





http://www.ddj.com/hpc-high-performance-computing/215900921
Rob Farber
再次讨论CUDA内存空间
Rob Farber 是西北太平洋国家实验室(Pacific Northwest National Laboratory)的高级科研人员。他在多个国家级的实验室进行大型并行运算的研究,并且是几个新创企业的合伙人。大家可以发邮件到rmfarber@gmail.com与他沟通和交流。
在关于CUDA(Compute Unified Device Architecture,即计算统一设备架构的简称)的系列文章的第10节,我探讨了CUDPP,也就是CUDA Data Parallel Primitives Library数据平行基元库。在本小节,我要重新探讨本地和常量内存,介绍“纹理存储器”的概念。
在大多数情况下,优化CUDA应用程序的性能需要优化数据读取,包括恰当使用不同的CUDA内存空间。纹理存储器提供了令人惊喜的功能,包括缓冲全局内存(与寄存器,全局和共享内存独立)和与线程处理器独立的专有插补硬件。纹理存储器也提供了与GPU显示功能互动的方法。纹理存储器是一个涉及范围广泛的话题,在这里会做下介绍,并在以后的文章里进行更详细的讨论。本系列文章的第四部分介绍了CUDA内存模式,并描述了不同的CUDA内存空间,如图1所示。每个内存空间都有特定的性能特点和局限。
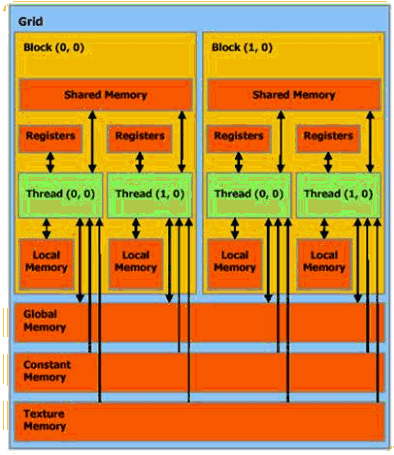
图 1: CUDA内存空间
对这些内存空间的恰当使用对CUDA应用程序而言,在性能方面有重要意义。表1总结了不同CUDA内存空间的特点。本系列文章的第五节更为详细地讨论了CUDA内存空间(不包括纹理存储器),包括要注意的性能问题。
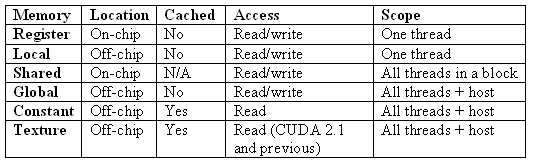
表1:不同CUDA内存空间的特征
本地内存
本地内存是内存抽象,意味着“在每个线程范围之内有本地特点”。它不是多处理器的一个实际的硬件组件。事实上,本地内存通过编译器在全局内存内进行分配,和其它任何全局内存区一样提供完全相同的性能。在正常情况下,在内核里宣布的自动变量存于寄存器中,可快速读取。不幸的是,自动变量和本地内存之间的关系仍然是CUDA程序员的迷惑之一。编译器可能会选择将自动变量放置在本地内存中,当:
有太多的寄存器变量;
结构会消耗太多寄存器空间;
编译器不能确定数组是否根据常量索引定址。
请注意:寄存器是不可设定地址的,因此数组必须进入本地内存-即使是两元素数组-当在编译时,不知道数组地址的时候。
如需了解进一步的讨论,请参考本系列文章第五节的“寄存器/本地内存注意事项”,第四节的”CUDA内存模式”和NVIDIA CUDA Zone Documentation网站上CUDA编程指导。
常量内存
常量内存仅从内核读取,当所有线程读取同一地址时,是被优化的硬件。令人惊讶的是,当有缓冲区的时候,常量内存提供一个潜伏周期,尽管常量内存存在于设备内存里(DRAM)。如果线程从多个地址读取,访问被序列化。仅通过主机(而不是设备,因为它是常量)把cudaMemcpyToSymbol 写入常量缓存,在同一个应用程序内,在所有的内核调用中都是一致的。高达64KB的数据可被放置在常量缓存里,每个多处理器有8KB内存。在常量内存里读取数据,根据缓冲定位,可持续一个周期到成百个周期。对常量内存的第一次读取往往因为预取而不会产生缓冲不命中。
CUDA中纹理存储器
图形处理器提供纹理存储器以加速经常执行的运算,如映射,或变形,一个2D“皮肤”到3D多边形模型上。图2中所示技巧使得低分辨率游戏对象视觉上看上去要丰满些,更为复杂,有更多细节。为了保持竞争力,显示卡生产商增添了额外的硬件(如纹理单元)让这些图形操作更快。CUDA提供相关机制,这样C程序员可以利用CUDA启动的设备上纹理单元硬件的一些新增的功能。(如需了解有关图形里纹理使用的更多信息,请参阅在线免费GPU Gems 电子书。最好从. GPU Gems 2.第37章开始)。
图 2:.运行中的纹理存储器
