










此笔记为本人在阅读Machine Learning With Spark的时候所做的,笔记有翻译不准确或错误的地方欢迎大家指正。
Spark集群
Spark集群由两种进程组成:一个驱动程序和多个执行程序。在本地模式下,所有的进程都在同一个Java虚拟机中运行。在集群上,这些进程则通常在多个节点上运行。
比如,在单机环境下运行的集群有以下特征:
1、一个主节点作为spark单机模式的主进程和驱动程序。
2、一系列工作节点,每一个作为执行进程。
Spark编程模型
SparkContext
SparkContext(Java中的JavaSparkContext)是spark编写程序的出发点,SparkContext由SparkConf对象的实例初始化,它包含了一系列spark集群的配置信息,比如主节点的URL。
一旦被初始化,我们可以使用一系列的SparkContext对象内置的方法、操作分布式数据集和全局变量。
SparkShell
Spark shell负责上下文的初始化工作
本地模式下Scala创建上下文的例子:
val conf = new SparkConf().setAppNme("Test Spark App").setMaster("local[4]")
val sc = new SparkContext(conf)这在本地模式下创建了一个4线程的上下文,名字是Test Spark App。
Spark Shell
在Spark根目录下输入:./bin/spark-shell就能启动spark shell,如下图:
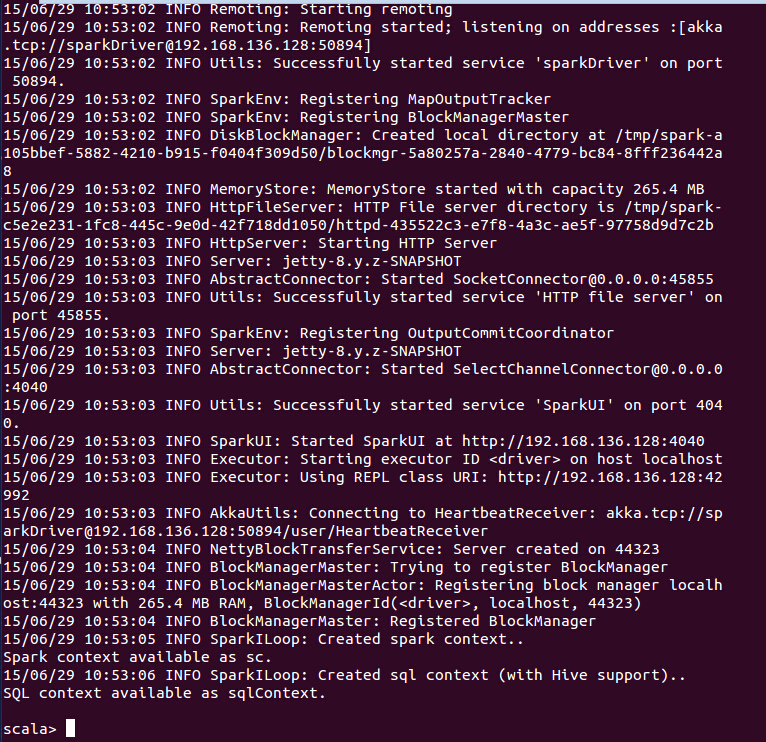
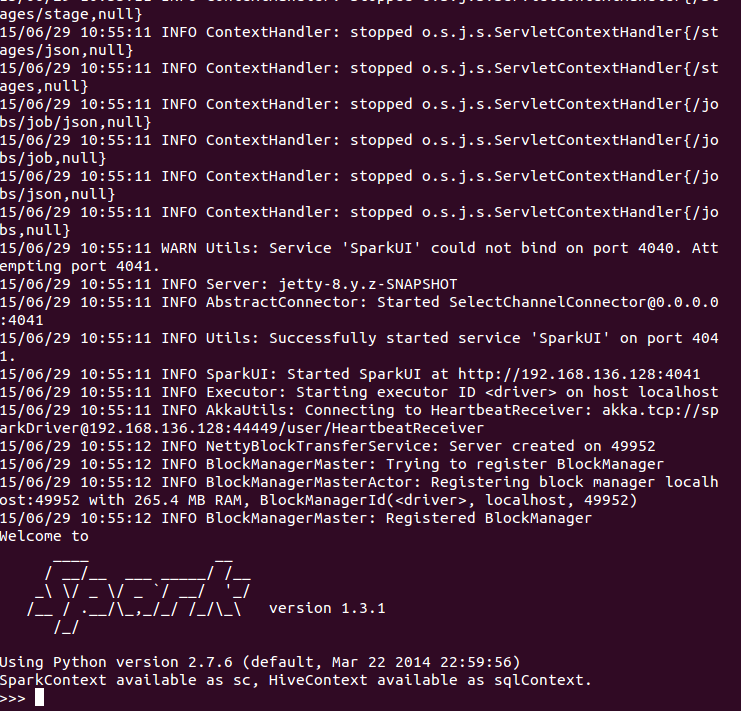
如果想在spark中使用Python shell,那么输入./bin/pyspark,如下图:
Resilient Distributed Datasets(RDD,弹性分布式数据集)
RDD是一系列记录的集合,严格来说,是某一类型的对象,以分布式或者分段的方式分布在集群的诸多节点上。
Spark中的RDD具有容错性,如果一个节点或者任务(task)运行失败了,比如硬件故障,通讯丢失等,除了不正确的操作,RDD能够在剩下的节点上自动重建,将这个任务(job)完成。
创建RDD
RDD可以通过集合创建,如下:
val collection = List("a","b","c","d","e")
val rddFromCollection = sc.parallelize(collection)RDD同样可以通过基于的Hadoop输入源创建,包括本地文件系统,HDFS等。
基于Hadoop的RDD可以利用任何实现了Hadoop InputFormat接口的数据格式,包括文本文件,其他Hadoop标准格式,HBase,Cassandra等。从本地文本文件创建如下:
val rddFromTextFile = sc.textFile("LICENSE")Spark操作
