







上一讲主要利用不同模型计算出来的g,采用aggregation来实现更好的g。如果还没有做出来g,我们可以采用bootstrap的方法来做出一系列的“diversity”的data出来,然后训练出一系列的g,比如PLA来说,虽然模型一样,就是直线对二维平面的分割,模型都为直线,那么我们利用bootstrap来做出不同的数据,然后计算出不同的g,然后融合后就可以得到很好的效果。或者也可以通过调整PLA的初始值来训练,得到一堆g,最后融合(parameter diversity,random initial。。。)

下面主要讲一下一个更加强的机器学习的技法:Adaptive boosting。
下面以老师教小孩认识苹果的过程,将标识苹果的特征(形状(圆的),颜色(红的、绿的),。。。等等),一个同学说苹果形状是怎样,另一个同学说苹果颜色是怎样,然后还有其他同学说苹果还有其他特征,就这样一次次的给苹果增加特征,然后联合起来就能让同学们都能很好的认出苹果了(苹果的概念就很丰富了)。

先从bootsrapping开始引入adaptive boosting,利用bootstrap来生成u,然后就比较像是Re-weighting process,用来优化Re-Weight Ein_u(h)为最小。
pic3
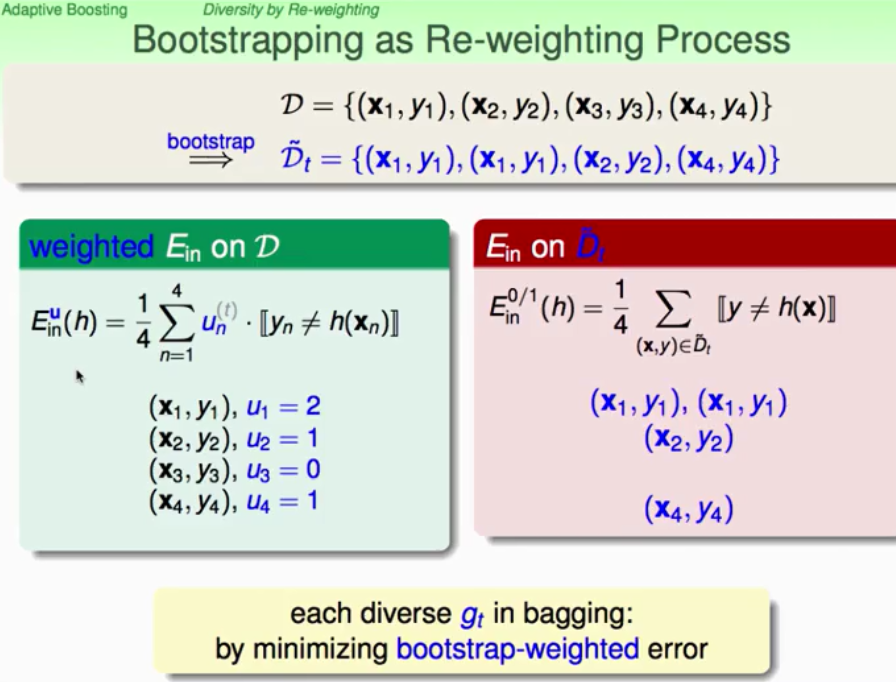
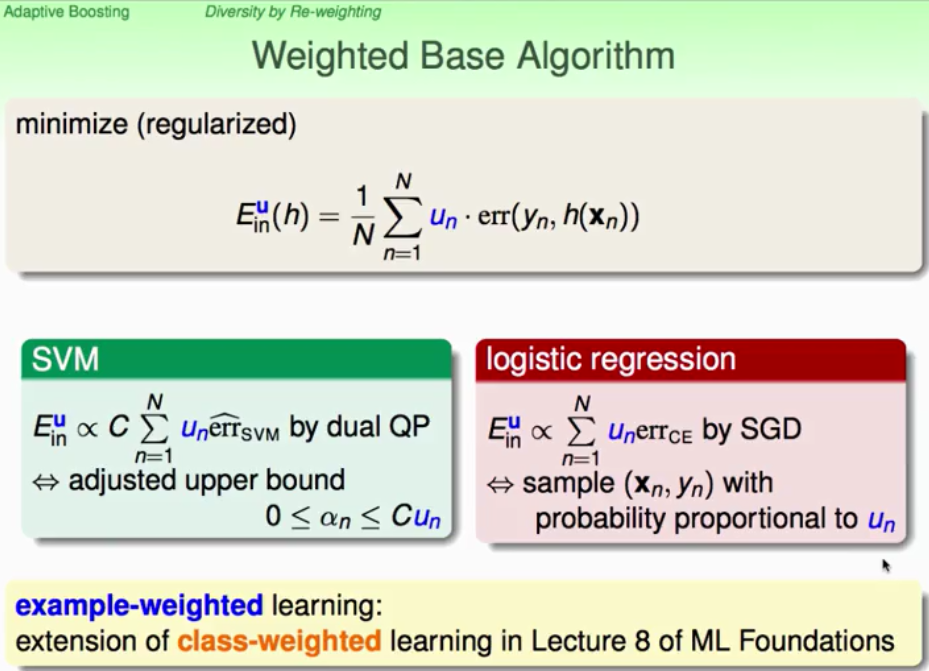
就是小u对应着data中数据点被抽样的次数,如何得到g(t)与g(t+1)是有差异的呢?调整这个u(weight)来使得得到的g(t)在下一轮表现很不好,这样g(t+1)就与g(t) diversity了。做出u(t+1)在g(t)上的加权error大致等于掷硬币的概率0.5就好了。

