







- 卷积后的pool层特征既可以用于类别判别,也可以用于回归BoundingBox,可以这样想,object的外围存在着一个看不见的BoundingBox, 只要人为提供了真值,那么网络就可以学会去调整参数来回归它。这跟利用已有的网络架构提取特征作为自己特定任务领域的初始化参数是一个道理,都是transferlearning的体现。
- 在实际使用中,pool层后增加了一个调整层(convolution,见train.prototxt的rpn_conv/3x3层),将共性特征调整到特定领域特征(BoundingBox)。
- 在特征映射的基础上紧接着的两层如下:
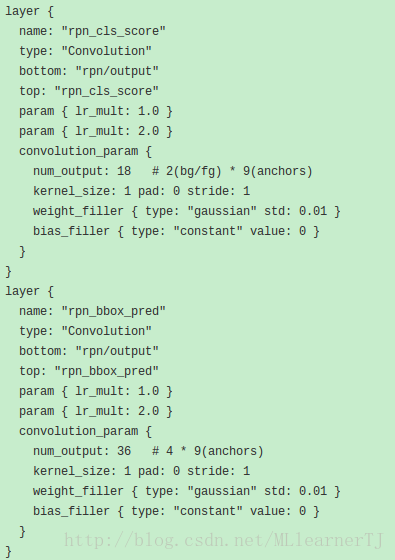
- 第一层预测该像素点属于前景还是背景的概率。该层输出是18,意味着,针对上一层的每一个feature_map(256个或者512个)的每一个像素点,取出其256维的特征,将其映射到一个18(2*9)维的向量,9代表着该位置上的9个anchor,2代表前景or背景。该18维的向量代表的就是针对每一个BoundingBox(或者说是anchor),该像素是它的前景还是背景的概率,毕竟在一个BoundingBox里面是前景,到另一个BoundingBox里面就很可能是背景了。比如猫和桌子重叠了,猫的中心点在猫的小的BBox里面是前景,但是在桌子的大的BBox里面就是背景了。所以这也就是为什么不直接一个像素只维持一个二维向量预测其是前景还是背景的原因所在。而这个地方的前景背景的概率会在计算回归BoundingBox时派上用场,并不是用这个概率去预测属于某一类object的概率(该概率还是按照fast-rcnn中的提取roipooling后的特征去预测的,而这个地方的roi正是从RPN中产生),不要混淆。
- 第二层中每一个像素点输出的是一个36(4*9)维的特征向量,该特征向量中每四个值对应一个anchor的BoundingBox的参数,统一记作t0(文章中定义了3*3共9个固定大小的BoundingBox, 这个地方的参数是相对预定义BoundingBox而言的,是在多个(9)不同ratio不同size的BoundingBox的基础上再来产生相对的偏移和scale缩放的框。即每个像素点可能会同时属于多个BoundingBox,也有可能被class给多个objects)
- 下面是计算BoundingBox的loss的相关层
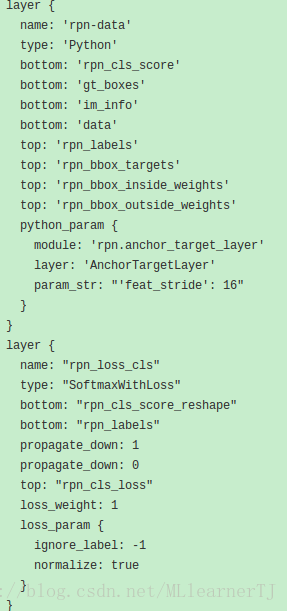
- rpn-data层可以看做是将BoundingBox的真值输入后与预定义的9个不同size和ratio(128×128, 256*256, 512*512,2:1, 1:1, 1:2)的框计算相关转换参数作为输出。注意该层不需要往后传误差,只是在做一个参数转换而已。
