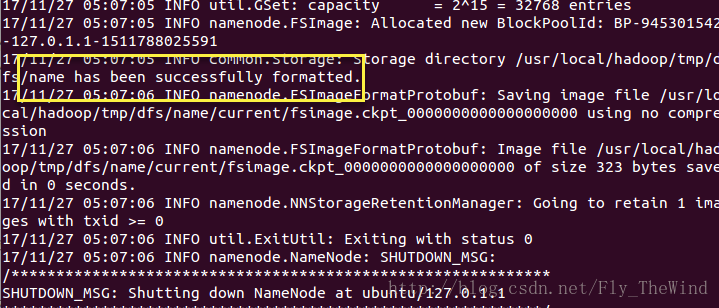
接着启动NameNode 和 DataNode 守护进程
./sbin/start-dfs.sh如果这里出现了JAVA_HOME的问题
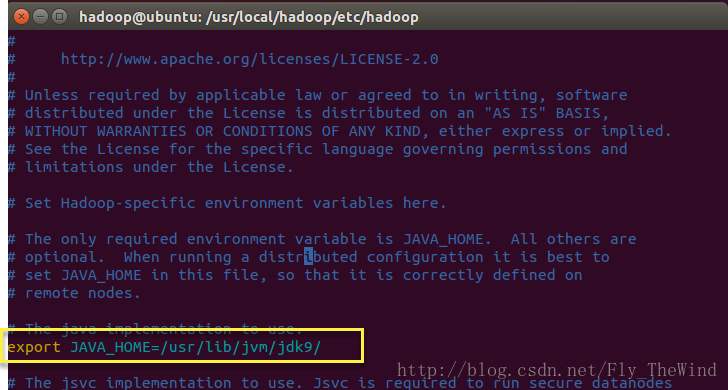
localhost: Error: JAVA_HOME is not set and could not be found.在确定Java -version 是好使的情况下,那么在hadoop的/etc/hadoop/目录下修改hadoop-env.sh文件,
将其中相对路径的JAVA_HOME改成绝对路劲的JAVA_HOME
如图:
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤。
结果如图:

完成之后,就可以在游览器查看NameNode信息和DataNode信息。
地址是:ip:50070
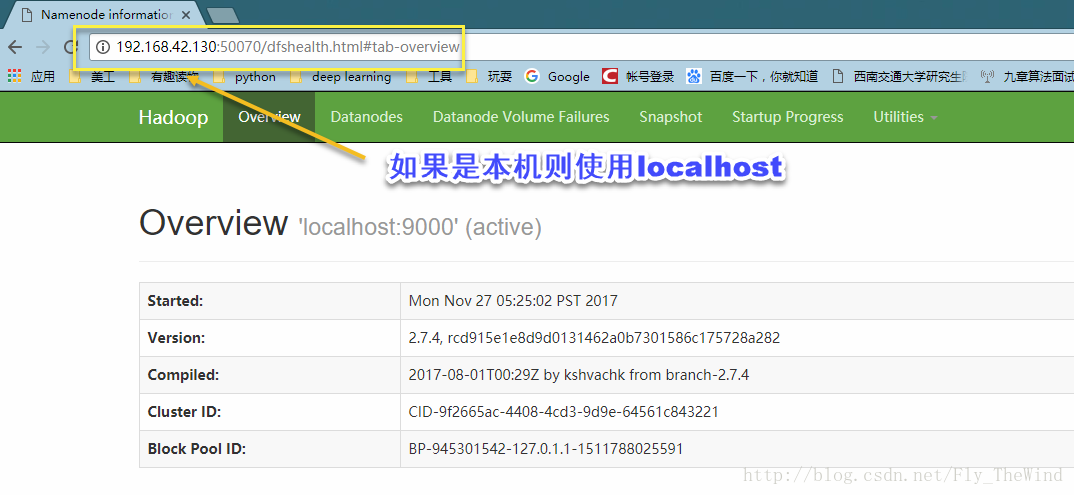
**
运行伪分布式实例
**
操作单机版基本相同,只是文件保存在hdfs上。
操作需要加hadoop 前缀或者hdfs 前缀















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









