







更快的优化器
动量优化
- 梯度下降通过直接减去权重的成本函数 J ( θ ) J(\theta) J(θ)的梯度乘以学习率( Δ θ J ( θ ) \Delta _{\theta}J(\theta) ΔθJ(θ))来更新权重 θ \theta θ。它不关系较早的梯度是什么。
- 动量优化:在每次迭代时,它都会从动量向量
m
m
m中减去局部梯度(乘以学习率
η
\eta
η),并通过添加该动量来更新权重。
1. m ← β m − η Δ θ J ( θ ) 2. θ ← θ + m \begin{array}{ll} 1.&m\gets \beta m - \eta \Delta_{\theta}J(\theta)\\ 2.&\theta \gets \theta + m \end{array} 1.2.m←βm−ηΔθJ(θ)θ←θ+m - 如果梯度保持恒定,则最终速度(即权重更新的最大大小)等于该梯度乘以学习率 η \eta η 在乘以 1 / ( 1 − β ) 1/(1-\beta) 1/(1−β)。
- 梯度下降相当快地沿着陡峭的斜坡下降,但是沿着山谷下降需要很长时间。相反,动量优化将沿着山谷滚得越来越快,知道达到谷底(最优解)。
- 在Keras实现动量优化:
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9)
Nesterov加速梯度
- Nesterov加速梯度(Nersterov Accelerated Gradient,NAG)也称为Nesterov动量优化,它不是在局部位置
θ
\theta
θ,而是在
θ
+
β
m
\theta+\beta m
θ+βm处,沿动量方向稍微提前处,测量成本函数的梯度。
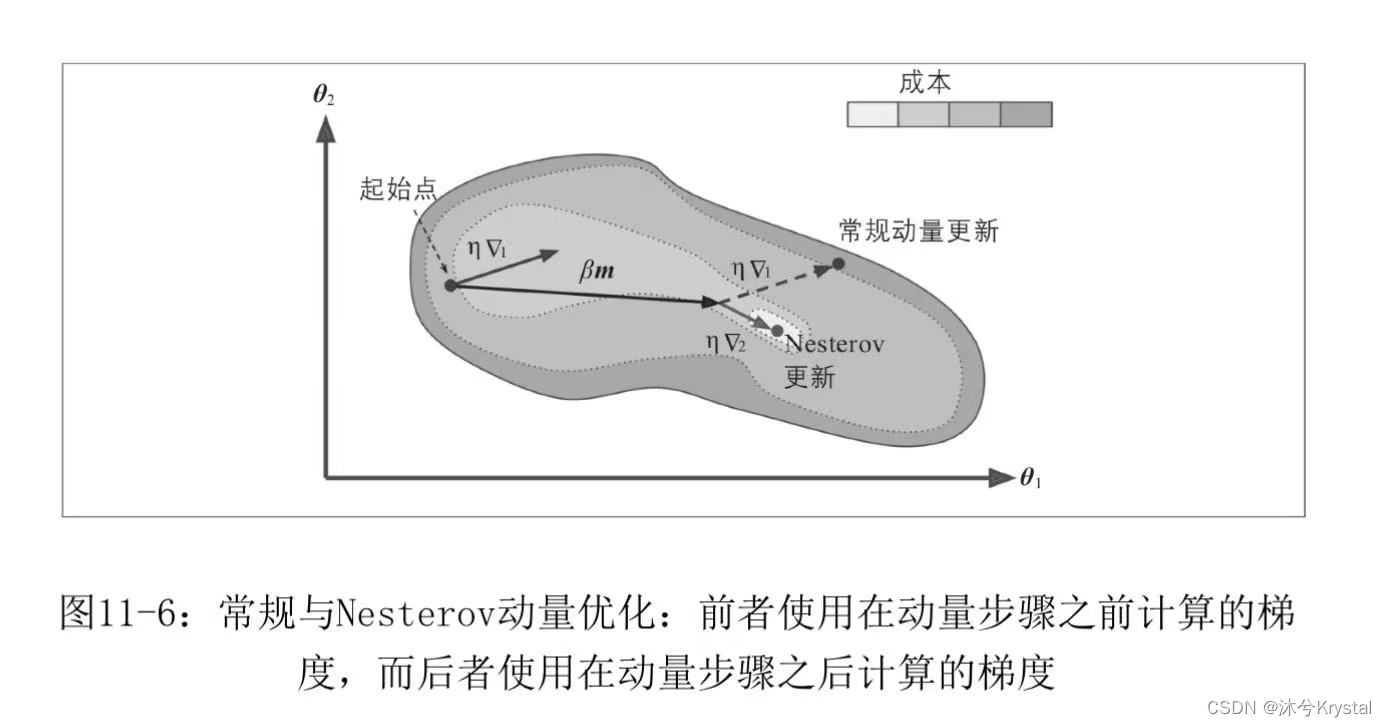
1. m ← β m − η Δ θ J ( θ + β m ) 2. θ ← θ + m \begin{array}{ll} 1.&m\gets \beta m - \eta \Delta_{\theta}J(\theta + \beta m)\\ 2.&\theta \gets \theta + m \end{array} 1.2.m←βm−ηΔθJ(θ+βm)θ←θ+m - 下图
Δ
1