看待纹理存储器的最简洁的方法是:把它看成一个可选的内存访问路径,CUDA程序员可把它与GPU设备内存的区域绑定起来(如,全局内存)。纹理参照系可被绑定到内存中相同的,重叠的或不同的纹理上。每个芯片上纹理单元都有内部内存,缓冲全局内存的数据。因此,纹理存储器可被用来做为线程处理器的一个放松机能,以访问全局内存,因为在前面的文章里讨论的聚结要求不适用于纹理存储器访问。当目标为前一代CUDA-capabled的GPU,这就特别有用,但是如果是新一代的硬件内的放松聚合要求,可能就没有这么有用啦。
因为优化数据读取对GPU性能来说非常重要,使用纹理存储器可(在正确的环境里)提供极大的性能改善。当warp的线程读取从空间局限性的视角看为靠近的地址时,可获得最佳性能。CUDA提供1D, 2D 和3D 拾取功能。因为纹理仅在有缓冲不命中时,执行从全局内存的读取运算,所以可能通过对纹理存储器缓冲的有效利用,超过潜在全局内存的最大理论内存带宽。这样,当使用纹理时,纹理访问率(texfetch)成为了分析内核性能的更为有用的公制。例如,Patrick LeGresley在High Performance Computing with CUDA 的第32张幻灯片里注明, G80 构架可提供大约每秒180亿拾取。
在以下情况,要特别考虑使用纹理:
有引用的局部性时,在纹理内存内缓冲可有所帮助;
使用纹理缓冲可降低对不能完全聚合(也就是几乎聚合的访问,如错位起始地址)的惩罚。
上述情况都要视具体问题而定,所有进行一些测试是必要的。有些作者声称特定的纹理内存读取格式比其它的快很多倍(可参见Kipton Barro的CUDA Tricks and Computational Physics).
纹理内存的其它性能优势(相对于全局和常量内存而言)包括:
集装数据可被广播以在单个运算里分离变量;
8位和16位整数输入数据可能被纹理单元硬件转换为32位浮点值,范围为 [0.0, 1.0] 或 [-1.0, 1.0]。
使用从线程处理器独立出来的专用硬件的线性,双线性和三线性插值
除本文提及的之外,纹理内存提供其它功能。在跟下来的文章里,我将进一步讨论纹理内存。在阅读下一篇文章之前,请参阅NVIDIA_CUDA_SDK项目。网上也有许多有用的样例,你可下载后尝试下。以下是两种可能:
在Google cudaiap2009 "cuda@mit"网站登录的经典实例里,CUDA 3D texture example可能会有所帮助;
The CIRL fuzzy logic tutorial.
如需了解更多有关在GPU上重复使用数据采用的纹理缓冲和其它方法,最好的一个参考资料就是Mark Silberstein的 Efficient Computation of Sum-products on GPUs Through Software Managed Cache(通过软件管理缓冲有效计算GPU上的合积)
总结
上面的论述(包括所有本系列文章之前的内容)都说明CUDA开发人员必须掌握好CUDA内存空间。特别是,注意本地和全局内存没有被缓冲,读取延迟就高。David Kirk 和Wen-mei Hwu在The CUDA Memory Model with additional API and Tools info 里讨论了读取延迟:
寄存器-专用HW-单循环;
共享内存-专用HW-单循环;
本地内存-DRAM,无缓冲-*慢*
全局内存-DRAM, 无缓冲-*慢*
常量内存-DRAM, 已被缓冲,根据缓存定位,一到几百个循环
纹理内存-DRAM,已被缓冲,几百个循环
常量内存-DRAM, 已被缓冲,根据缓存定位,一到几百个循环
纹理内存-DRAM,已被缓冲,几百个循环
指令存储器(不可见)-DRAM,已被缓冲
把典型的CUDA模板当作:
将任务分成一个个小任务;
将输入数据分入一个个组块,适合寄存器和共享内存的大小;
从全局内存下载数据块,放入寄存器和共享内存;
每个数据块由一个线程块进行处理;
将结果复制回全局内存
然而,纹理和常量内存被缓冲,可以极大地提高应用程序的性能-因为它们的读取特点-根据应用程序读取的格式:
R/O无结构→ 常量内存
带有结构的R/O数组→ 纹理内存 (CUDA 2.1 和之前的文章)
在块内共享的R/W → 共享内存
R/W寄存器流出至本地内存,可能会突然提供一个SLOWDOWN;
R/W 输入/结果→ 全局内存














 2208
2208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