在数学上只需要让犯错误的u之和与没有犯错的u之和相等就可以得到0.5,处理方法:将错误的点乘以对的比率,让正确的点乘以错的比率,如下图所示:

在数学上,通过将factor规则化,scale up incorrect , scale down correct(有点类似PLA,对错误放大,然后进行调整,就像老师教学生认识苹果一样,贾同学说了苹果是圆形的,但是他在橘子上犯错了,那就放大苹果与橘子的差别,对颜色,通过颜色分别,加强对苹果认识)如下所示:

我们通过bootstrap中不同的u得到了一系列小g,那么u的更新过程就如下图来进行。最后将小g合并得到很好的很强很丰富的G。

可以利用线性aggregation的方法来融合所有的g,得到G。所以,这个线性的权重如何衡量呢?我们可以用g的表现性能来进行决定alpha,算法设计的时候,用来衡量的话采用了ln()来做,当判断的概率为0.5时,就像是掷硬币一样,这样权重计算就为0,我们不选这样的无用的g,当犯错误的概率为0时,计算出的权重为无穷大,这样也是合理的啊。


这样从理论上分析一下,Adaboost有何好处呢?我们知道VC bound来进行,只要我们得到的小g比乱猜做的好一点,通过逐步的(AdaBoost + 演算法),我们就可以在T=O(log(N))次的逐步演进就可以得到Ein(G)=0,同时根据VC bound 我们可以看出upper bound也很小,即Eout也能保证很小,从而实现比较好的性能。

所以,我们只需要一个能够比乱猜好一点的“weak” base 学习算法A,通过adaboost就可以做到最好的G。一个非常好的用于adaboost的演算法---decision stump(决策树)。decision stump是利用单一的feature进行分割,二维平面上就是一条条垂直或水平的线,因为它只在一个维度下进行分割。所以,如果单独的decision stump就是一个比较弱的分类器,那么结合了adaboost呢?下面就给出几个例子