\Delta_1
Δ1表示在起点
θ
\theta
θ处计算的梯度,
Δ
2
\Delta_2
Δ2表示在位于
θ
+
β
m
\theta+\beta m
θ+βm处计算的梯度,当动量推动权重跨越谷底时,
Δ
1
\Delta_1
Δ1继续推动越过谷底,而
Δ
2
\Delta_2
Δ2推回谷底。这有助于减少震荡,因此NAG收敛更快。
- 使用NAG:
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9, nesterov=True)
AdaGrad
- 梯度下降从快速沿着最陡的坡度下降开始,该坡度没有指向全局最优解。AdaGrad算法通过沿着最陡峭的维度按比例缩小梯度向量来实现,更早地纠正其方向。
1. s ← s + Δ θ J ( θ ) ⊗ Δ θ J ( θ ) 2. θ − η Δ θ J ( θ ) ⊘ s + ϵ \begin{array}{ll} 1.& s\gets s + \Delta_{\theta}J(\theta)\otimes \Delta_{\theta}J(\theta)\\ 2.& \theta-\eta \Delta_{\theta}J(\theta)\oslash \sqrt{s+\epsilon } \end{array} 1.2.s←s+ΔθJ(θ)⊗ΔθJ(θ)θ−ηΔθJ(θ)⊘s+ϵ - 在如上显示的AdaGrad算法中:
⊗ \otimes ⊗符号表示逐个元素相乘,第一步将梯度的平方累加到向量 s s s中。每个 s i s_i si累加关于参数 θ i \theta_i θi的成本函数偏导数的平方。如果成本函数沿着第 i i i个维度陡峭,则 s i s_i si将在每次迭代中变得越来越大。
⊘ \oslash ⊘符号表示逐个元素相除,第二步几乎与”梯度下降“相同,只是梯度向量按比例因子 s + ϵ \sqrt{s+\epsilon } s+ϵ缩小了。 - 该算法会降低学习率,但是对于陡峭的维度,它的执行速度比对缓慢下降的维度的执行速度要快,这称为自适应学习率。它几乎不需要调整学习率超参数
η
\eta
η。
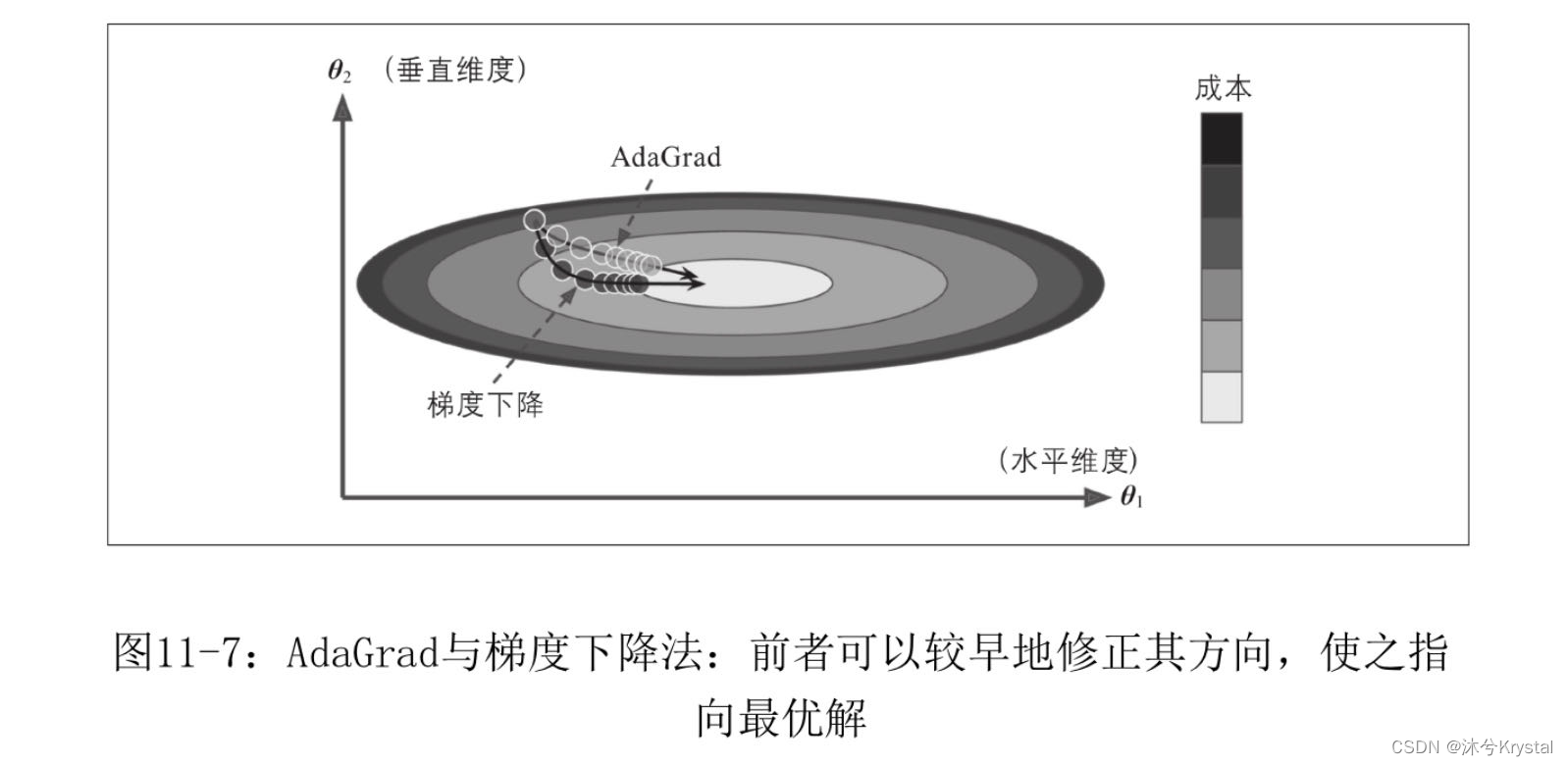
- 在训练神经网络时候,它往往停止得太早,不适合用于训练深度神经网络,但对于线性回归之类的简单任务可能是有效的。
