










我们现在开始训练模型,还输入参数如下:
rank:ALS中因子的个数,通常来说越大越好,但是对内存占用率有直接影响,通常rank在10到200之间。
iterations:迭代次数,每次迭代都会减少ALS的重构误差。在几次迭代之后,ALS模型都会收敛得到一个不错的结果,所以大多情况下不需要太多的迭代(通常是10次)。
lambda:模型的正则化参数,控制着避免过度拟合,值越大,越正则化。
我们将使用50个因子,8次迭代,正则化参数0.01来训练模型:
val model = ALS.train(ratings, 50, 8, 0.01)
说明:原书中使用的迭代参数是10,但是在本机上使用10次迭代参数会造成堆内存溢出,经过调试将它改成8。
它会返回一个MatrixFactorizationModel对象,包含了user和item的RDD,以(id,factor)对的形式,它们是userFeatures和productFeatures。
println(model.userFeatures.count)
println(model.productFeatures.count)


MatrixFactorizationModel类有有一个非常方便的方法predict,会针对某个用户和物品的组合预测分数。
val predictedRating = model.predict(789, 123)
这里选择的用户id为789,计算他对电影123可能的评分,结果如下:

你得到的结果可能跟我这的不一样,因为ALS模型是随机初始化的。
predict方法会创建一个RDD(user,item),为某个用户进行个性化推荐,MatrixFactorizationModel提供了一个非常方便的方法——recommendProducts,输入参数:user,num。user是用户id,num是将要推荐的个数。
现在为用户789推荐10部电影:
val userID = 789
val K = 10
val topKRecs = model.recommendProducts(userID, K);
println(topKRecs.mkString("\n"))
结果如下:
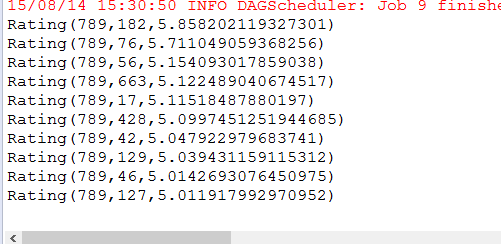
下面取到电影的名字:
val movies = sc.textFile("F:\\ScalaWorkSpace\\data\\ml-100k\\u.item")
val titles = movies.map(line => line.split("\\|").take(2)).map(array => (array(0).toInt, array(1))).collectAsMap()
println(titles(123))
结果如下:

我们再来看看用户789对多少部电影进行了评分:
val moviesForUser = ratings.keyBy(_.user).lookup(789)
println(moviesForUser.size)
结果如下:

可以看到用户789对33部电影进行了评分。
接下来我们将要取得前10个评分最高的电影,使用Rating对象的rating字段,并且得到根据电影的id得打电影的名字:
moviesForUser.sortBy(-_.rating).take(10).map(rating => (titles(rating.product), rating.rating)).foreach(println)
结果如下:
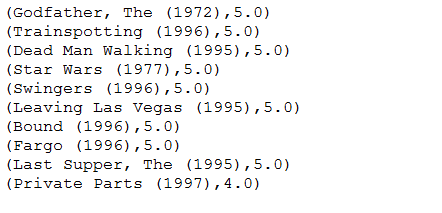
然后我们再来看看为这个用户推荐的是哪10部电影:
topKRecs.map(rating => (titles(rating.product), rating.rating)).foreach(println)
结果如下:

找到相似电影
通过计算两个向量的夹角的余弦值来判断相似度,如果是1,那么说明完全一样,如果是0那么说明没有相关性,如果是-1则表明这两者是完全相反的。首先编写计算两个向量夹角余弦值的方法:
def cosineSimilarity(vec1: DoubleMatrix, vec2: DoubleMatrix): Double = {
vec1.dot(vec2) / (vec1.norm2() * vec2.norm2())
}
现在来检测下是否正确,选一个电影,看看它与它本身相似度是否是1:
val itemId = 567
val itemFactor = model.productFeatures.lookup(itemId).head
val itemVector = new DoubleMatrix(itemFactor)
println(cosineSimilarity(itemVector, itemVector))

可以看到得出的结果是1!
接下来我们计算其他电影与它的相似度:
val sims = model.productFeatures.map{ case (id, factor) =>
val factorVector = new DoubleMatrix(factor)
val sim = cosineSimilarity(factorVector, itemVector)
(id,sim)
}
然后取得前10个:
val sortedSims = sims.top(K)(Ordering.by[(Int, Double), Double]{
case(id, similarity) => similarity
})
println(sortedSims.take(10).mkString("\n"))
结果如下:
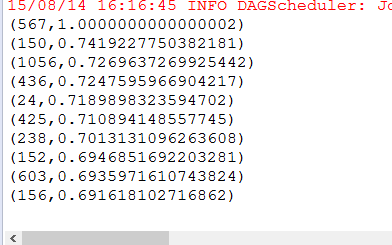
现在来看看电影名字:
val sortedSims2 = sims.top(K+1)(Ordering.by[(Int, Double), Double]{
case(id, similarity) => similarity
})
println(sortedSims2.slice(1, 11).map{case (id, sim) => (titles(id), sim)}.mkString("\n"))
结果如下:
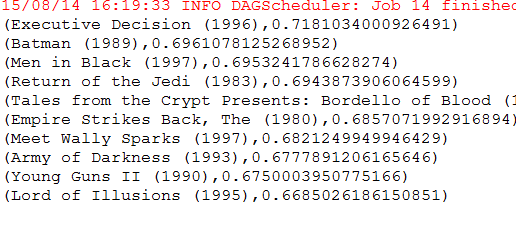















 8916
8916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