- rnp_loss_cls层则是将7中的转换参数与5中输出的转换参数计算SmoothLoss后作为后向传播的误差。
- 详细细节待补。
与region-based方法不同的另一种思路是直接预测(回归)框和类别的概率,比如YOLO, SSD,YOLO-V2,YOLO9000等。SSD与YOLO的区别是增加了多个不同尺度的输出,取消了YOLO的全连接层,从而提升了速度和精度。它们的最后输出都是在feature-map上每一个点产生多组预测集(包含位置和类别预测),直接针对一个balanced-loss-function做训练。而faster-rcnn中实际上是将位置预测的loss和类别预测的loss分开来进行训练了。此外,SSD对于图像的输入大小貌似是没有要求的,因为所有操作都是在特征图上计算,最后的级联层和非极大值抑制也没有对维度特殊的限制。而YOLO由全连接层的限制,faster-rcnn则是通过ROI-Pooling技术,实现了输入大小的任意性。
2017/05/03更新
给别人写的一个简易文档,直接粘贴过来了。
一. 网络结构
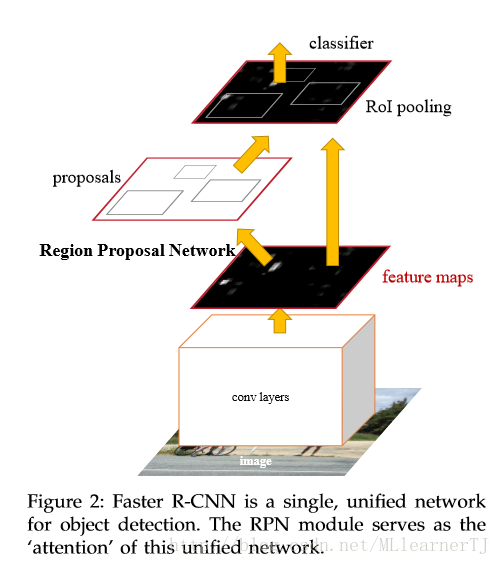
以上是原论文中po出的图,整个网络可以看作由以下三部分构成:
1. 基础卷积网络;
2. 区域生成网络(RPN);
3. 全连接分类和回归精修网络;
更详细的网络结构如下(基础网络是Vgg16):
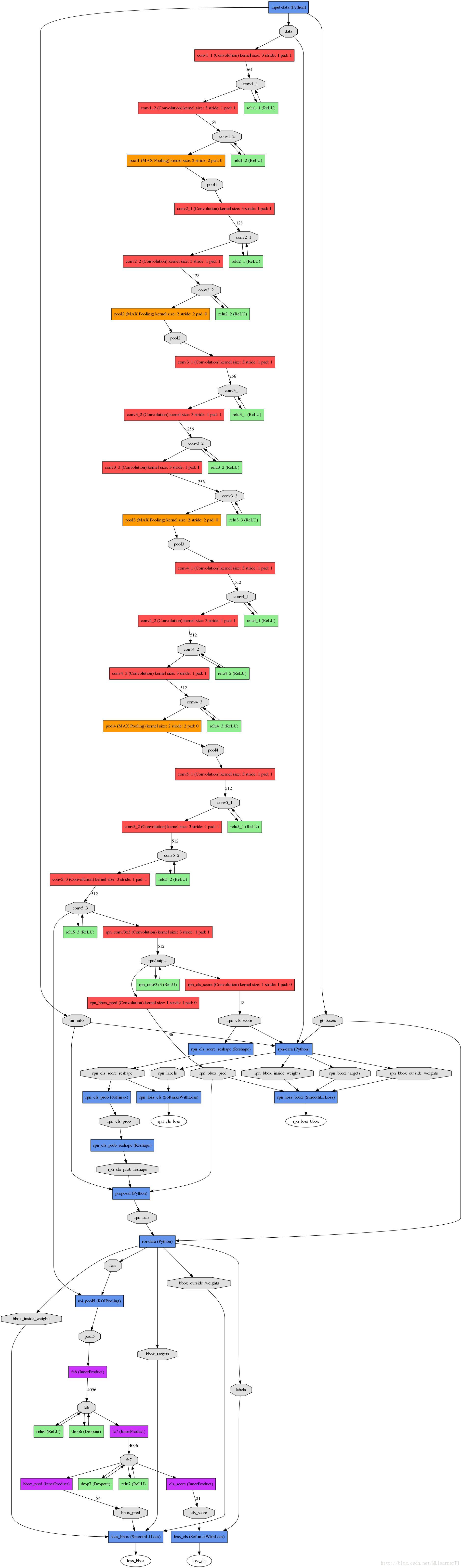
介于第一部分就是一个简单的基础特征提取网络,此处不再赘述,下面我将对2,3部分进行详细的解读。
RPN网络
RPN结构图:
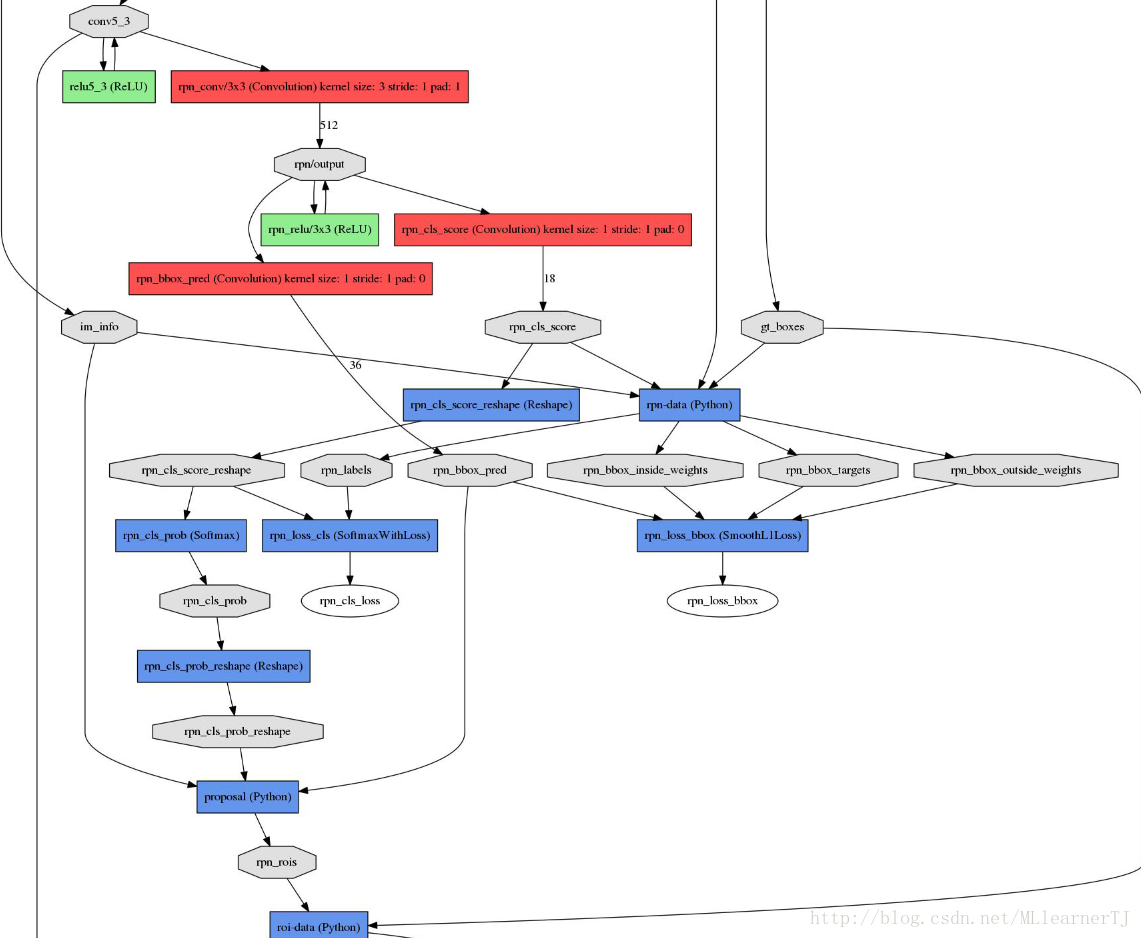
RPN结构说明:
1) 从基础网络提取的第五卷积层特征进入RPN后分为两个分支,其中一个分支进行针对feature map(上图conv-5-3共有512个feature-map)的每一个位置预测共(9*4=36)个参数,其中9代表的是每一个位置预设的9种形状的anchor-box,4对应的是每一个anchor-box的预测值(该预测值表示的是预设anchor-box到ground-truth-box之间的变换参数),上图中指向rpn-bbox-pred层的箭头上面的数字36即是代表了上述的36个参数,所以rpn-bbox-pred层的feature-map数量是36,而每一张feature-map的形状(大小)实际上跟conv5-3一模一样的;
2) 另一分支预测该anchor-box所框定的区域属于前景和背景的概率(网上很对博客说的是,指代该点属于前景背景的概率,那样是不对的,不然怎么会有18个feature-map输出呢?否则2个就足够了),前景背景的真值给定是根据当前像素(anchor-box中心)是否在ground-truth-box内;