RMSProp
- RMSProp算法通过只是累加最近迭代中的梯度(而不是自训练开始以来的所有梯度),通过在第一步中使用指数衰减来实现:
1. s ← β s + ( 1 − β ) Δ θ J ( θ ) ⊗ Δ θ J ( θ ) 2. θ − η Δ θ J ( θ ) ⊘ s + ϵ \begin{array}{ll} 1.& s\gets \beta s + (1-\beta )\Delta_{\theta}J(\theta)\otimes \Delta_{\theta}J(\theta)\\ 2.& \theta-\eta \Delta_{\theta}J(\theta)\oslash \sqrt{s+\epsilon } \end{array} 1.2.s←βs+(1−β)ΔθJ(θ)⊗ΔθJ(θ)θ−ηΔθJ(θ)⊘s+ϵ
衰减率 β \beta β通常设置为0.9. - Keras有RMSprop优化器:
optimizer = keras.optimizer.RMSprop(lr=0.001, rho=0.9)
Adam和Nadam优化
- Adam代表自适应钜估计,结合了动量优化和RMSProp的思想:就像动量优化一样,它跟踪过去梯度的指数衰减平均值;想RMSProp一样,它跟踪过去平方梯度的指数衰减平均值。

- 动量衰减超参数 β 1 \beta_1 β1 通常被初始化为0.9,缩放衰减超参数 β 2 \beta_2 β2 通常被初始化为 0.999.
- 使用Keras来创建Adam优化器:
optimizer = keras.optimizer.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
- Adam有两个变体:AdaMax和Nadam。
训练稀疏模型
- 密集模型意味大多数参数都是非零的,如果在运行时需要一个非常快的模型,或者需要更少的内存,可以使用稀疏模型。
- 实现方法是像往常一样训练模型,去掉很小的权重(设置为0)。更好的方法是在训练时使用强1正规化,它会迫使优化器产生更多的为零的权重。
优化器比较
















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