虽然单个decision stump是一个“weak”的分类器,就是说它的分界线是简单的直线,但是通过adaboost,就可以拟合、逼近一个非常细腻的边界。边界的拟合过程就是vote的结果,而adaboost的过程,就是通过逐步的放大错误,纠正错误,最后通过vote来实现边界的融合。从而做出非常复杂边界的过程。而且这个过程因为有VC bound的理论指导,在一定程度上能够遏制overfitting,所以Adaboost是一种非常有效的方法逐步增强的融合方法,
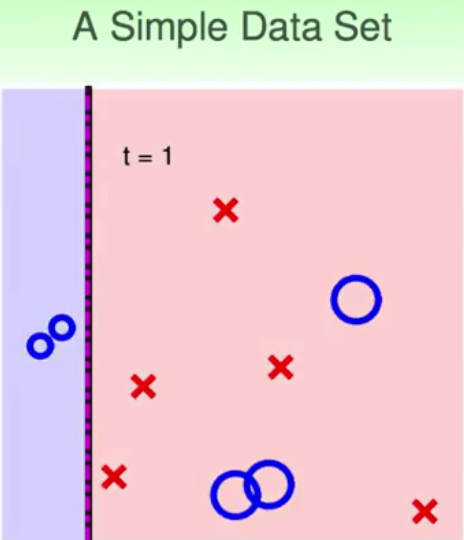
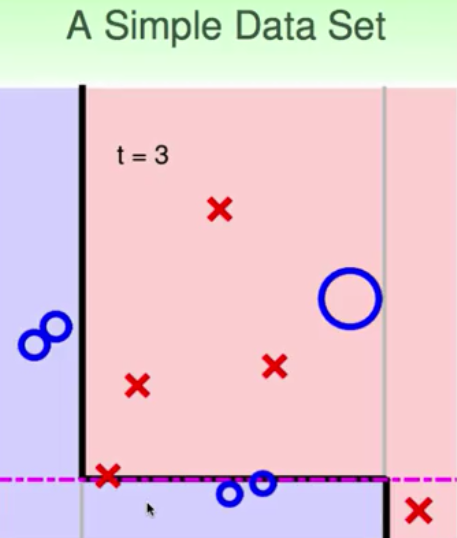
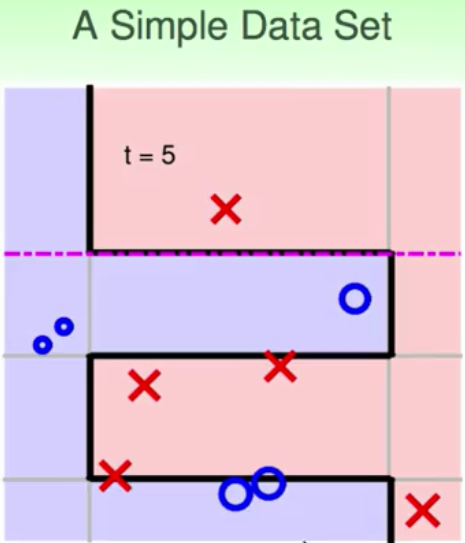
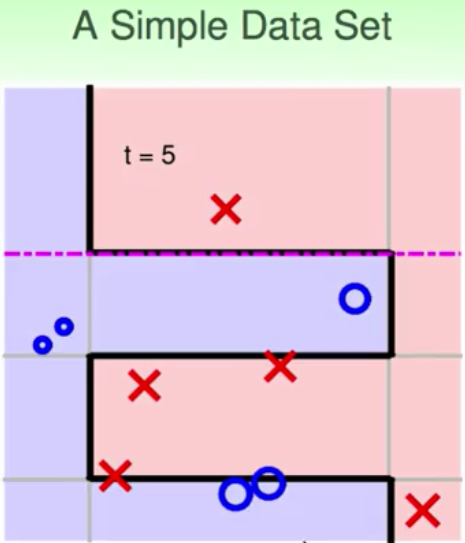
上面是一个比较简单的sample,那么下面的例子就是比较复杂的边界,你说用decision stump能够做出来sine波的形状吗?下面的结果就说明了这个过程。