3) 上图RPN-data(python)运算框内所进行的操作是读取图像信息(原始宽高),groun-truth boxes的信息(bounding-box的位置,形状,类别)等,作好相应的转换,输入到下面的层当中。
4) 要注意的是RPN内部有两个loss层,一个是BBox的loss,该loss通过减小ground-truth-box与预测的anchor-box之间的差异来进行参数学习,从而使RPN网络中的权重能够学习到预测box的能力。实现细节是每一个位置的anchor-box与ground-truth里面的box进行比较,选择IOU最大的一个作为该anchor-box的真值,若没有,则将之class设为背景(概率值0,否则1),这样背景的anchor-box的损失函数中每个box乘以其class的概率后就不会对bbox的损失函数造成影响。另一个loss是class-loss,该处的loss是指代的前景背景并不是实际的框中物体类别,它的存在可以使得在最后生成roi时能快速过滤掉预测值是背景的box。也可实现bbox的预测函数不受影响,使得anchor-box能(专注于)正确的学习前景框的预测,正如前所述。所以,综合来讲,整个RPN的作用就是替代了以前的selective-search方法,因为网络内的运算都是可GPU加速的,所以一下子提升了ROI生成的速度。可以将RPN理解为一个预测前景背景,并将前景框定的一个网络,并进行单独的训练,实际上论文里面就有一个分阶段训练的训练策略,实际上就是这个原因。
5) 最后经过非极大值抑制,RPN层产生的输出是一系列的ROI-data,它通过ROI的相对映射关系,将conv5-3中的特征已经存入ROI-data中,以供后面的分类网使用。
另外两个loss层的说明:
也许你注意到了,最后还有两个loss层,这里的class-loss指代的不再是前景背景loss,而是真正的类别loss了,这个应该就很好理解了。而bbox-loss则是因为rpn提取的只是前景背景的预测,往往很粗糙,这里其实是通过ROI-pooling后加上两层全连接实现更精细的box修正(这里其实是我猜的)。
ROI-Pooing的作用是为了将不同大小的Roi映射(重采样)成统一的大小输入到全连接层去。
以上。
参考:
[1] https://arxiv.org/pdf/1506.01497.pdf
[2] https://github.com/rbgirshick/py-faster-rcnn














 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