一旦我们创建了一个RDD,我们就得到了一个可操作的分布式数据集。在spark编程模式下,操作分为转换(transformations)和动作(actions)。大体来说,转换对数据集提供了一些转变数据的方法。动作则会进行一些计算或者聚合,然后把结果返回到SparkContext运行的驱动程序中。
Spark中最常见的操作是map,将输入映射成另一种形式的输出,如下:
val intsFromStringRDD = rddFromTextFile.map(line => line.size)=>的左边是输入,右边是输出。
通常情况下,除了多数动作(actions)外,spark操作会返回一个新的RDD,所以我们可以把操作串起来,这样可以使得程序简单明了,比如:
val aveLengthOfRecordChained = rddFromTextFile.map(line => line.size).
sum / rddFromTextFile.countSpark的转换是lazy模式,在调用一个转换方法的时候并不会立即触发计算,而是将转换操作串在一起,在动作(action)被调用的时候才触发计算,这样spark可以更高效的返回结果给驱动程序,所以大多数操作都是以并行的方式在集群上运行。
这意味着,在spark程序中如果没有调用action,那么它永远不会触发实际的操作,也不会返回任何结果。
缓存RDD
Spark一个非常强大的功能是能够在集群中将数据缓存在内存中,可以通过调用cache方法来实现。
调用cache方法会告诉spark要把RDD保存在内存中,第一次调用action的时候,会初始化计算,从数据源读取数据并将它存入内存中。所以,这样的操作第一次被调用的时候,所花费的时间大部分取决于从数据源读取数据的时间。然后这部分数据第二次被访问的时候,比如机器学习中分析、迭代所用到的查询,着部分数据可以直接从内存中读取,因此避免了费时的I/O操作,提高了计算速度
广播变量(broadcast variables)和累加器(accumulators)
另一个Spark的核心功能是可以创建两种类型的变量:广播变量和累加器。
广播变量是只读变量,让SparkContext对象所在的驱动程序上的变量可以传到节点上进行计算。
在需要有效地将通一个数据变量传到其他工作节点(worker nodes)上的情况下,这很有用,比如机器学习算法。在spark中,创建一个广播变量和在SparkContext中调用一个方法一样简单,如下:
val broadcastAList = sc.broadcast(List("a", "b", "c", "d", "e"))累加器也是一种可以广播给工作节点的变量,与广播变量不同的是广播变量是只读变量,而累加器可以在上面添加,这会有局限性:添加操作必须是联合操作,这样全局累加值可以正确地并行计算然后返回给驱动程序。每个工作节点只能访问并且添加它自己本地的累加器变量,并且只有驱动程序可以访问全局变量。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