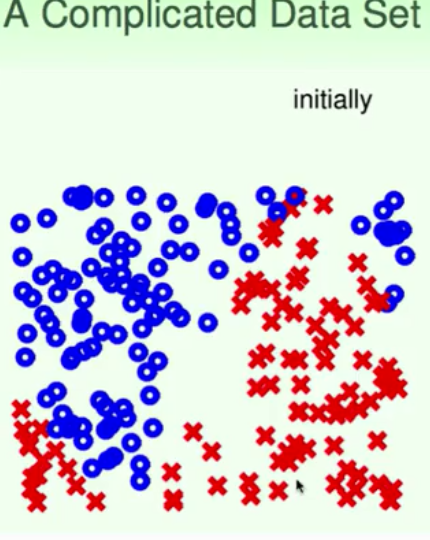
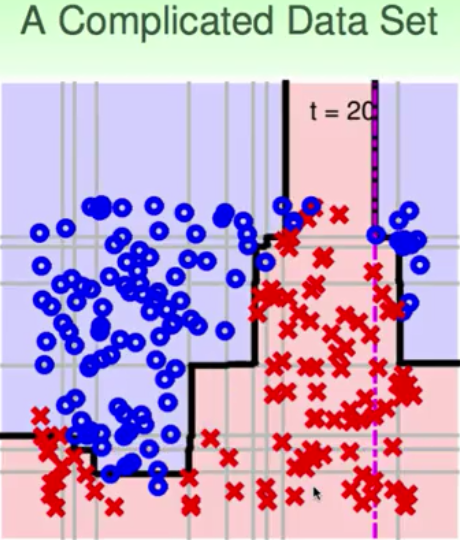
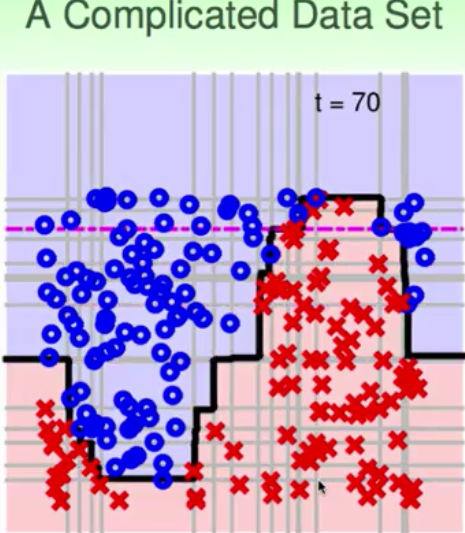
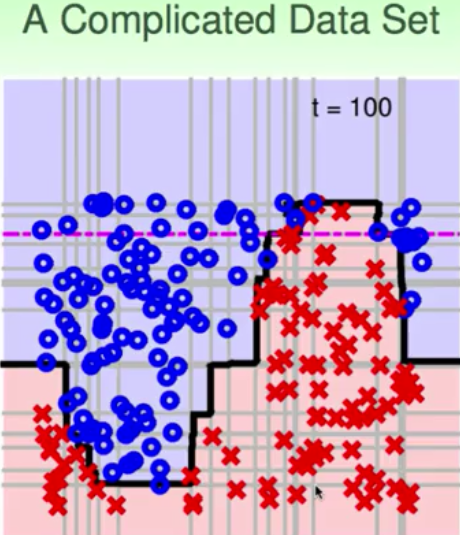
它实际上就做出了非线性的拟合过程。AdaBoost-Stump在实际的工程应用中就是世界上首个实时人脸识别:

实际上AdaBoost-Stump具备了特征选择的能力,这方面可以联想到deep learning中的一些知识。

回头可以采用opencv利用AdaBoost来对人脸进行识别的程序学习一下,以便更好地掌握AdaBoost在具体的处理中的应用。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











